Predict students’ dropout and academic success#
by Katherine Chen, Hancheng Qin, Yili Tang, Bill Wan 2023/12/02
Abstraction#
This study delves into the multiple factors influencing student performance, utilizing the comprehensive Student Performance dataset from the UCI Machine Learning Repository. The datasets encompass a wide array of attributes, including demographic information, family background, past education experience, alongside with academic grades. Our analysis employs various predictive modeling techniques to find out the impact of these factors on students’ final academic outcomes. The objective is to unravel the complex interplay between the features contributing to academic success, thereby offering insights for educationalists and policymakers to enhance learning environments. The findings aim to contribute to the growing field of educational data mining by providing a nuanced understanding of the determinants of academic achievement and thereby inform targeted audience for educational improvement.
Summary#
In our study, we developed machine learning models, including SVM, Random Forest, and Logistic Regression (with L1 and L2 regularization), to predict the likelihood of student academic dropout in higher education. Due to a high number of features and their inter-correlations, our models initially exhibited overfitting. To address this, we implemented feature selection techniques (PCA and feature importance analysis) along with model’s parameter optimization. The refined models demonstrated improved performance, evidenced by a narrow gap between training and testing accuracy. Among the three, SVM marginally outperformed the others, achieving an accuracy of 80% and an AUC score of 0.89. Nonetheless, there is potential for further enhancement in model performance through additional feature engineering and more extensive parameter tuning.
Introduction#
In the realm of educational analytics, understanding the factors that influence student performance is pivotal for shaping effective pedagogical strategies. Our project delves into this domain, leveraging the rich and multifaceted Student Performance Data Set from the UCI Machine Learning Repository [Cortez, 2014]. This dataset, derived from two Portuguese secondary schools, offers a comprehensive view of various personal, social, and academic factors impacting student achievement in Mathematics and Portuguese language courses.
Machine learning methodologies have been extensively used in educational data mining to detect patterns in large collections of educational data [Romero and Ventura, 2015]. Our objective is to utilize machine learning techniques to analyze and predict student academic outcomes, focusing primarily on identifying key predictors of success and risk factors for academic dropout. Through this analysis, we aim to uncover insights that can guide interventions and support mechanisms to enhance student performance. The dataset’s inclusivity of attributes ranging from demographic backgrounds and family information to study habits and lifestyle choices provides a unique opportunity to explore the multifaceted nature of academic success.
Methods#
Data#
The data set used in this project is of student performance in secondary education (high school) of two Portuguese schools [Cortez, 2014]. The data attributes include student grades, demographic, social and school related features, and it was collected by using school reports and questionnaires. Two datasets are provided regarding the performance in two distinct subjects: Mathematics and Portuguese language. The data set was sourced from the UCI Machine Learning Repository and can be found here. Each row in the data set represents a student’s profile and academic outcomes, including the final grade (G3) and several other variables (e.g., school, sex, age, study time, absences, etc.).
Analysis#
The method we use include Random Forest, Logistic Regression, and SVM. In the landscape of machine learning, three algorithms stand out for their efficacy and versatility: Logistic Regression, Random Forest, and Support Vector Machine (SVM). We have employed the method of feature importance values and Principal Component Analysis (PCA) to streamline the dimensionality of our feature space. Data was split with 80% being partitioned into the training set and 20% being partitioned into the test set. The hyperparameter \(K\) was chosen using 10-fold cross validation with the test score as the classification metric. All numerical variables were standardized and categorical features were preprocessed by one-hot encoding just prior to model fitting. The Python programming language [Van Rossum and Drake, 2009]. code used to perform the analysis and create this report can be found here.
Results & Discussion#
To examine the potential of each predictor in forecasting student performance, we plotted the distributions of each predictor from the training data set and coloured the distribution by target class (graduate: green, dropout: orange, enroller: blue). In doing this we see that class distributions for most of the predictors overlap somewhat, but do show quite a difference in their centres and spreads. In particular, we come up with below observation in numeric features:
Previous Qualification (Grade) and Admission Grade: Both these variables have similar ranges (min 95 to max 190), indicating a possible correlation between previous academic performance and admission grades. The mean and median values are close, suggesting a relatively symmetric distribution for these variables.
Age at Enrollment: The age range is quite broad (17 to 70 years), indicating a diverse set of students in terms of age. Transformation technique like Standardization is required
Curricular Units Credited (1st and 2nd Semesters): The mean values for credited curricular units in both semesters are low (around 0.71 for the 1st semester and 0.54 for the 2nd), the 75% percentile is 0, suggesting that most students do not have many, if any, units credited. This could be because they are first year students.
Below are density plot of numerical variables:
Fig. 1 Distributions comparison of numeric features between the Graduate, Dropout, and Enrolled groups.#
While for categorical features, we come up with the below conclusion:
Nationality: The majority are Portuguese, with a small representation from other nationalities.
Parents’ Occupation: Both mother’s and father’s occupations are coded numerically. The most common occupation code for mothers and fathers is Unskilled Workers. Be careful about the matrix sparsity issue.
Debtor, Tuition Fees Up to Date, Scholarship Holder: There’s a notable number of students who are debtors (397) or whose tuition fees are not up to date (419), while 871 are scholarship holders. These figures highlight the financial aspects and challenges faced by the student population.
Feature Importance are shown as following: The second semester grade emerges as a significant indicator of student academic achievement, corroborating our intuitive understanding of its importance. Contrary to expectations, some features traditionally considered impactful display lower feature importance values. This discrepancy may stem from the inherent stochastic nature of feature selection within the Random Forest algorithm, which can lead to variability in the importance assigned to different features.
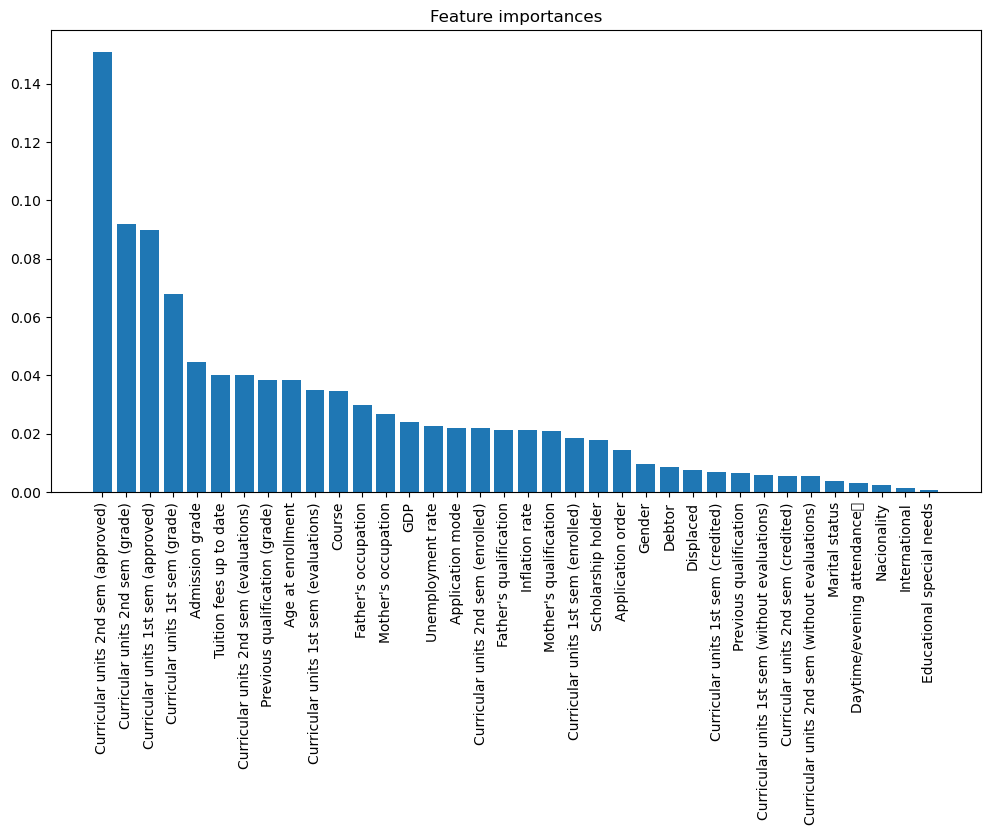
Fig. 2 Show the result of feature importance value of Random Forest Method#
Below are histogram distribution plot of categorical variables:
Fig. 3 Distribution comparison of categorical predictors between the Graduate, Dropout, and Enrolled groups.#
We also observed correlations between certain features. To visually represent these relationships, we employed a correlation heatmap. This heatmap reveals the strength of associations between different variables and aids in understanding how these variables collectively impact our subject of study:
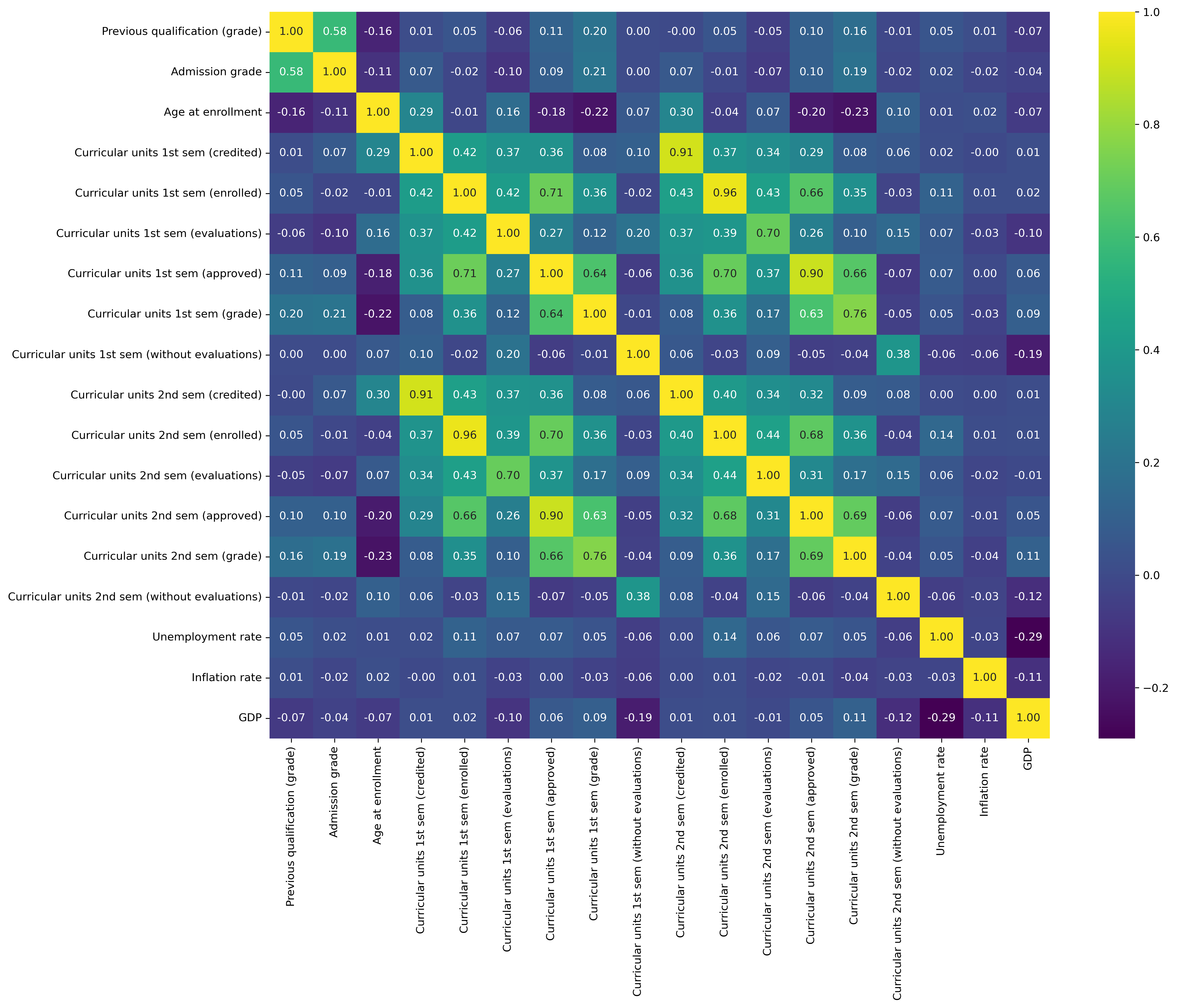
Fig. 4 Heatmap for correlation matrix.#
The final models demonstrated commendable performance, marked by a minimal discrepancy between training and testing results. This consistency is indicative of the models’ ability to generalize well to unseen data, a crucial aspect of robust machine learning models.
| Unnamed: 0 | RandomForest | Logistic Regression | SVC | |
|---|---|---|---|---|
| 0 | fit_time | 0.201609 | 0.075037 | 1.279907 |
| 1 | score_time | 0.030778 | 0.019465 | 0.203314 |
| 2 | test_accuracy | 0.757279 | 0.764905 | 0.757561 |
| 3 | train_accuracy | 0.843599 | 0.782283 | 0.787652 |
| 4 | test_precision | 0.737193 | 0.745870 | 0.743182 |
| 5 | train_precision | 0.850690 | 0.768551 | 0.779404 |
| 6 | test_recall | 0.757279 | 0.764905 | 0.757561 |
| 7 | train_recall | 0.843599 | 0.782283 | 0.787652 |
| 8 | test_f1 | 0.731526 | 0.744275 | 0.739644 |
| 9 | train_f1 | 0.832972 | 0.764501 | 0.771922 |
| 10 | test_roc_auc | 0.877215 | 0.869558 | 0.877458 |
| 11 | train_roc_auc | 0.961276 | 0.892067 | 0.907815 |
Fig. 5 Training scores for the three models: Logistic Regression, Random Forest, and Support Vector Machine.#
Among the three algorithms employed - Logistic Regression, Random Forest, and Support Vector Machine (SVM) - the performance metrics were closely aligned, suggesting that each model was able to capture the underlying patterns in the data effectively.
| Unnamed: 0 | RandomForest | LogisticRegression | SVC | |
|---|---|---|---|---|
| 0 | accuracy | 0.778531 | 0.783051 | 0.796610 |
| 1 | precision | 0.757904 | 0.766489 | 0.787877 |
| 2 | recall | 0.778531 | 0.783051 | 0.796610 |
| 3 | f1 | 0.751311 | 0.764394 | 0.779679 |
| 4 | roc_auc | 0.895952 | 0.894758 | 0.891939 |
Fig. 6 Test scores for the three models: Logistic Regression, Random Forest, and Support Vector Machine.#
However, there remains room for improvement in the models’ performance. Further refinement through advanced feature engineering could yield more significant insights from the data, potentially enhancing the models’ predictive accuracy. Feature engineering, by uncovering more relevant or representative features, can lead to a more nuanced understanding of the factors influencing student academic dropout. Moreover, meticulous parameter tuning, particularly for algorithms like SVM and Random Forest that are sensitive to specific parameter settings, could further optimize the models.
References#
Paulo Cortez. Student Performance. UCI Machine Learning Repository, 2014. DOI: https://doi.org/10.24432/C5TG7T. URL: https://archive.ics.uci.edu/dataset/320/student+performance.
Cristobal Romero and Sebastian Ventura. Educational data mining: a review of the state of the art. 2015. URL: https://www.researchgate.net/publication/220374213_Educational_Data_Mining_A_Review_of_the_State_of_the_Art.
Guido Van Rossum and Fred L. Drake. Python 3 Reference Manual. CreateSpace, Scotts Valley, CA, 2009. ISBN 1441412697.