df = pd.read_csv("data/canada_usa_cities.csv")
X = df.drop(columns=["country"])
y = df["country"]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=123)Overfitting and underfitting
Overfitting
model = DecisionTreeClassifier()
scores = cross_validate(model, X_train, y_train, cv=10, return_train_score=True)
print("Train score: " + str(round(scores["train_score"].mean(), 2)))
print("Validation score: " + str(round(scores["test_score"].mean(), 2)))Train score: 1.0
Validation score: 0.81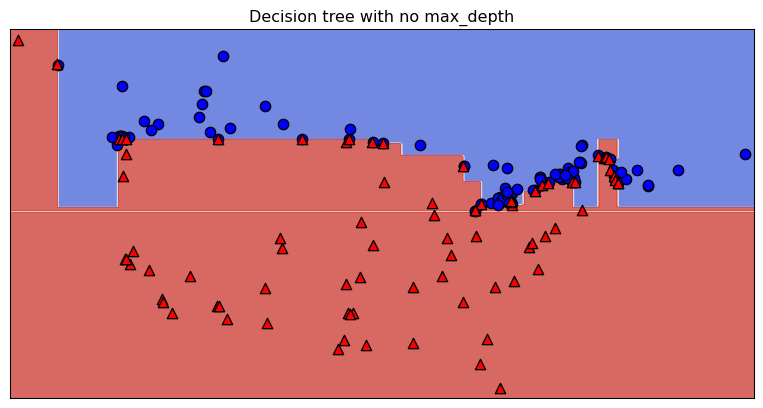
Underfitting
model = DecisionTreeClassifier(max_depth=1)
scores = cross_validate(model, X_train, y_train, cv=10, return_train_score=True)
print("Train score: " + str(round(scores["train_score"].mean(), 2)))
print("Validation score: " + str(round(scores["test_score"].mean(), 2)))Train score: 0.83
Validation score: 0.81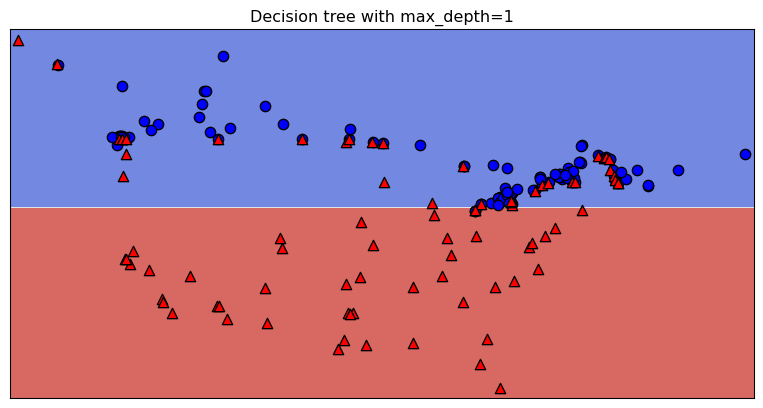
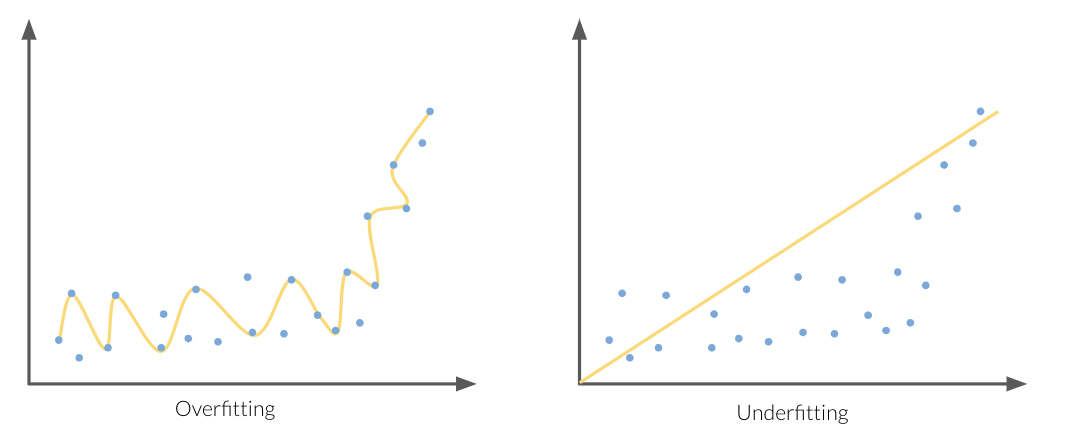
Standard question to ask ourselves: Which of these scenarios am I in?
How can we figure this out?
Score_train and Score_valid.
- If they are very far apart → more likely overfitting.
- Try decreasing model complexity.
- If they are very close together → more likely underfitting.
- Try increasing model complexity.