df = pd.read_csv("data/canada_usa_cities.csv")
X = df.drop(columns=["country"])
y = df["country"]Cross-validation
Single split problems
So what do we do?
𝑘-fold cross-validation
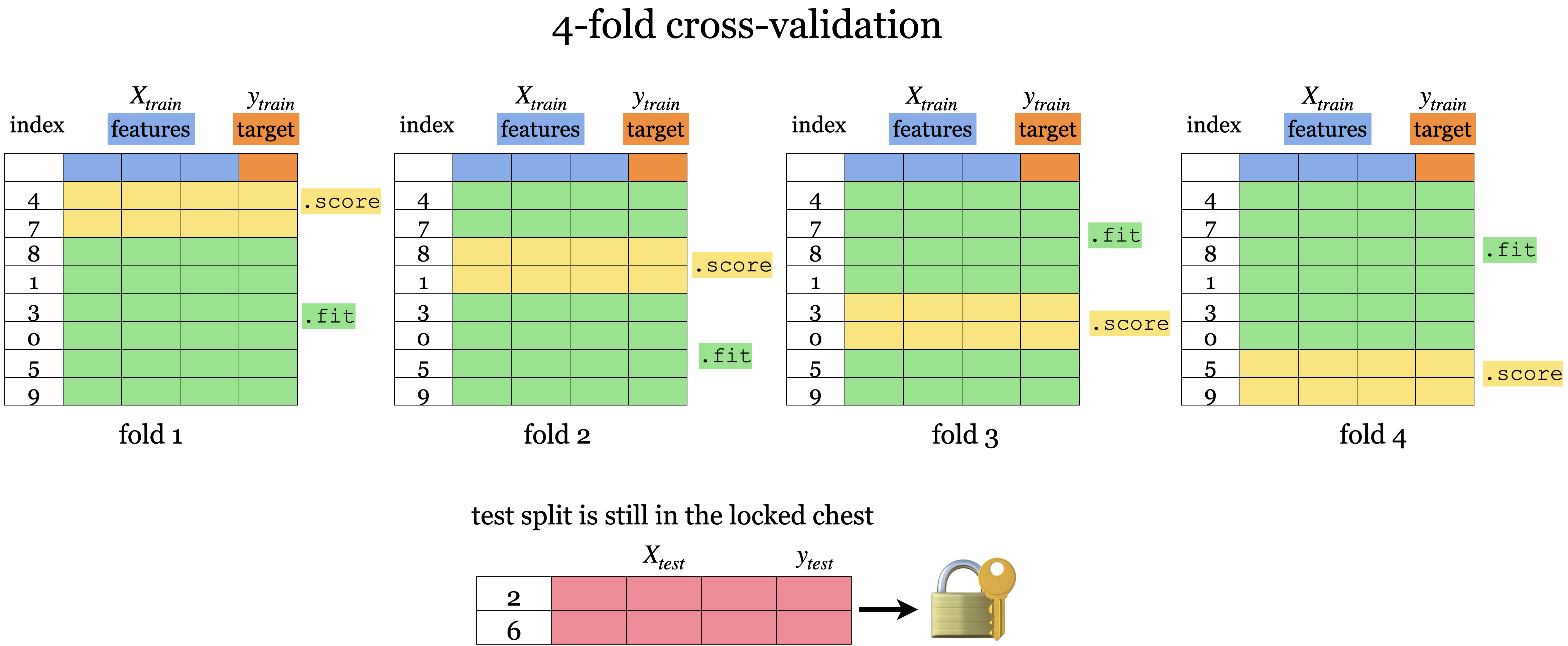
Cross-validation using scikit-learn
array([0.76470588, 0.82352941, 0.70588235, 0.94117647, 0.82352941, 0.82352941, 0.70588235, 0.9375 , 0.9375 , 0.9375 ])from sklearn.model_selection import cross_validate
scores = cross_validate(model, X_train, y_train, cv=10, return_train_score=True)
scores{'fit_time': array([0.00168347, 0.00167537, 0.00131798, 0.00130844, 0.00128198, 0.00131845, 0.00128341, 0.0012989 , 0.00128961, 0.00132298]),
'score_time': array([0.00122404, 0.0011344 , 0.00103498, 0.00102401, 0.00101638, 0.00103545, 0.00100684, 0.00101876, 0.00103331, 0.00102472]),
'test_score': array([0.76470588, 0.82352941, 0.70588235, 0.94117647, 0.82352941, 0.82352941, 0.70588235, 0.9375 , 0.9375 , 0.9375 ]),
'train_score': array([0.91333333, 0.90666667, 0.90666667, 0.9 , 0.90666667, 0.91333333, 0.92 , 0.90066225, 0.90066225, 0.90066225])}{'fit_time': array([0.00168347, 0.00167537, 0.00131798, 0.00130844, 0.00128198, 0.00131845, 0.00128341, 0.0012989 , 0.00128961, 0.00132298]),
'score_time': array([0.00122404, 0.0011344 , 0.00103498, 0.00102401, 0.00101638, 0.00103545, 0.00100684, 0.00101876, 0.00103331, 0.00102472]),
'test_score': array([0.76470588, 0.82352941, 0.70588235, 0.94117647, 0.82352941, 0.82352941, 0.70588235, 0.9375 , 0.9375 , 0.9375 ]),
'train_score': array([0.91333333, 0.90666667, 0.90666667, 0.9 , 0.90666667, 0.91333333, 0.92 , 0.90066225, 0.90066225, 0.90066225])}| fit_time | score_time | test_score | train_score | |
|---|---|---|---|---|
| 0 | 0.001683 | 0.001224 | 0.764706 | 0.913333 |
| 1 | 0.001675 | 0.001134 | 0.823529 | 0.906667 |
| 2 | 0.001318 | 0.001035 | 0.705882 | 0.906667 |
| ... | ... | ... | ... | ... |
| 7 | 0.001299 | 0.001019 | 0.937500 | 0.900662 |
| 8 | 0.001290 | 0.001033 | 0.937500 | 0.900662 |
| 9 | 0.001323 | 0.001025 | 0.937500 | 0.900662 |
10 rows × 4 columns
fit_time 0.001378
score_time 0.001055
test_score 0.840074
train_score 0.906865
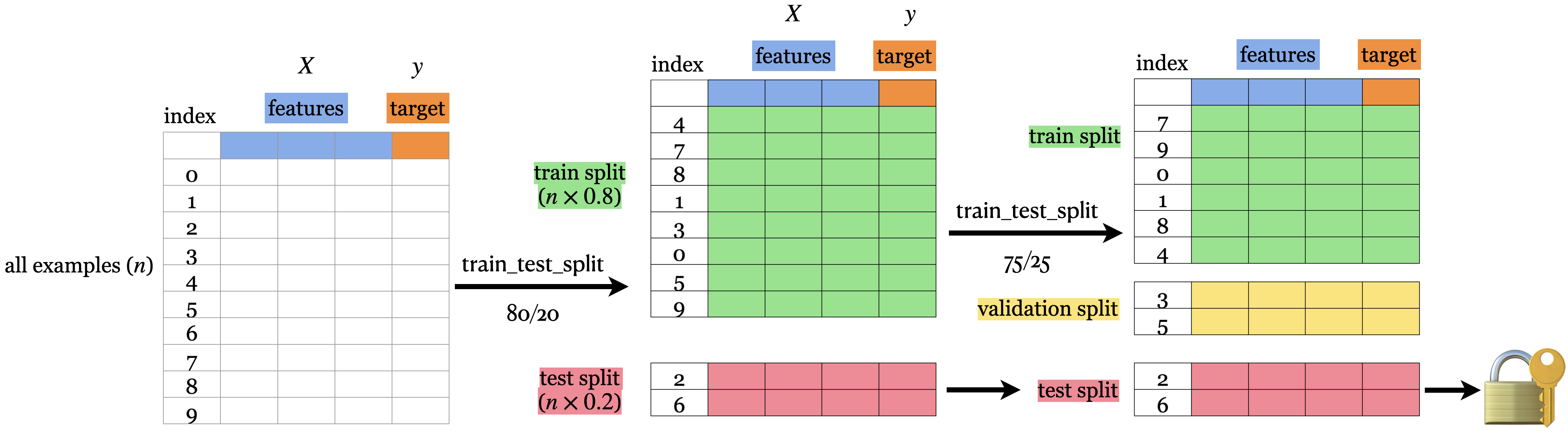
dtype: float64Our typical supervised learning set up is as follows:
- Given training data with
Xandy. - We split our data into
X_train, y_train, X_test, y_test. - Hyperparameter optimization using cross-validation on
X_trainandy_train. - We assess the best model using
X_testandy_test. - The test score tells us how well our model generalizes.
- If the test score is reasonable, we deploy the model.