sample_n30 <- tibble(values = c(
24.9458614574341, 7.23174970992907, 4.16136401519179, 5.60304128237143,
5.37929488345981, 1.40547217217847, 7.0701988485075, 2.84055356831115,
0.894746121019125, 2.9016381111011, 3.19011222943664, 11.0930137682099,
3.49700326472521, 46.2914818498428, 2.00653892990149, 2.87363994969391,
11.4050390862658, 11.6616687767937, 12.8855835341646, 3.88483320176601,
0.406148910522461, 25.7642258988289, 8.4743227359272, 4.17410666868091,
1.84968510270119, 2.15972620035141, 10.5289600339151, 6.44162824716339,
10.6035323139645, 66.6861112673485
))Maximum Likelihood Estimation
Lecture 7
Moving on beyond probability (slightly)!
- Today’s topic is a fascinating statistical concept: estimating distributional parameters in a population or system using sample data.
- We will focus on maximum likelihood estimation (MLE).

A Note on Plotting
- You will not be expected to make plots like those in these lecture notes.
- We will save that for the next block in DSCI 531: Data Visualization I.

1. Random Samples
A random sample is a collection of \(n\) random outcomes/variables.
Using mathematical notation, a random sample of size \(n\) is usually depicted with random variables \(X_1, \ldots, X_n\).
We think of data as being a random sample.

Independent and identically distributed!
- Unless we make additional sampling assumptions, a default random sample is said to be independent and identically distributed (or iid) if:
- Each pair of observations are independent, and
- each observation comes from the same distribution.
Why is sampling important in statistical practice?
- Populations or systems of interest are governed by fixed parameters (under a frequentist paradigm).
- Data from these populations or systems of interest can be modelled via diverse discrete and/or continuous distributions.
- These parameters are considered to be the true ones.
Estimation!
- We will never know these true parameters in practice, but we aim to estimate them via sampled data.
- Using our observed sampled data, we can perform the corresponding parameter estimation via MLE (for instance!) and then proceed to statistical inference.
For example…
The sample mean:
\[\begin{align} \bar{Y} = \frac{\sum_{i = 1}^n Y_i}{n} \end{align}\]
is a trivial case with a very intuitive answer at first sight.
Still, this answer is backed up with interesting statistical modelling assumptions via MLE.
Important!
- Since the scope of this lecture is mostly about the conceptual understanding of the MLE process regarding distributional parameters, we will narrow down the attention to univariate cases.
- That said, in day-to-day statistical practice, this conceptual understanding can also be extended to multivariate cases for more complex data modelling.

2.1. A first example!
- Suppose we have an empirical distribution of standard deviations of gene expression for different genes.
- This empirical distribution belongs to a random sample of standard deviations.
- We would like to estimate the parameters from the population this sample is coming from!

The plots!
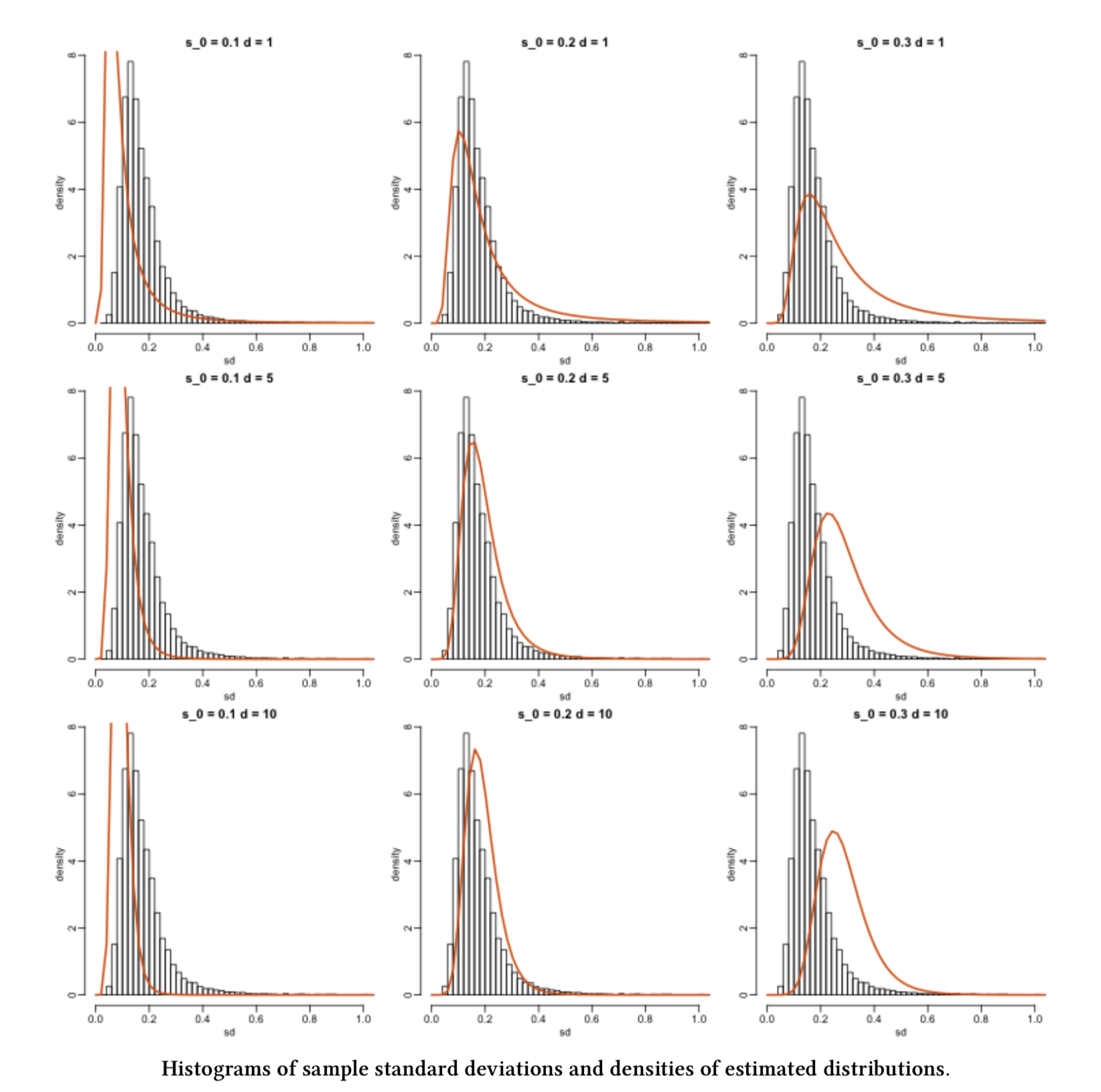
Image from Data Analysis for the Life Sciences (Irizarry and Love, 2016).
3. What is the definition of MLE?
- MLE is a method that, given some observed data and some assumed family of probability distributions, seeks to find values of the parameters that would make the observed data most likely to have occurred.
In our previous example..
- From the histograms, can we do it just by eyeballing it? Not precisely!
- So how can we do this? MLE is one way and it involves, as the name says, finding a maximum likelihood.
3.2. But, what is the likelihood function?

Demand Planning
- Then Operations staff currently requires a realistic estimation of the average wait time from one customer to the next one in any given cart during Summer days in these eight Canadian cities.
- This average wait time would allow them to plan carefully how much stock each cart should have so there will not be any waste or shortage.

Sunny times!
- Summertime represents the most profitable season from a business perspective, thus, solving the time query is a significant priority for your company.
- Hence, you decided to organize a meeting with your eight general managers (one per Canadian city) by last mid-summer.

Urgent Meeting!
- It was first (and wrongly!) discussed to do the following:
Since the operations team has not previously recorded any historical data, ALL vendor staff from 900 carts will start collecting data on the wait time in minutes between each customer this upcoming Summer days of 2026.
Nonetheless…
- Ottawa’s general manager provides a comment for further statistical food for thought:
The operations protocol for recording wait times in the 900 vending carts looks too cumbersome to implement straightforwardly this upcoming Summer. Why don’t we select A SMALLER GROUP of ice cream carts across the eight cities to have a more efficient process implementation that would allow us to optimize operational costs?
The sample data in minutes!
The empirical (sample) distribution!
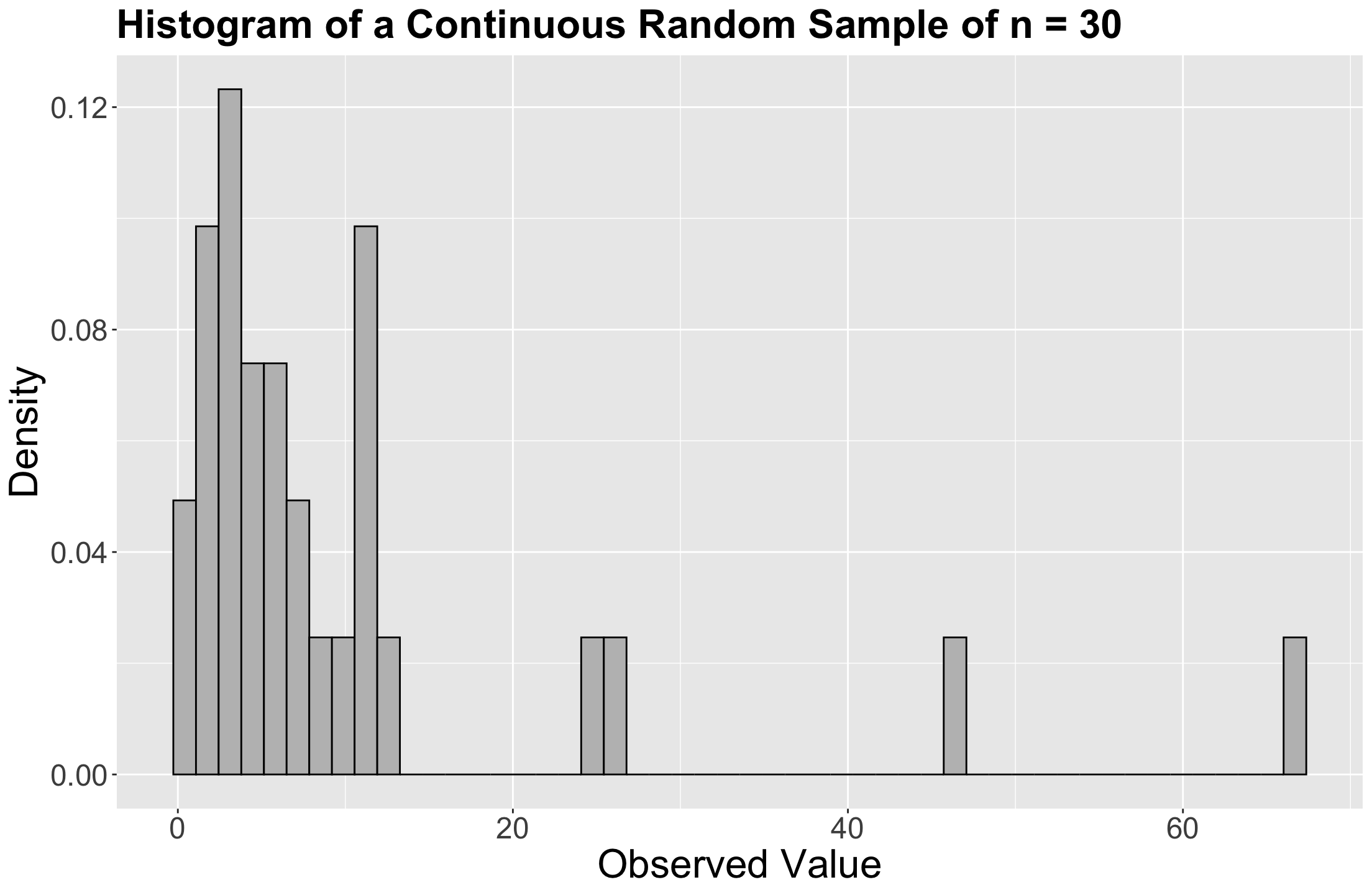
How to model our waiting times?
- The Exponential distribution is a suitable distribution to model our waiting times.
- It is a continuous and non-negative distribution that allows us to model wait times.
- Therefore, we can go ahead with this distribution.

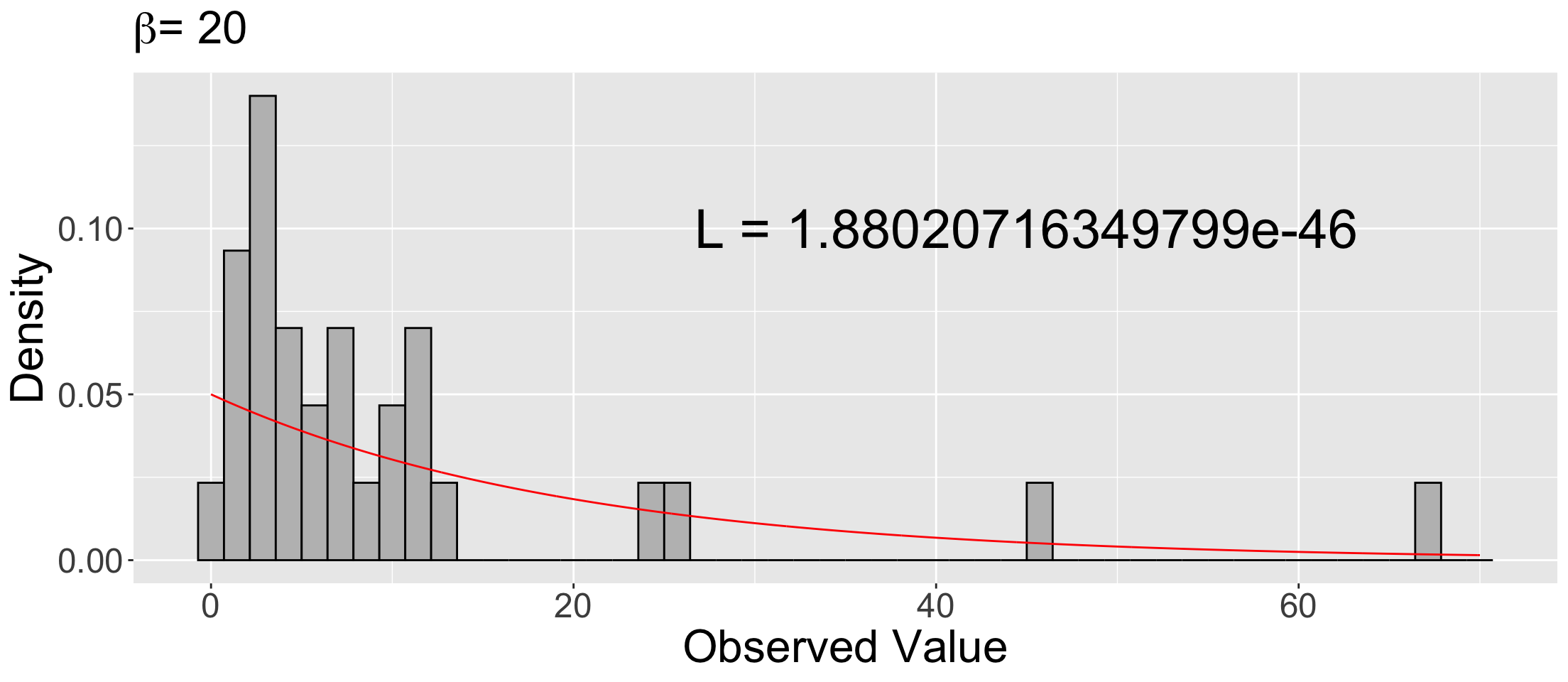
Overlaying density_20 on the sample’s histogram!
- We plot this theoretical density
density_20on top of the empirical (sample) distribution (i.e., the histogram).
Comparing our three theoretical densities and their joint likelihood values!
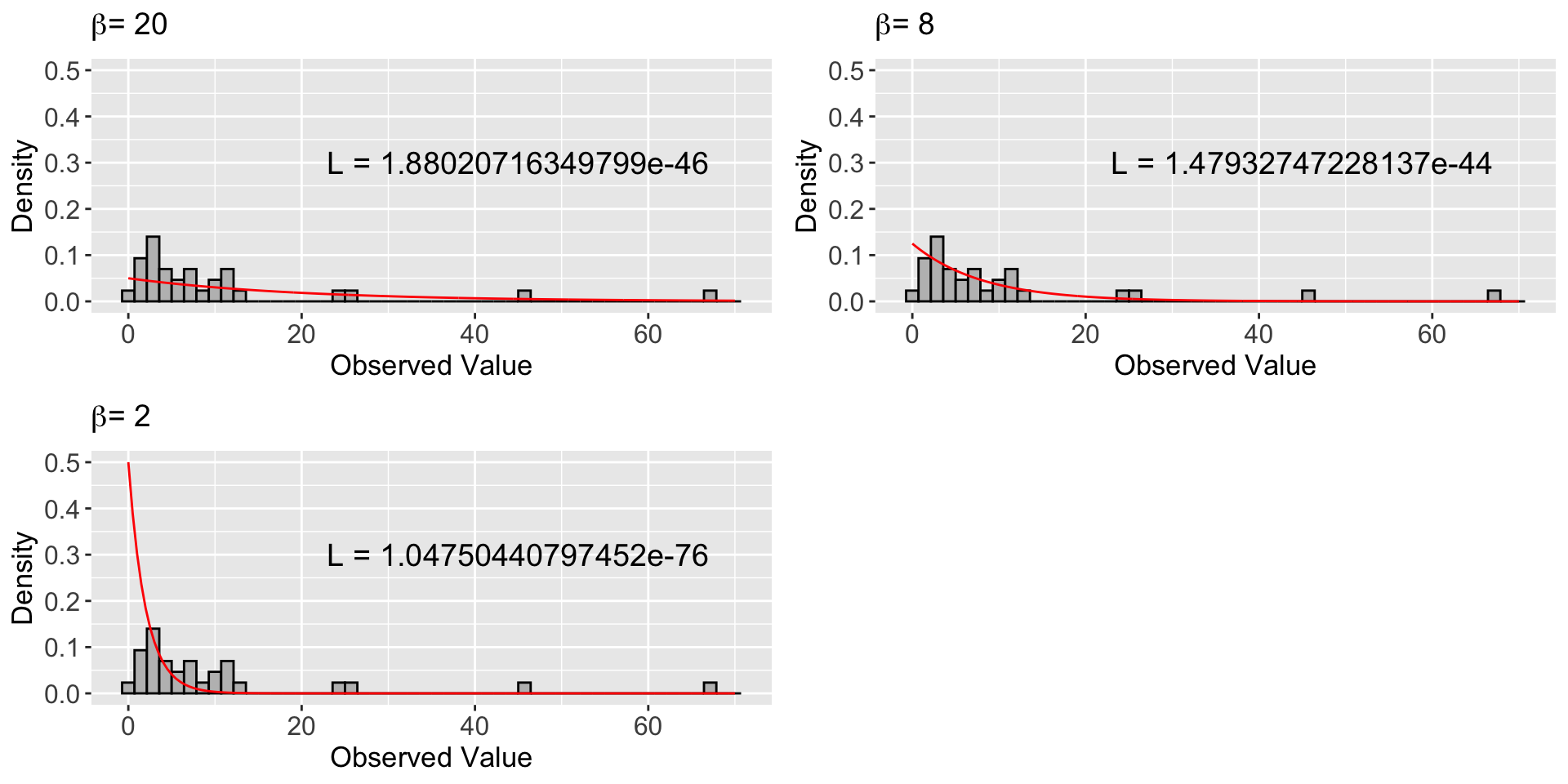
Then …
- We plot the possible \(\beta\)’s against the likelihood and log-likehood of observing them given our data in
sample_n30:
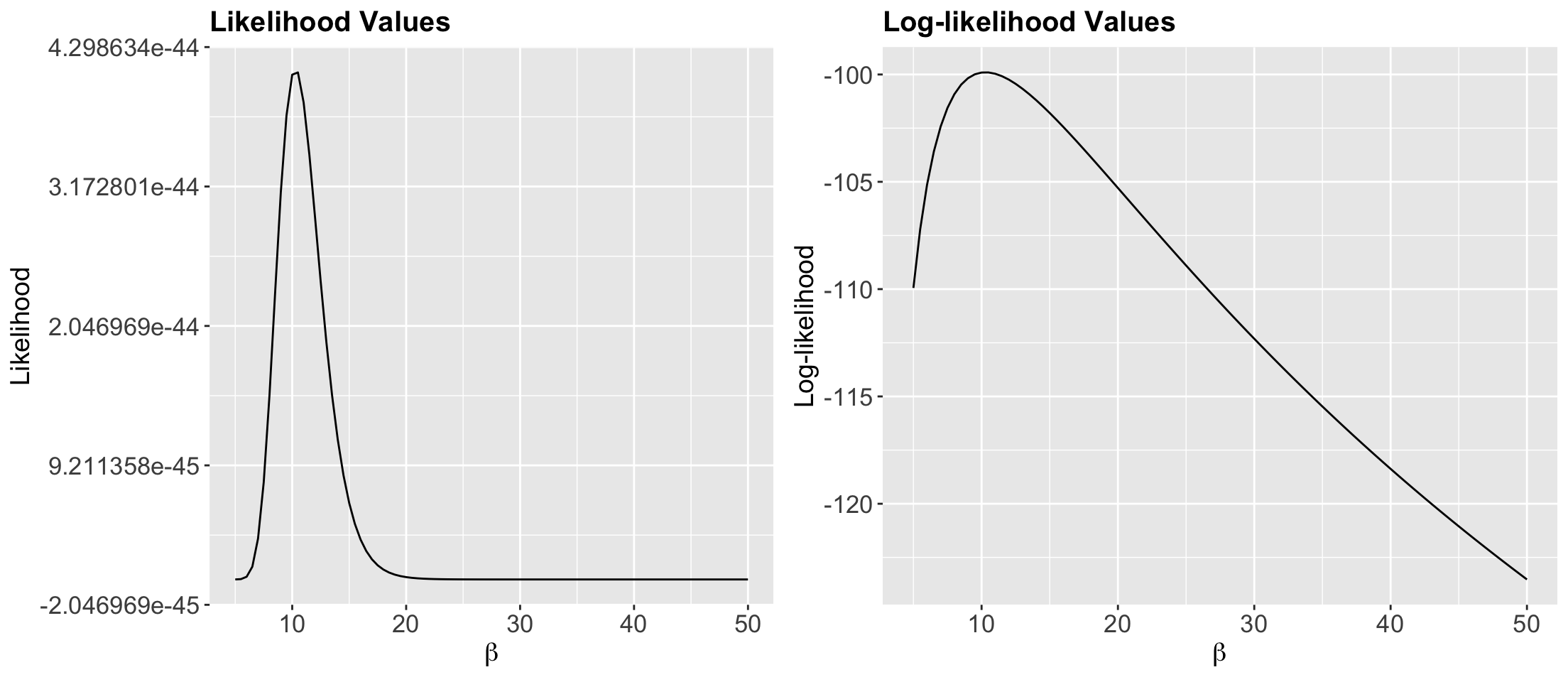
Indicating the empirical MLE of \(\beta\) as a vertical blue line!
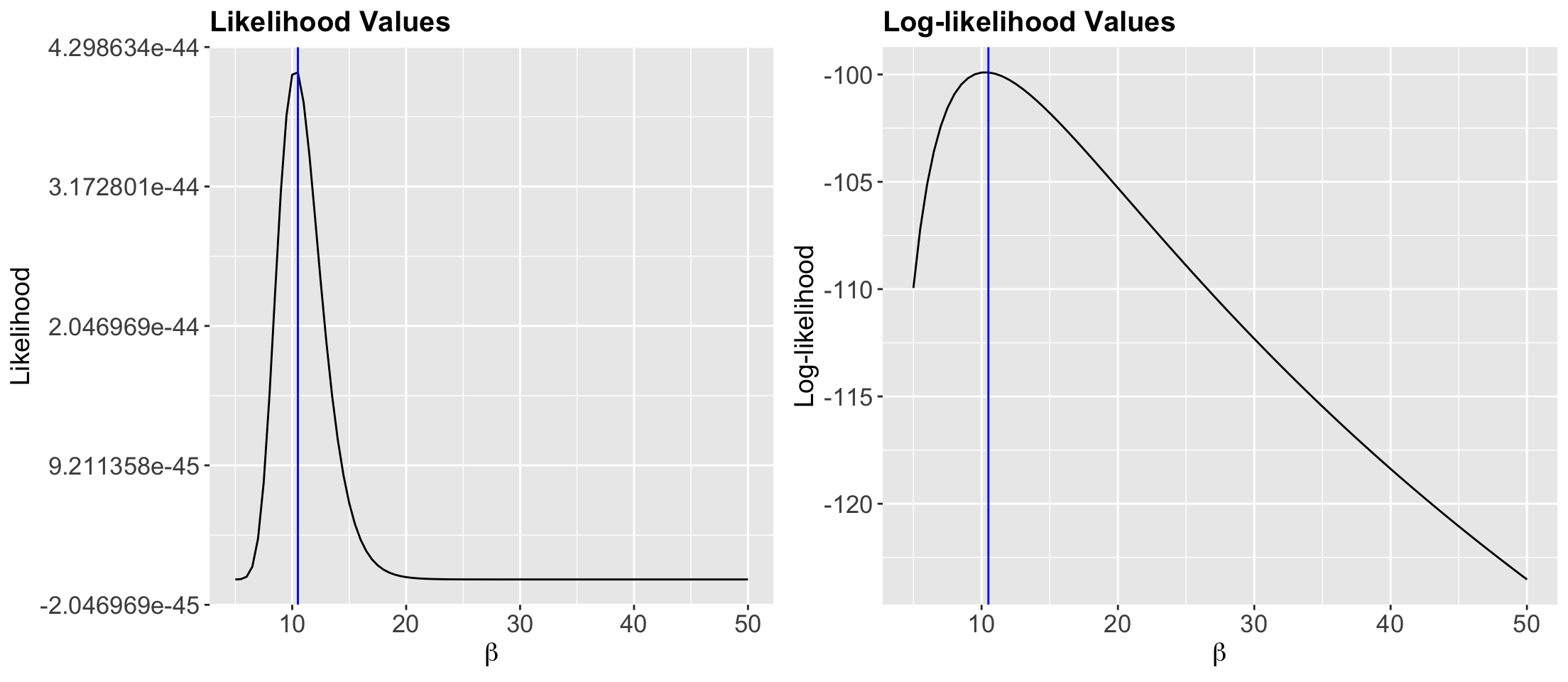
Indeed, we have empirically found a maximum at 10.5 minutes!
Indicating the analytical MLE of \(\beta\) as a vertical red line!
analytical_MLE <- mean(sample_n30$values) # We use the sample mean() function
round(analytical_MLE, 2)[1] 10.28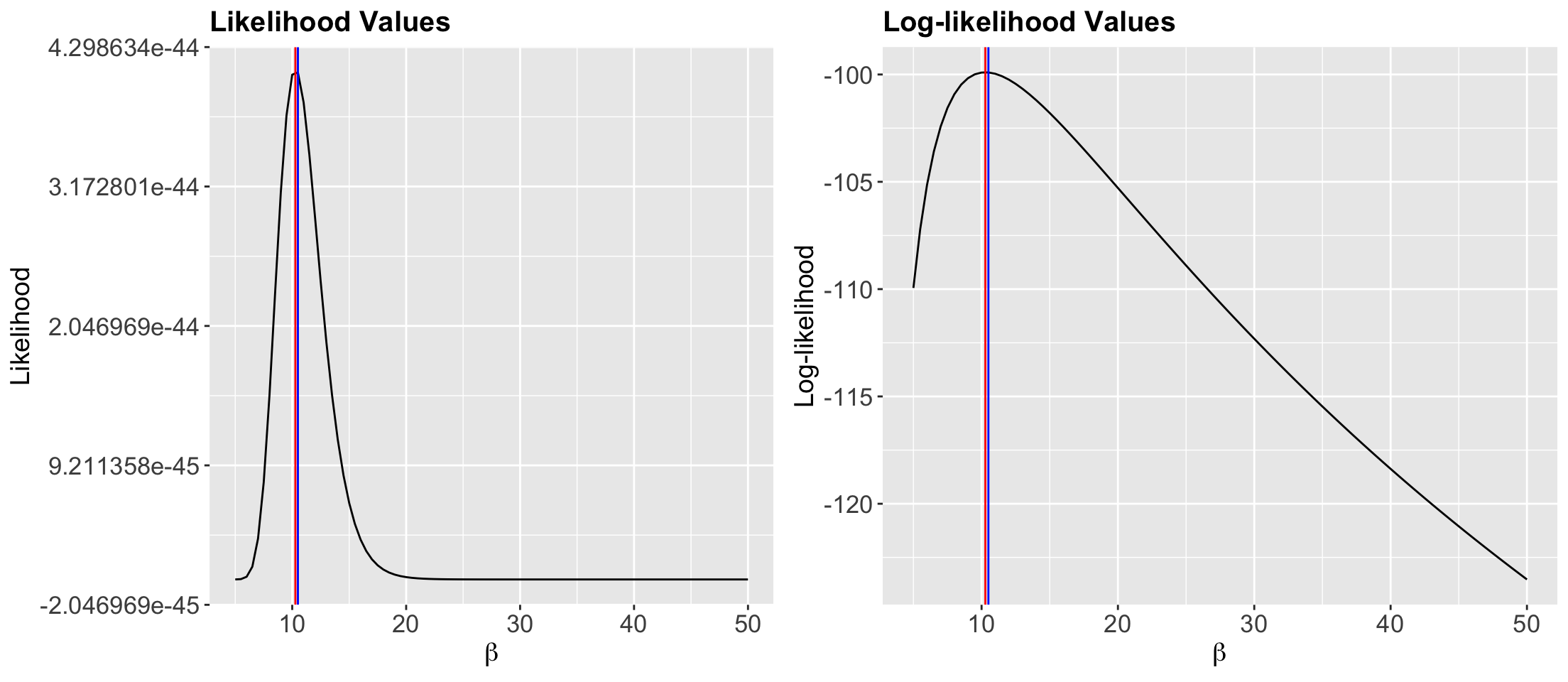
![]()