from sklearn.model_selection import train_test_split
cities_df = pd.read_csv("data/canada_usa_cities.csv")
X = cities_df.drop(columns=["country"])
y = cities_df["country"]
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.1, random_state=123)Choosing 𝑘 (n_neighbors)
from sklearn.model_selection import cross_validate
k = 1
knn1 = KNeighborsClassifier(n_neighbors=k)
scores = cross_validate(knn1, X_train, y_train, return_train_score = True)
pd.DataFrame(scores)| fit_time | score_time | test_score | train_score | |
|---|---|---|---|---|
| 0 | 0.001391 | 0.001975 | 0.710526 | 1.0 |
| 1 | 0.001272 | 0.001861 | 0.684211 | 1.0 |
| 2 | 0.001185 | 0.001819 | 0.842105 | 1.0 |
| 3 | 0.001213 | 0.001837 | 0.702703 | 1.0 |
| 4 | 0.001214 | 0.001807 | 0.837838 | 1.0 |
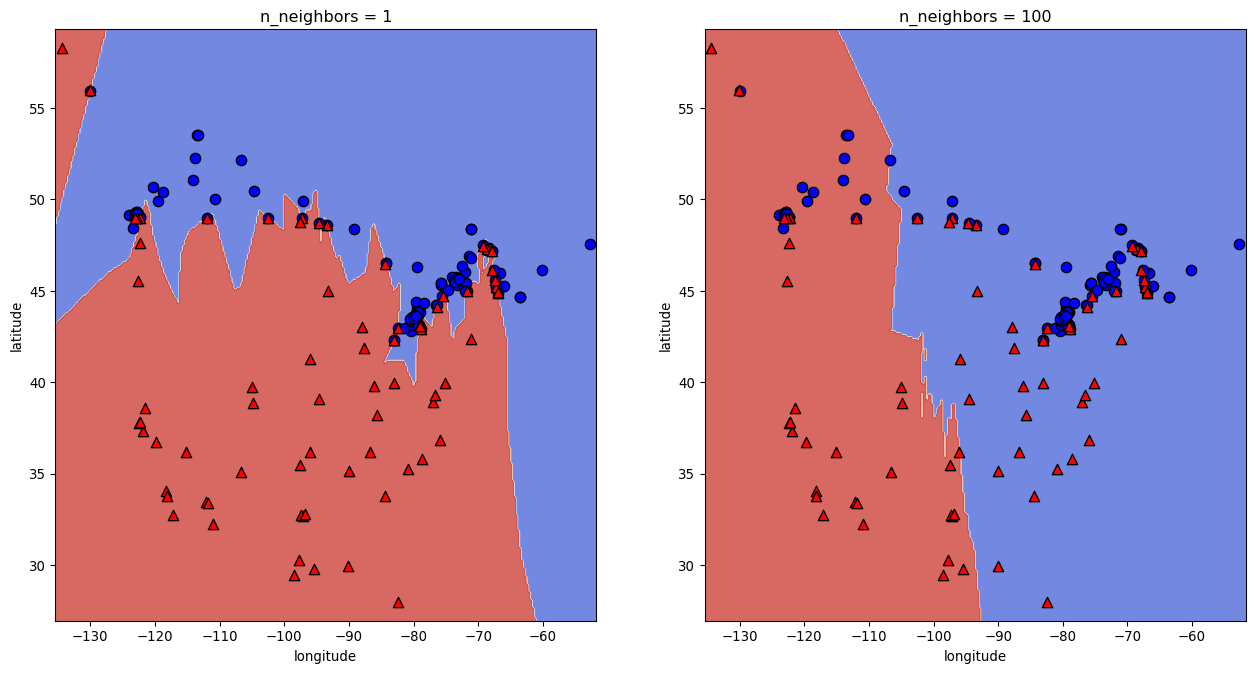
k = 100
knn100 = KNeighborsClassifier(n_neighbors=k)
scores = cross_validate(knn100, X_train, y_train, return_train_score = True)
pd.DataFrame(scores)| fit_time | score_time | test_score | train_score | |
|---|---|---|---|---|
| 0 | 0.001248 | 0.038892 | 0.605263 | 0.600000 |
| 1 | 0.001245 | 0.002144 | 0.605263 | 0.600000 |
| 2 | 0.001144 | 0.002125 | 0.605263 | 0.600000 |
| 3 | 0.001120 | 0.002077 | 0.594595 | 0.602649 |
| 4 | 0.001126 | 0.002078 | 0.594595 | 0.602649 |
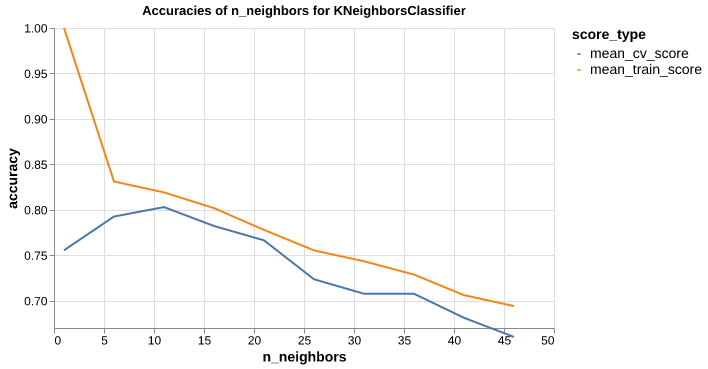
How to choose n_neighbors?
results_dict = {"n_neighbors": list(), "mean_train_score": list(), "mean_cv_score": list()}
for k in range(1,50,5):
knn = KNeighborsClassifier(n_neighbors=k)
scores = cross_validate(knn, X_train, y_train, return_train_score = True)
results_dict["n_neighbors"].append(k)
results_dict["mean_cv_score"].append(np.mean(scores["test_score"]))
results_dict["mean_train_score"].append(np.mean(scores["train_score"]))
results_df = pd.DataFrame(results_dict)
results_df| n_neighbors | mean_train_score | mean_cv_score | |
|---|---|---|---|
| 0 | 1 | 1.000000 | 0.755477 |
| 1 | 6 | 0.831135 | 0.792603 |
| 2 | 11 | 0.819152 | 0.802987 |
| ... | ... | ... | ... |
| 7 | 36 | 0.728777 | 0.707681 |
| 8 | 41 | 0.706128 | 0.681223 |
| 9 | 46 | 0.694155 | 0.660171 |
10 rows × 3 columns
| n_neighbors | mean_train_score | mean_cv_score | |
|---|---|---|---|
| 2 | 11 | 0.819152 | 0.802987 |
| 1 | 6 | 0.831135 | 0.792603 |
| 3 | 16 | 0.801863 | 0.782219 |
| ... | ... | ... | ... |
| 7 | 36 | 0.728777 | 0.707681 |
| 8 | 41 | 0.706128 | 0.681223 |
| 9 | 46 | 0.694155 | 0.660171 |
10 rows × 3 columns
Curse of dimensionality
- 𝑘 -NN usually works well when the number of dimensions is small.

Other useful arguments of KNeighborsClassifier