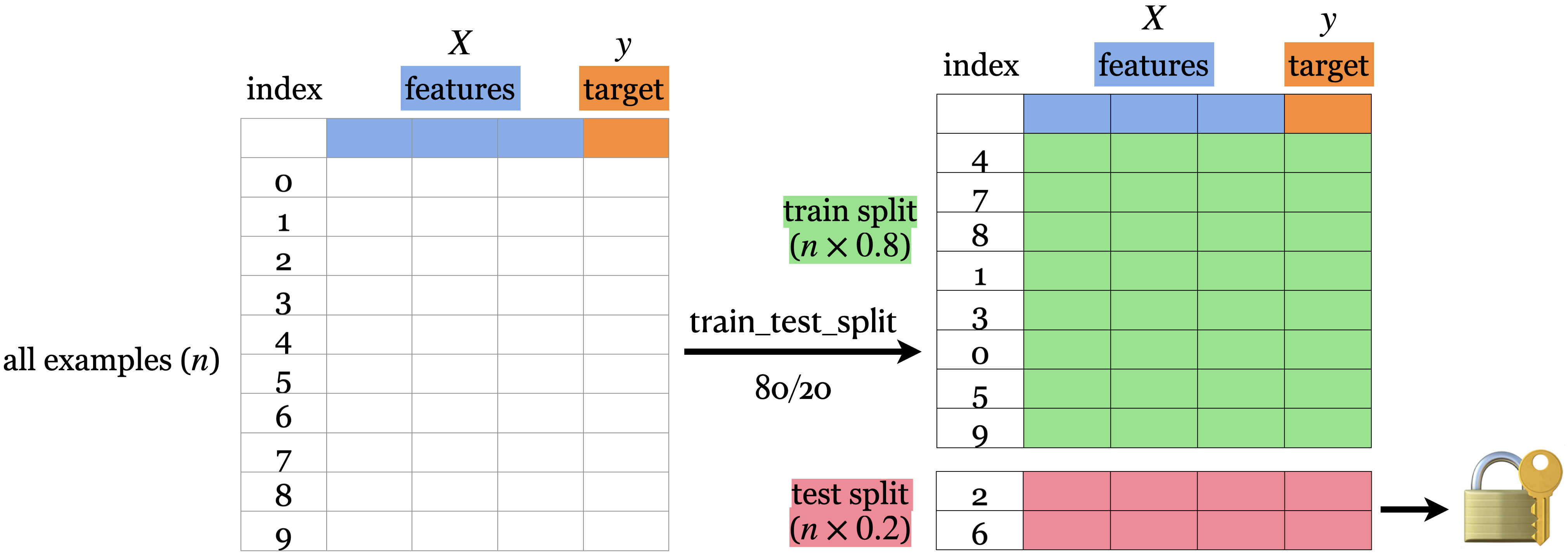
df = pd.read_csv("data/canada_usa_cities.csv")
X = df.drop(columns=["country"])
y = df["country"]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=123)The fundamental tradeoff and the golden rule
source = results_df.melt(id_vars=['depth'] ,
value_vars=['mean_train_score', 'mean_cv_score'],
var_name='plot', value_name='score')chart1 = alt.Chart(source).mark_line().encode(
alt.X('depth:Q', axis=alt.Axis(title="Tree Depth")),
alt.Y('score:Q'),
alt.Color('plot:N', scale=alt.Scale(domain=['mean_train_score', 'mean_cv_score'],
range=['teal', 'gold'])))
chart1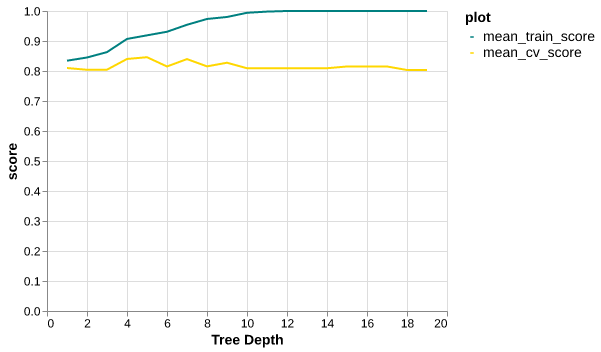
The Golden Rule
Even though we care the most about test score:
THE TEST DATA CANNOT INFLUENCE THE TRAINING PHASE IN ANY WAY

Golden rule violation: Example 1

Golden rule violation: Example 2

How can we avoid violating the golden rule?