Note both marginals computed from the joint are consistent with our initial marginals.
iClicker Question
Answer TRUE or FALSE:
We obtain a marginal distribution by summing the rows of a joint distribution; therefore, each row of a joint distribution must sum to 1.
A. TRUE
B. FALSE
2. Independence and Dependence Concepts
A big part of Data Science is about harvesting the relationship between the variables in our datasets.
2.1. Independence
Let \(X\) and \(Y\) be two random variables.
\(X\) and \(Y\) are independent if knowing something about one of them tells us nothing about the other: \[P(X = x \cap Y = y) = P(X = x) \cdot P(Y = y).\]
We would only need the marginals to obtain their joint distribution.
Going back to the two coins!
Recall we had this joint distribution:
\[\begin{gather*}
X = \text{First coin's outcome.} \\
Y = \text{Second coin's outcome.}
\end{gather*}\]
\(X/Y\)
\(\texttt{H}\)
\(\texttt{T}\)
\(\texttt{H}\)
0.25
0.25
\(\texttt{T}\)
0.25
0.25
Obtaining the Marginals from the Joint
We can see that the two coin flips are independent:
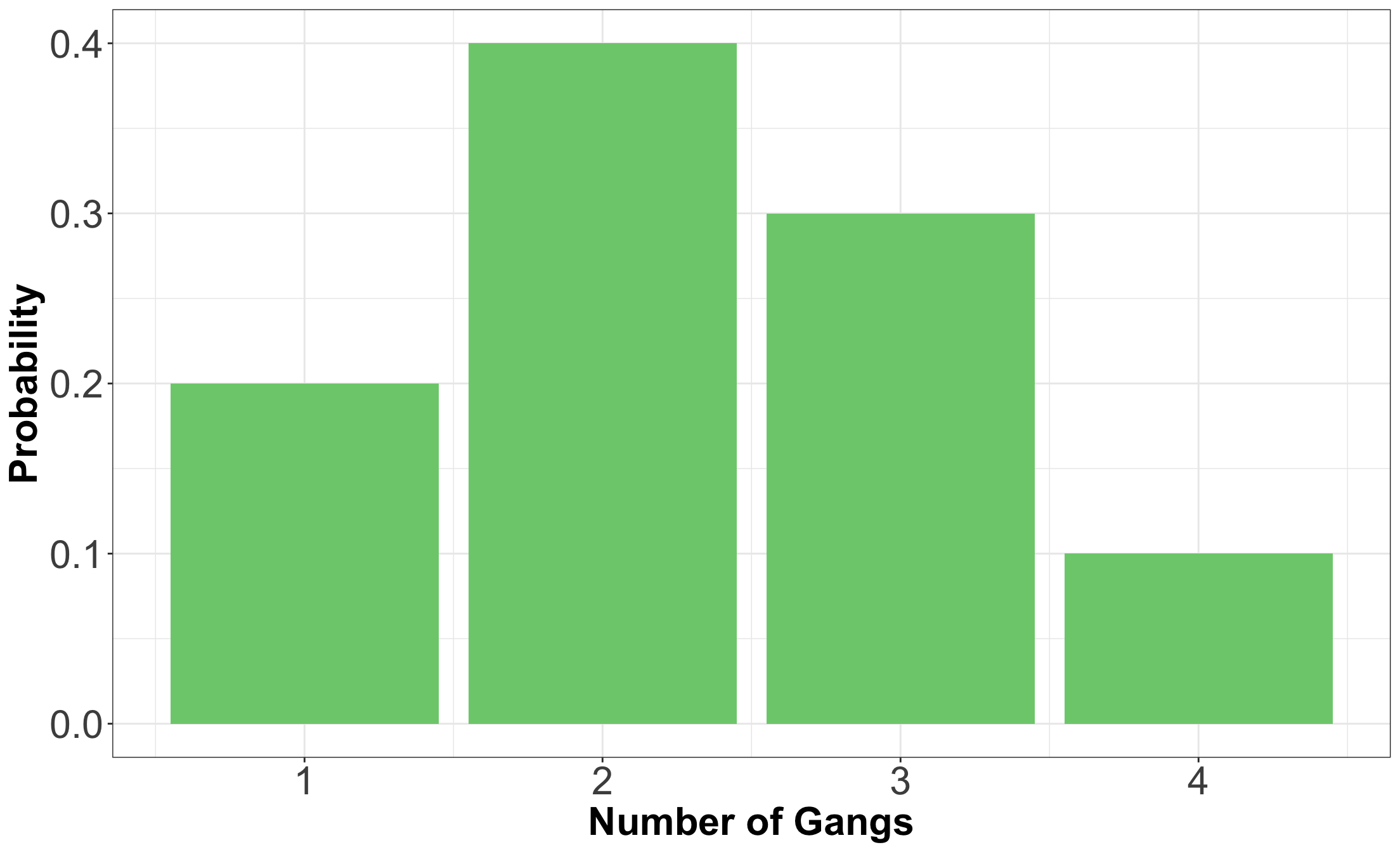
Indeed, we can see that the covariance between \(\text{LOS}\) and \(\text{Gangs}\) is negative.
A negative sign indicates that an increase in \(\text{LOS}\) is associated with a decrease in \(\text{Gangs}\).
Covariance Drawback
This measure depends on the spread of the random variables \(X\) and \(Y\).
For instance, if we multiply \(X\) by 10, then the covariance of \(X\) and \(Y\) increases by a factor of 10 as well: \[\begin{align*}
\operatorname{Cov}(10X,Y) &= \mathbb{E}(10XY) - \mathbb{E}(10X) \mathbb{E}(Y) \\
&= 10\mathbb{E}(XY) - 10\mathbb{E}(X)\mathbb{E}(Y) \\
&= 10[\mathbb{E}(XY) - \mathbb{E}(X) \mathbb{E}(Y)] \\
&= 10\operatorname{Cov}(X,Y).
\end{align*}\]
Pearson’s Correlation
Pearson’s correlation standardizes the distances according to the standard deviations \(\sigma_X\) and \(\sigma_Y\) of \(X\) and \(Y\), respectively. \[\begin{align*}
\operatorname{Corr}(X, Y) &= \mathbb{E} \left[
\left(\frac{X-\mu_X}{\sigma_X}\right)
\left(\frac{Y-\mu_Y}{\sigma_Y}\right)
\right] \\
&= \frac{\operatorname{Cov}(X, Y)}{\sqrt{\operatorname{Var}(X)\operatorname{Var}(Y)}}.
\end{align*}\]
It turns out that \(-1 \leq \text{Corr}(X, Y) \leq 1\).
Pearson’s Correlation Scale
\(-1\) means a perfect negative linear relationship between \(X\) and \(Y\).
\(0\) means no linear relationship (however, this does not mean independence!).
\(1\) means a perfect positive linear relationship.
iClicker Question
Answer TRUE or FALSE:
Covariance can be negative, but not the variance.
A. TRUE
B. FALSE
iClicker Question
Answer TRUE or FALSE:
Without any further assumptions between random variables \(X\) and \(Y\), covariance is calculated as
Computing \(\mathbb{E}(XY)\) requires the joint distribution, but computing \(\mathbb{E}(X) \mathbb{E}(Y)\) only requires the marginals.
A. TRUE
B. FALSE
2.2.2. Kendall’s \(\tau_K\)
Pearson’s correlation measures linear dependence.
This might be a big downfall, since many relationships between real-world variables are not linear.
Hence, there is an alternative measure called Kendall’s \(\tau_K\).
Characteristics of Kendall’s \(\tau_K\)
Kendall’s \(\tau_K\) can measure non-linear dependence.
It measures concordance between each pair of observations \((x_i, y_i)\) and \((x_j, y_j)\) with \(i \neq j\):
Concordant means \[\begin{gather*}
x_i < x_j \quad \text{and} \quad y_i < y_j, \\
\text{or} \\
x_i > x_j \quad \text{and} \quad y_i > y_j;
\end{gather*}\] which gets a positive sign.
Characteristics of Kendall’s \(\tau_K\)
Discordant means \[\begin{gather*}
x_i < x_j \quad \text{and} \quad y_i > y_j, \\
\text{or} \\
x_i > x_j \quad \text{and} \quad y_i < y_j;
\end{gather*}\] which gets a negative sign.
Formal Definition
Kendall’s \(\tau_K\)averages the amount of concordance and discordance by taking the difference between the number of concordant and number of discordant pairs.
The formal definition with \(n\) data pairs is
\[\tau_K = \frac{\text{Number of concordant pairs} - \text{Number of discordant pairs}}{{n \choose 2}}.\]
Kendall’s \(\tau_K\) is between -1 and 1, and measures dependence’s strength (and direction).
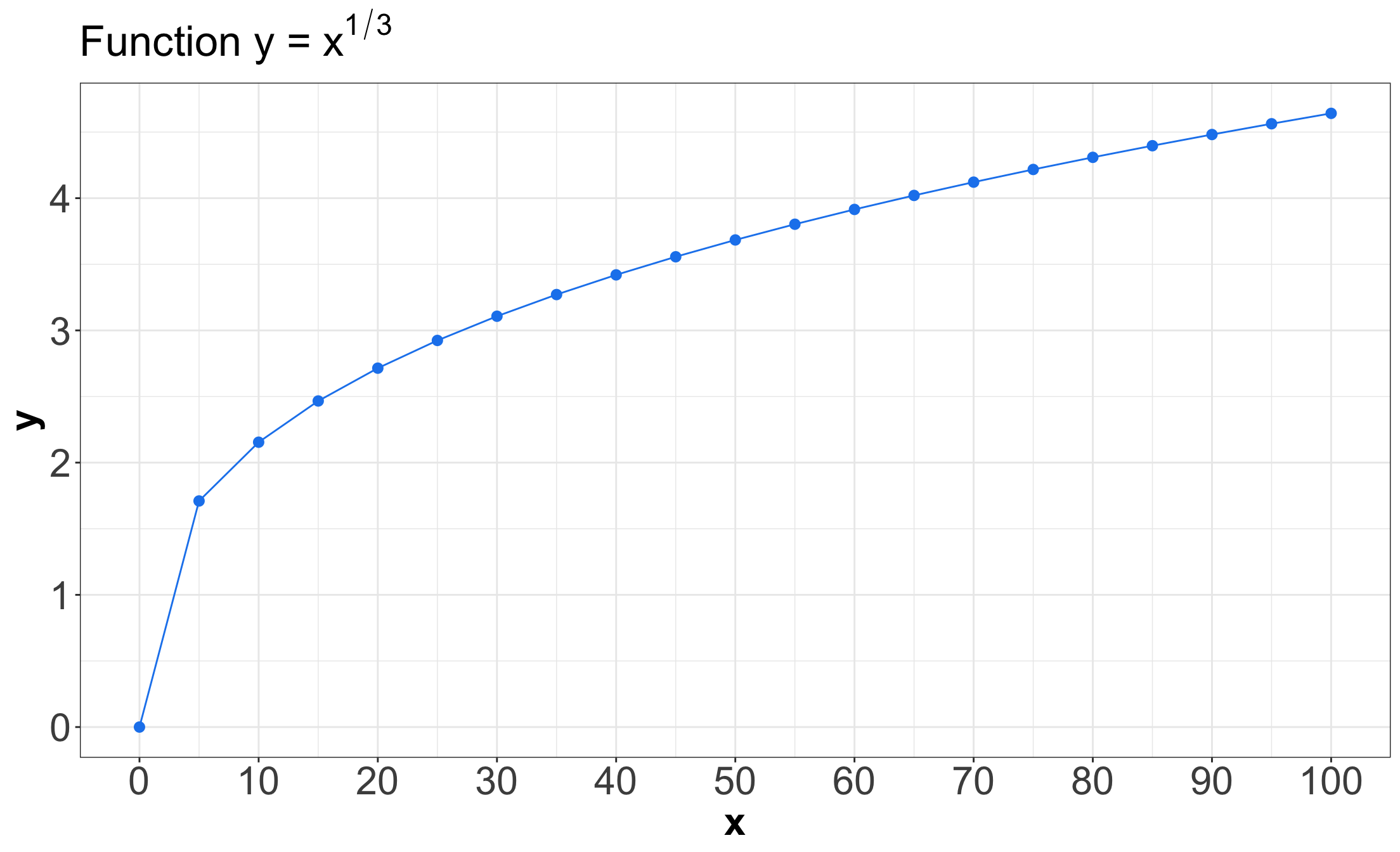
First Example
Consider the two correlation measures: Pearson and Kendall’s \(\tau_K\).
We will hypothetical dataset called non_linear_function with \(n = 21\) where: \[y = x^{1/3}.\]