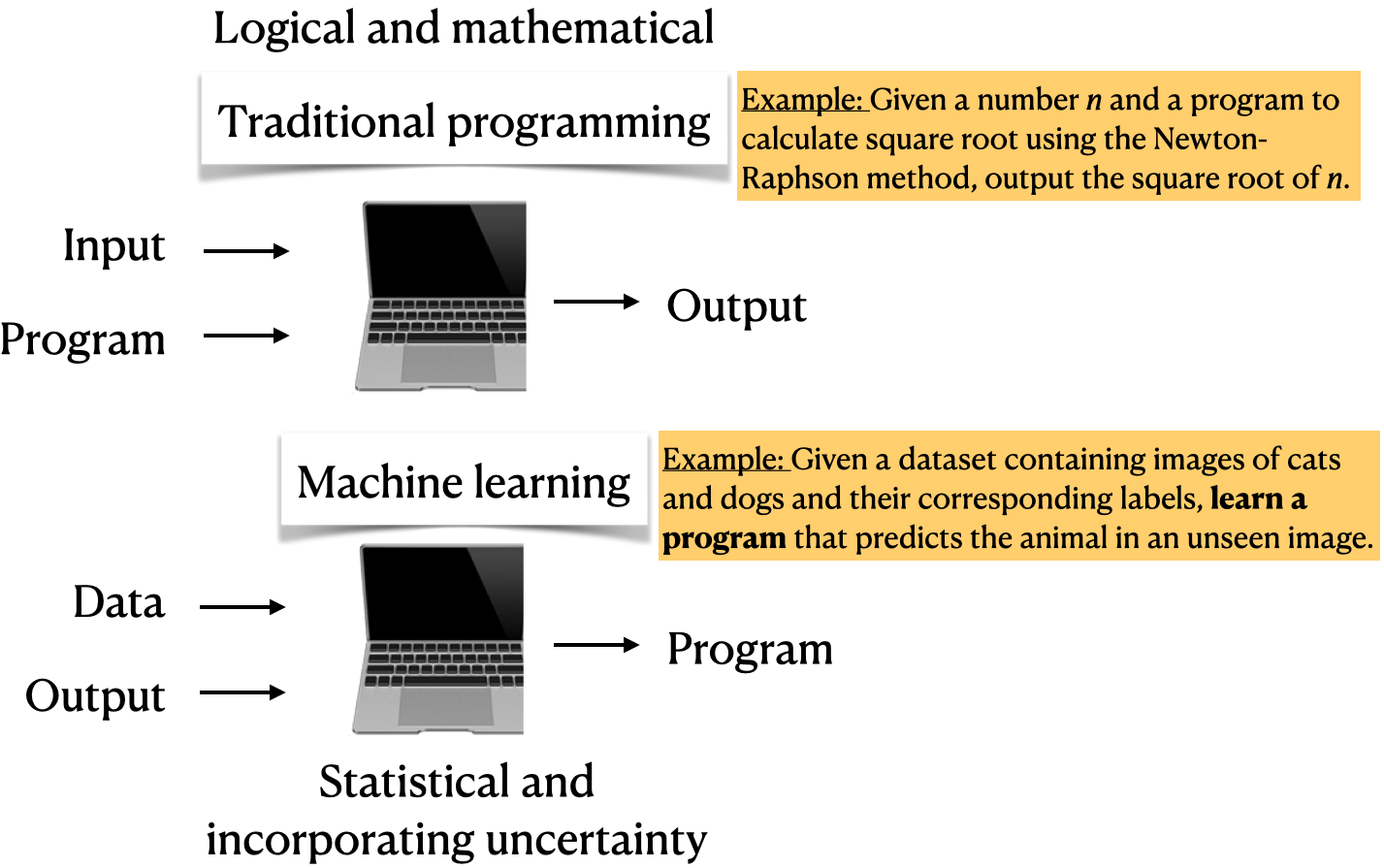
In all the the upcoming examples, Don’t worry about the code. Just focus on the input and output in each example.
train_df, test_df = train_test_split(df, test_size=4, random_state=16) train_df.head()
5 rows × 10 columns
from xgboost import XGBClassifier X_train = train_df.drop(columns=['Target']) y_train = train_df['Target'] X_test = test_df.drop(columns=['Target']) model = XGBClassifier() model.fit(X_train, y_train);
pred_df = pd.DataFrame( {"Predicted label": model.predict(X_test).tolist()} ) df_concat = pd.concat([X_test.reset_index(drop=True), pred_df], axis=1) df_concat
4 rows × 10 columns
images = glob.glob("test_images/*.*") for image in images: img = Image.open(image) img.load() plt.imshow(img) plt.show() df = classify_image(img) print(df.to_string(index=False))
Class Probability ox 0.869893 oxcart 0.065034 sorrel 0.028593 gazelle 0.010053
Class Probability llama 0.123625 ox 0.076333 kelpie 0.071548 ibex, Capra ibex 0.060569
Attribution: The dataset imdb_master.csv was obtained from Kaggle and downsampled for demonstration
imdb_master.csv
train_df.head()
X_train, y_train = train_df['review'], train_df['label'] X_test, y_test = test_df['review'], test_df['label'] clf = Pipeline( [ ("vect", CountVectorizer(max_features=5000)), ("clf", LogisticRegression(max_iter=5000)), ] ) clf.fit(X_train, y_train);
pred_dict = { "reviews": X_test[0:4], "true_sentiment": y_test[0:4], "sentiment_predictions": clf.predict(X_test[0:4]), } pred_df = pd.DataFrame(pred_dict) pred_df.head()
Attribution: The dataset kc_house_data.csv was obtained from Kaggle and downsampled for demonstration.
kc_house_data.csv
df = pd.read_csv("data/kc_house_data.csv") train_df, test_df = train_test_split(df, test_size=0.2, random_state=4) train_df.head()
5 rows × 19 columns
X_train = train_df.drop(columns=["price"]) X_train.head()
5 rows × 18 columns
y_train = train_df["price"] y_train.head()
608 219000.0 511 618250.0 641 200000.0 112 656500.0 535 530000.0 Name: price, dtype: float64
X_test = test_df.drop(columns=["price"]) y_test = train_df["price"]
from xgboost import XGBRegressor model = XGBRegressor() model.fit(X_train, y_train);
pred_df = pd.DataFrame( {"Predicted price": model.predict(X_test[0:4]).tolist(), "Actual price": y_test[0:4].tolist()} ) df_concat = pd.concat([X_test[0:4].reset_index(drop=True), pred_df], axis=1) df_concat.head()
4 rows × 20 columns