set.seed(123)
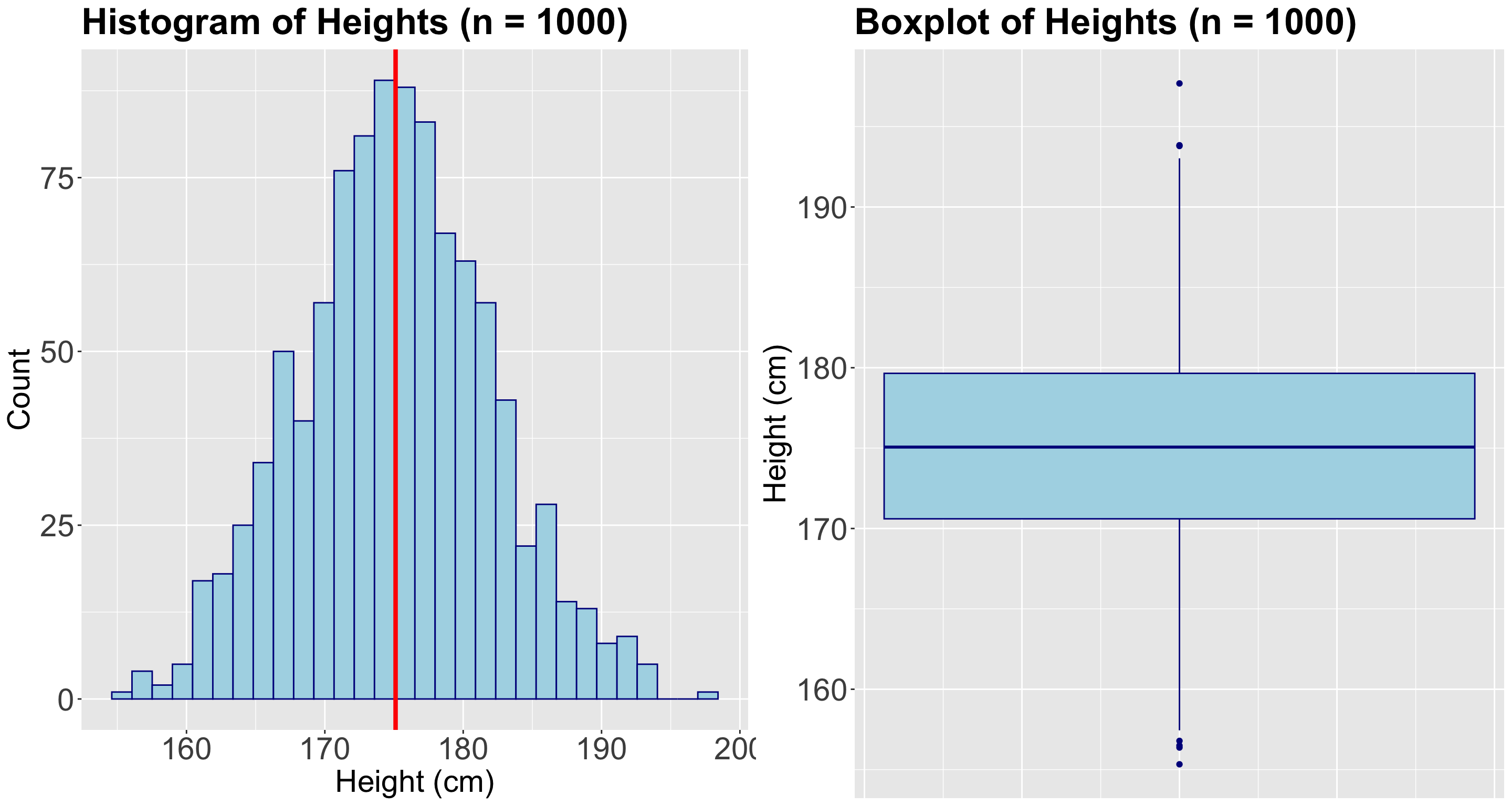
sample_heights <- draw_sample(1000)
sample_mean <- mean(sample_heights)
round(sample_mean,2)[1] 175.11Quantile Regression
summary() and var().
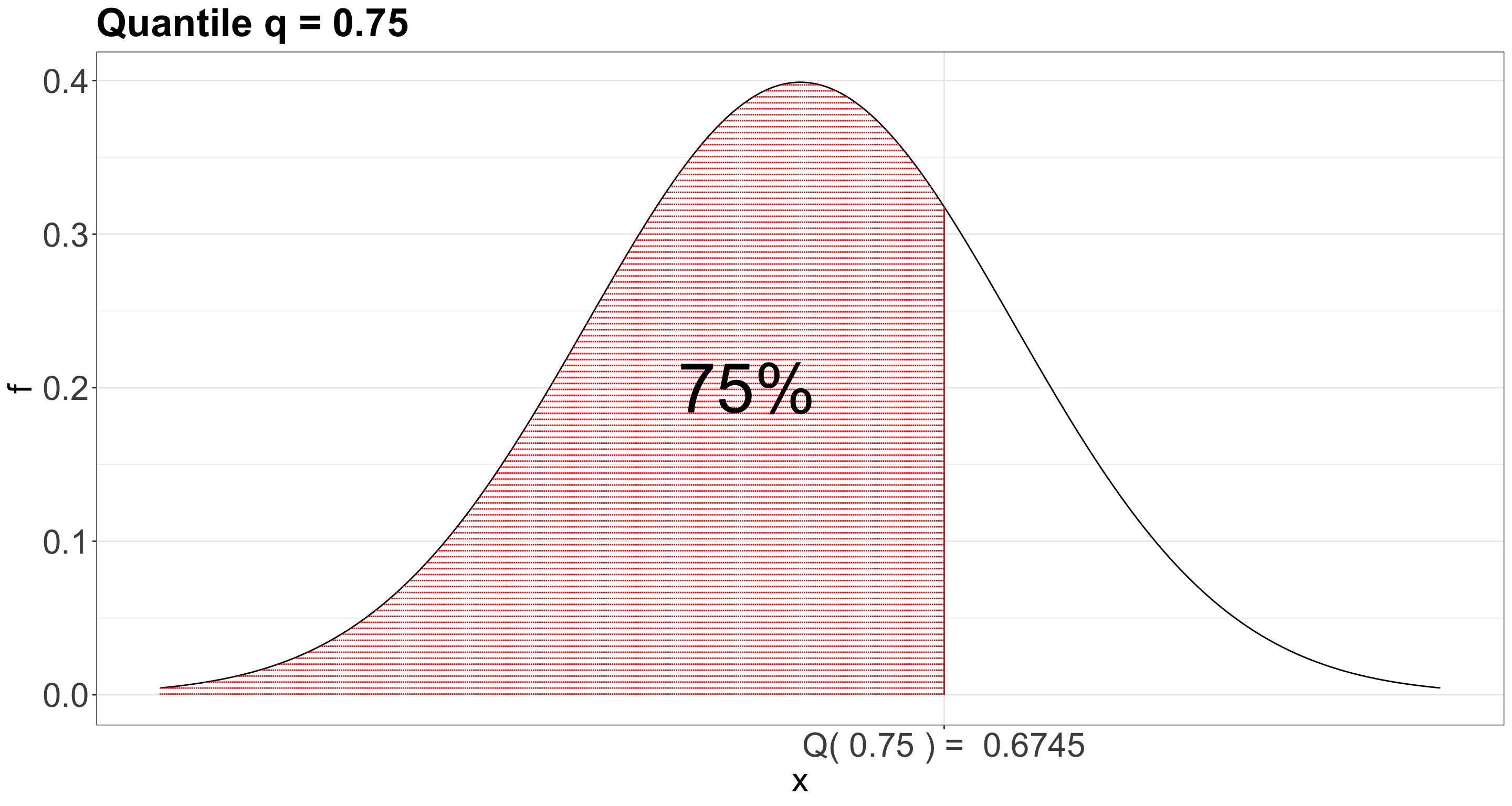
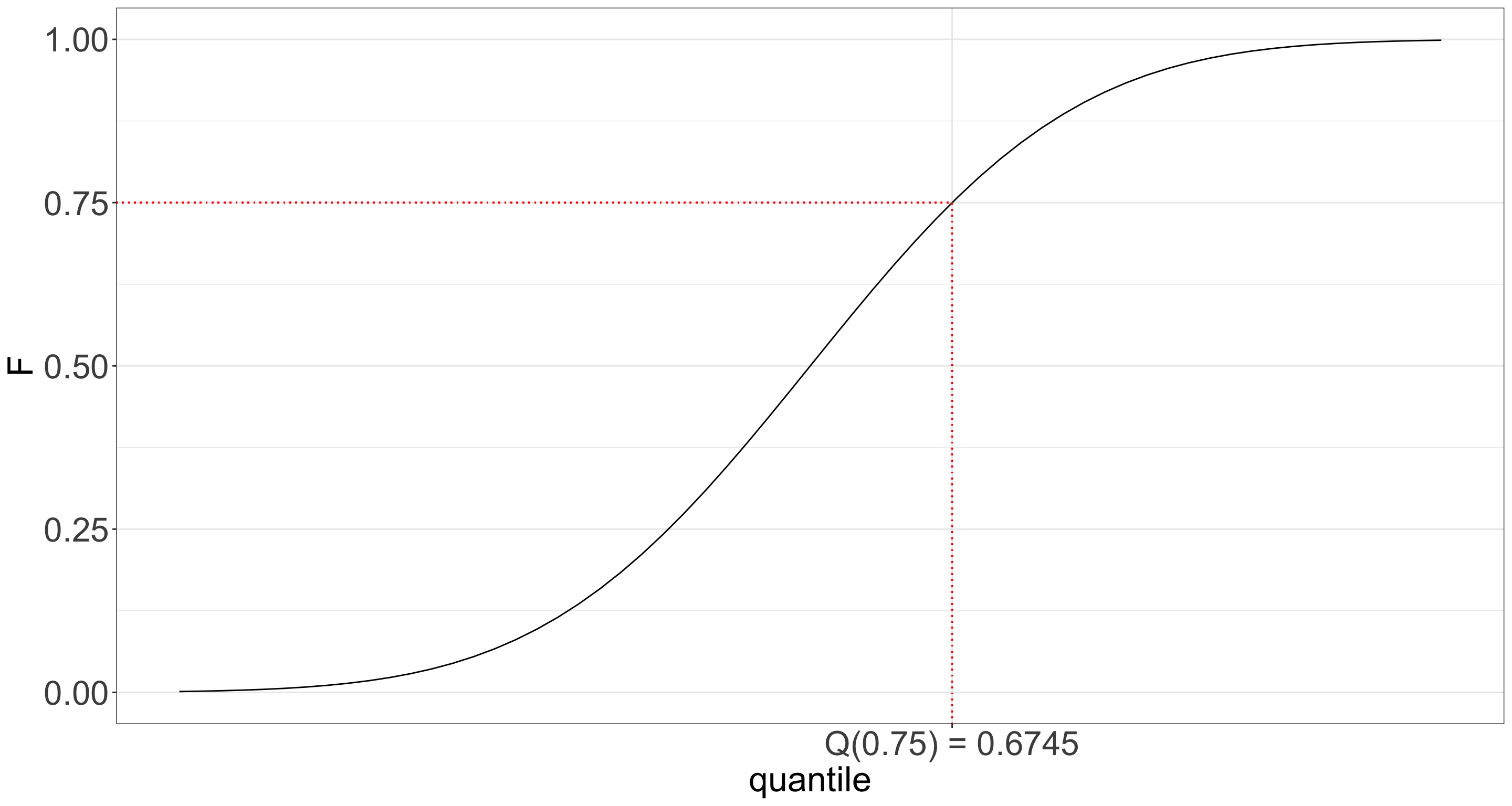
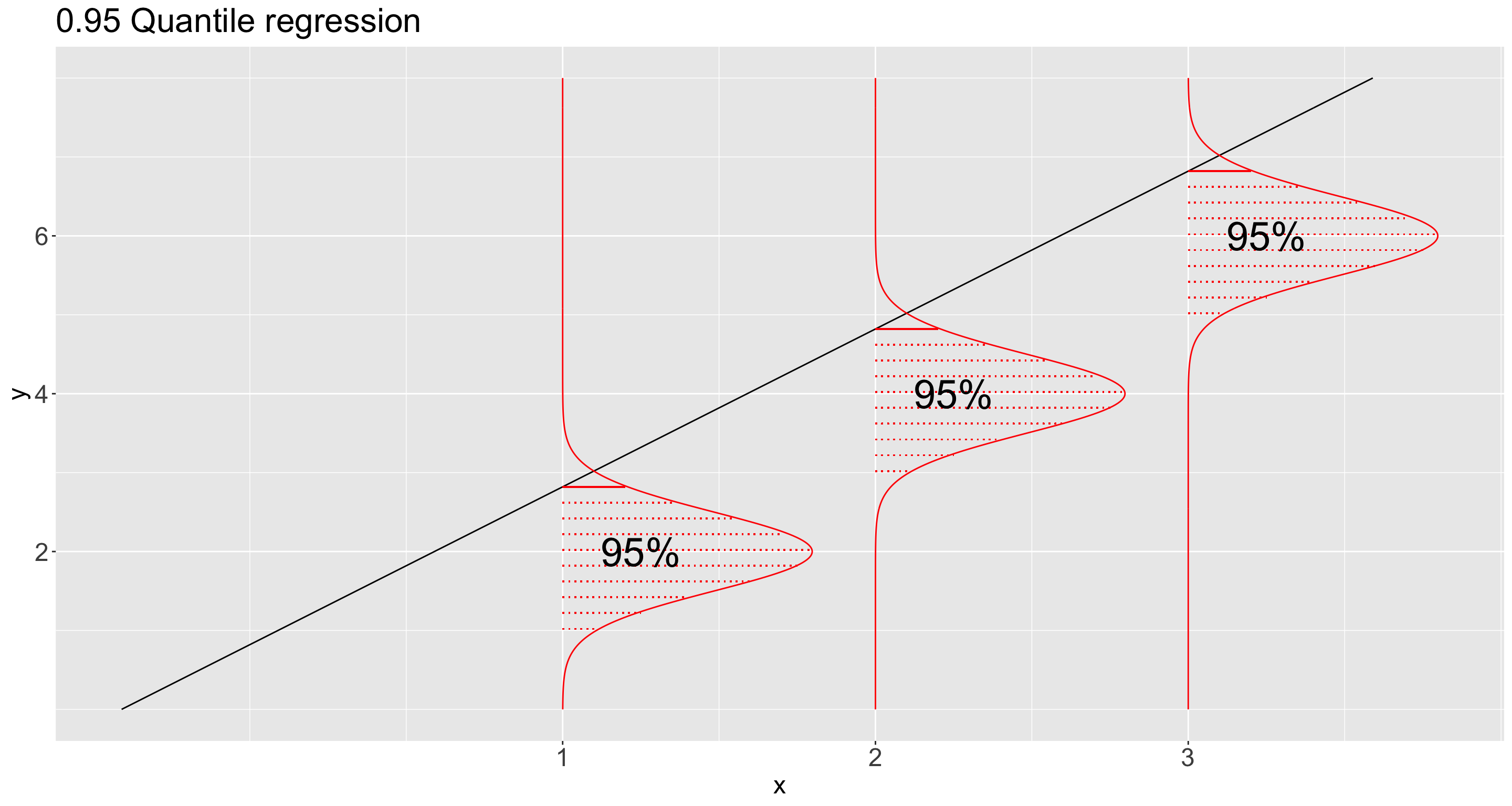
What about now? Do we have a better idea about the distribution?
A. Yes, having different quantiles gives us a better idea about the distribution of heights.
B. Not, at all!

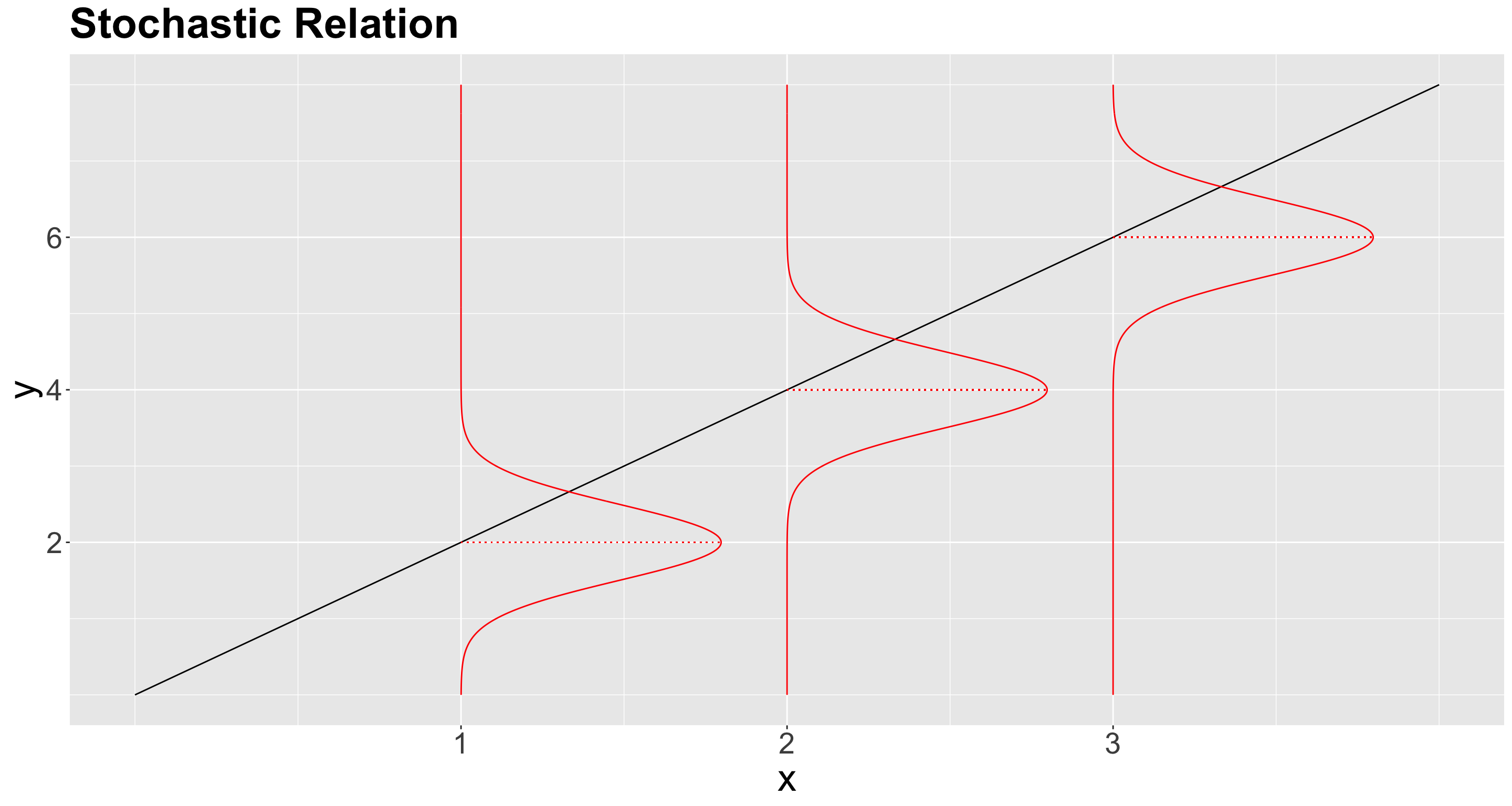
Is it possible to go beyond the conditioned mean?
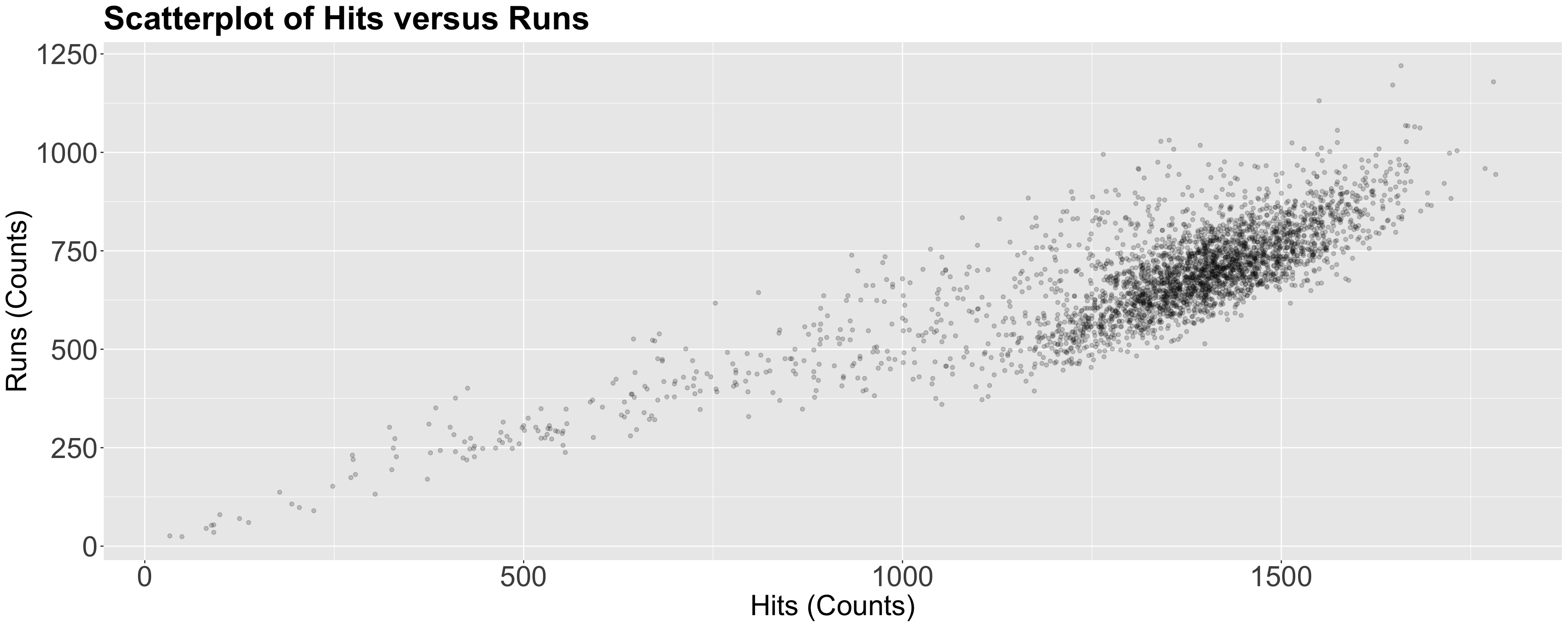
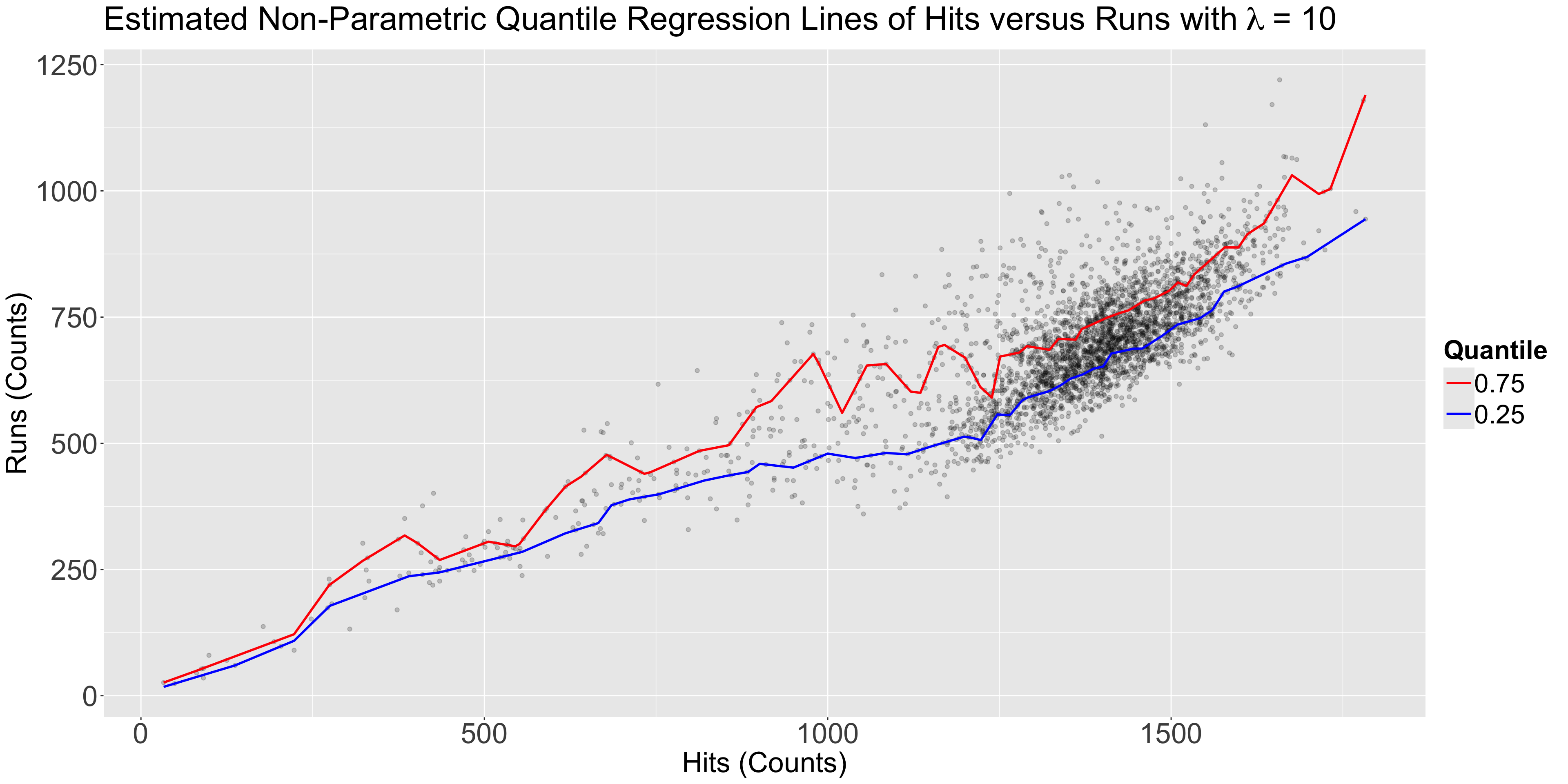
Teams dataset from the Lahman package.
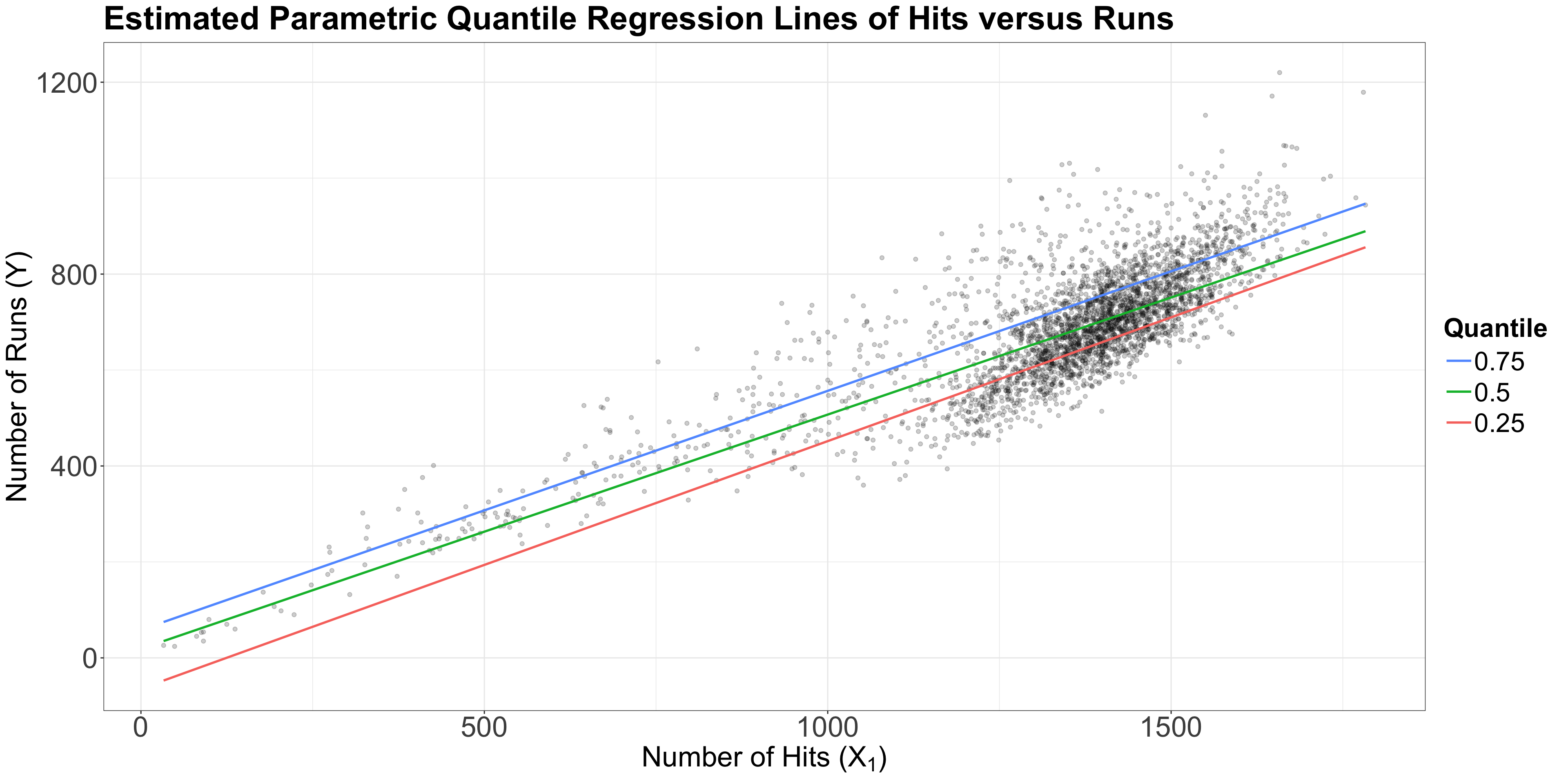
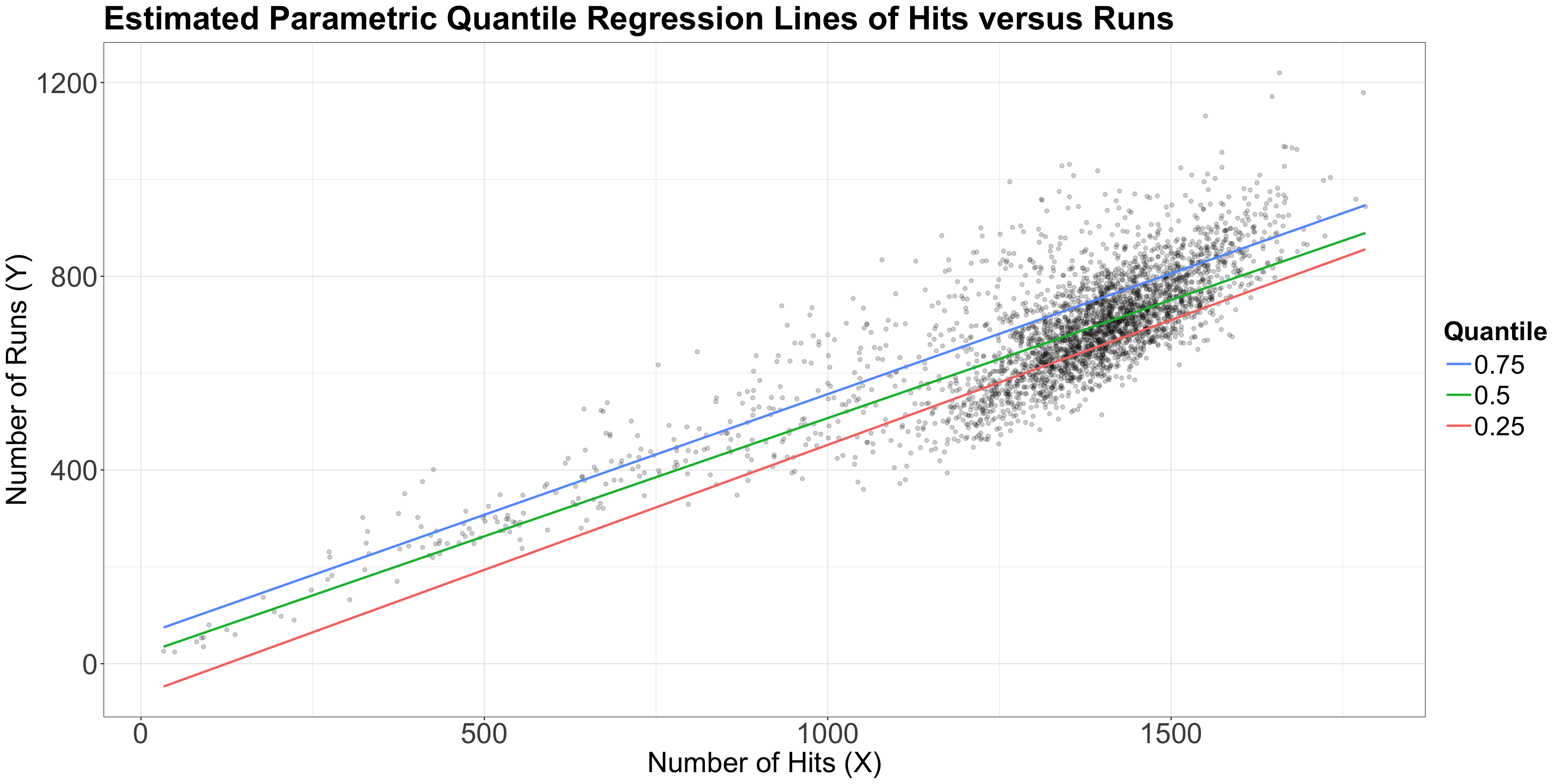
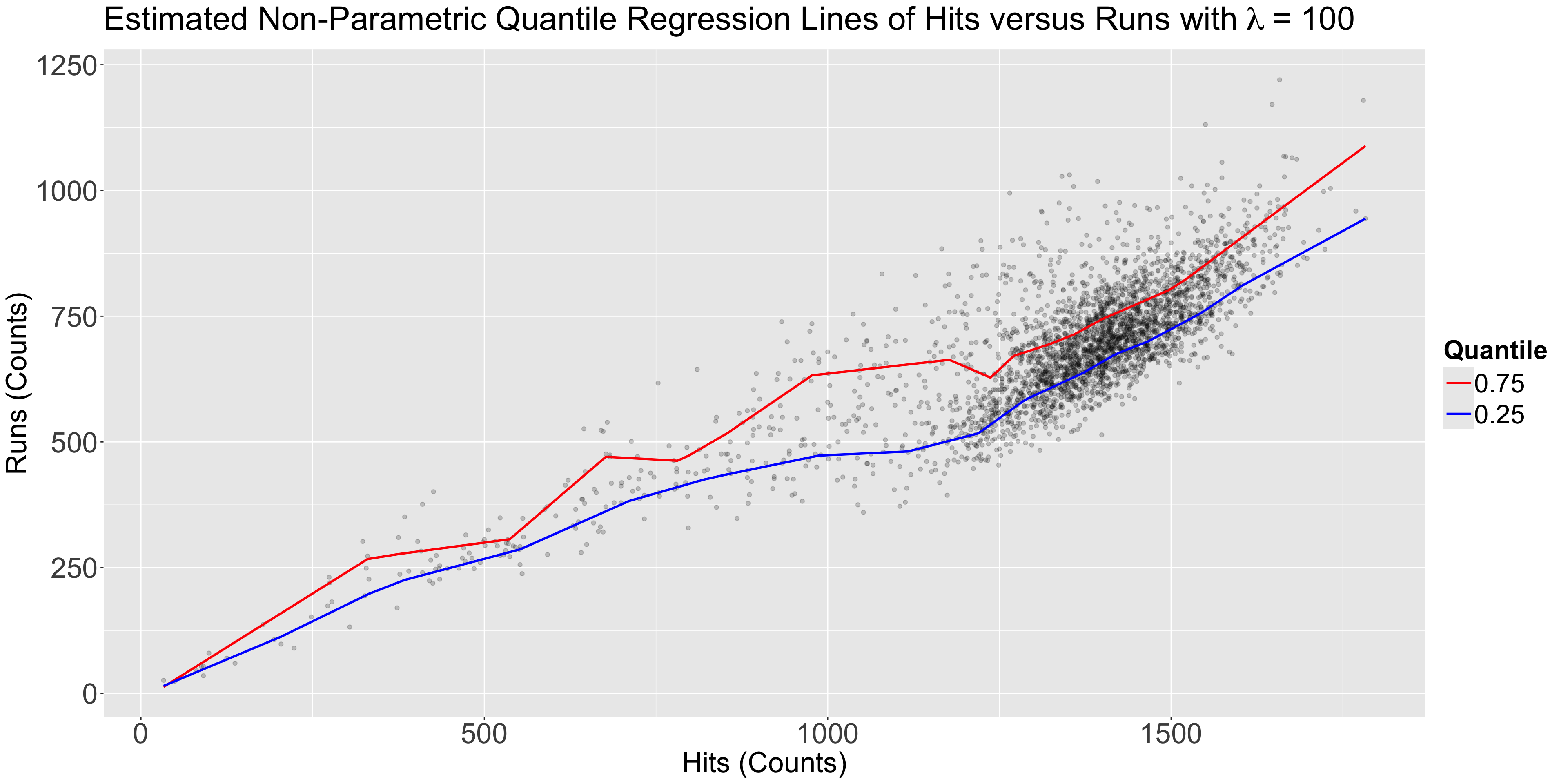
Let us create a scatterplot of hits (our regressor) versus runs (our response), even though these variables are not continuous.
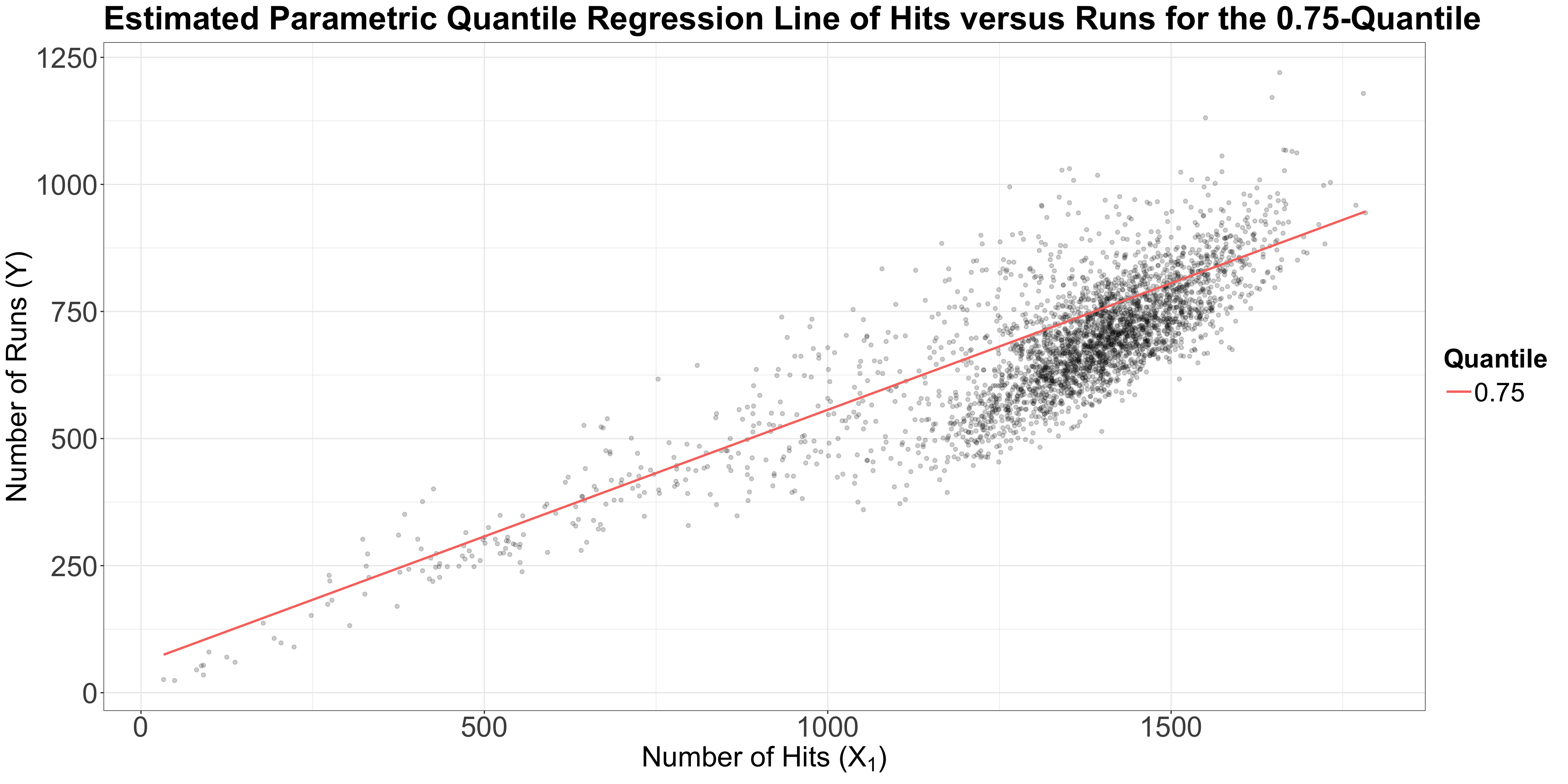
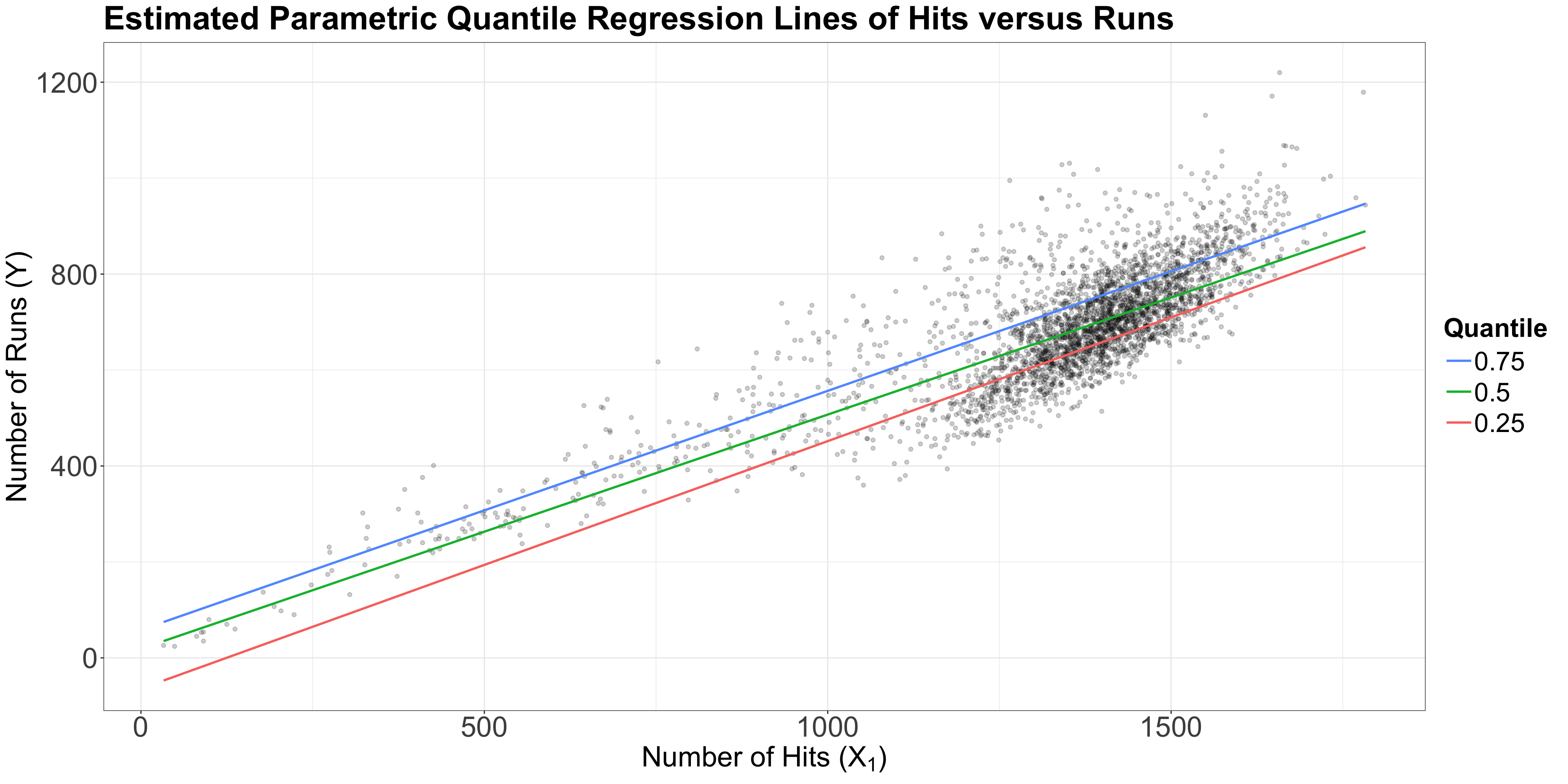
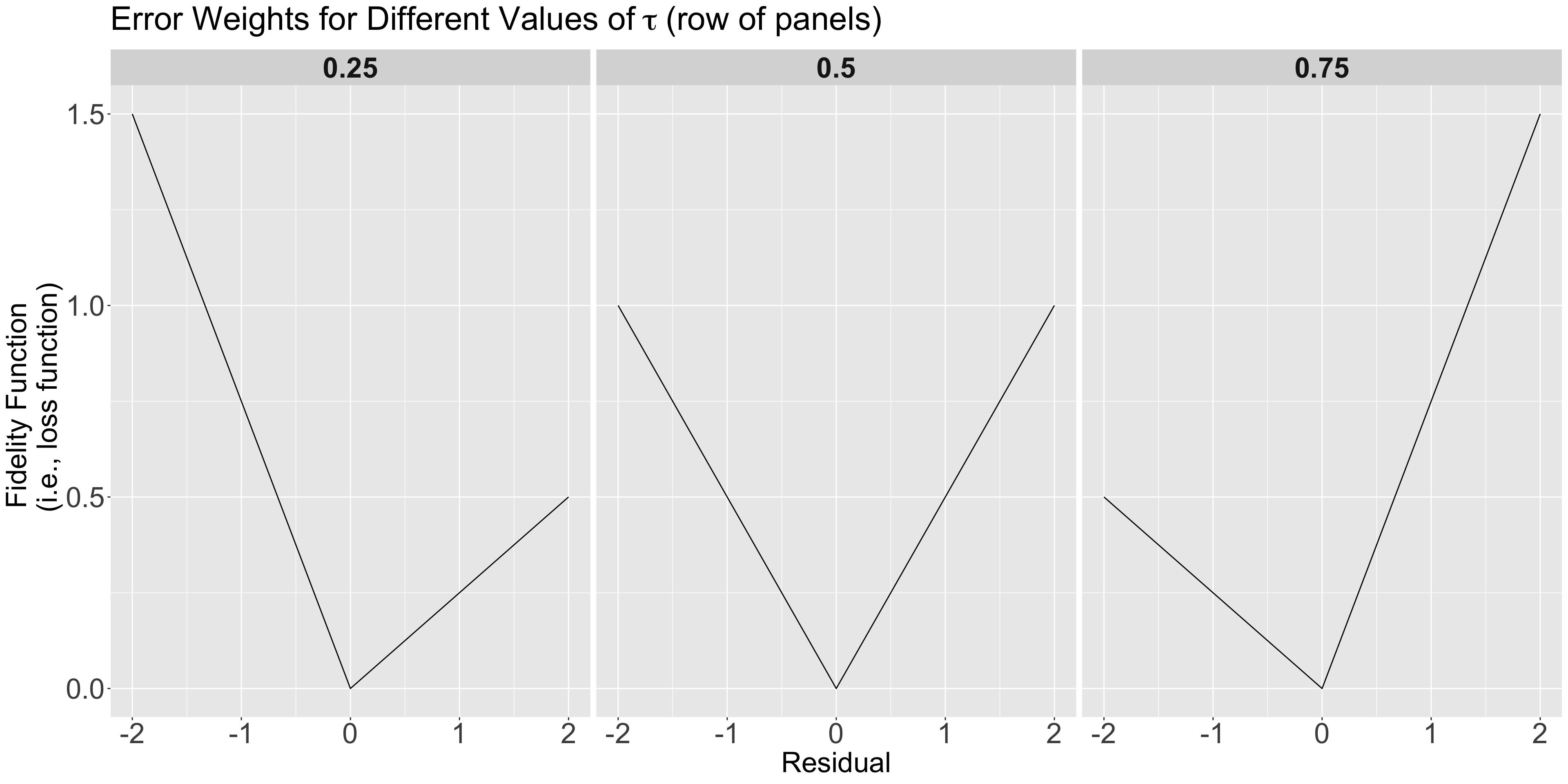
teams dataset, let us plot the three estimated parametric Quantile regression lines for quantiles \(\tau = 0.25, 0.5, 0.75\).runs, whereas our regressor \(X_1\) is hits.
se = "boot" and bsmethod = "xy".R = 1000 replicates in function summary().
![]()