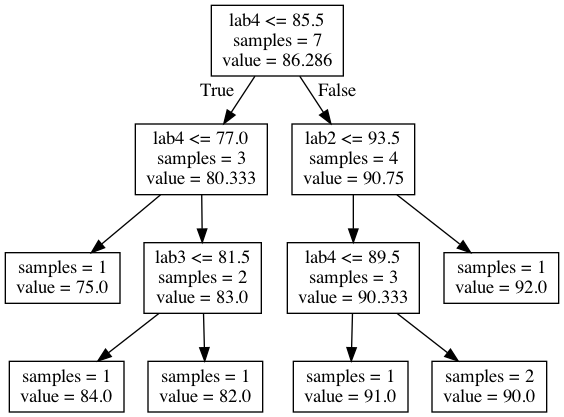
from sklearn.tree import DecisionTreeRegressordepth =4reg_model = DecisionTreeRegressor(max_depth=depth)reg_model.fit(X, y)
X.loc[[0]]
ml_experience
class_attendance
lab1
lab2
lab3
lab4
quiz1
0
1
1
92
93
84
91
92
reg_model.predict(X.loc[[0]])
array([90.])
predicted_grades = reg_model.predict(X)regression_df = regression_df.assign(predicted_quiz2 = predicted_grades)print("R^2 score on the training data:"+str(round(reg_model.score(X,y), 3)))