np.random.seed(0) n = 50 X_1 = np.linspace(0,2,n)+np.random.randn(n)*0.01 X = pd.DataFrame(X_1[:,None], columns=['length']) X.head()
y = abs(np.random.randn(n,1))*2 + X_1[:,None]*5 y = pd.DataFrame(y, columns=['weight']) y.head()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
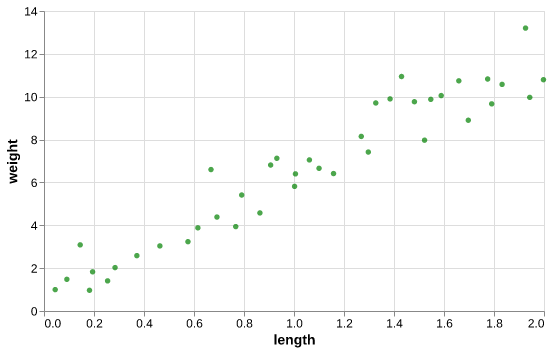
import altair as alt source = pd.concat([X_train, y_train], axis=1) scatter = alt.Chart(source, width=500, height=300).mark_point(filled=True, color='green').encode( alt.X('length:Q'), alt.Y('weight:Q')) scatter
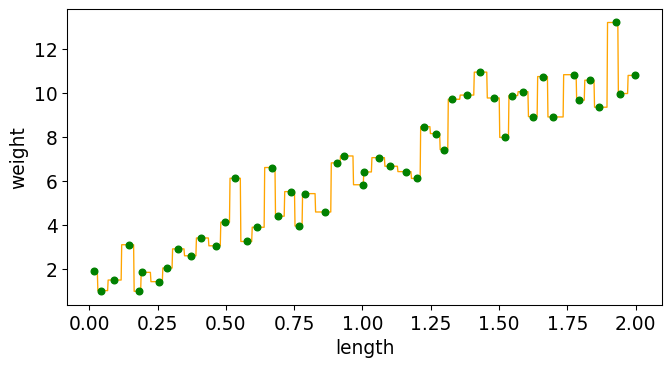
from sklearn.neighbors import KNeighborsRegressor knnr = KNeighborsRegressor(n_neighbors=1, weights="uniform") knnr.fit(X_train,y_train);
predicted = knnr.predict(X_train) predicted[:5]
array([[ 4.57636104], [13.20245224], [ 3.03671796], [10.74123618], [ 1.82820801]])
knnr.score( X_train, y_train)
1.0
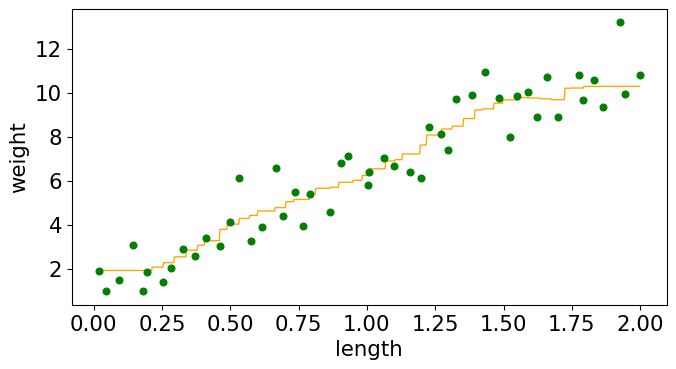
knnr = KNeighborsRegressor(n_neighbors=10, weights="uniform") knnr.fit(X_train, y_train);
knnr.score(X_train, y_train)
0.9254540554756747
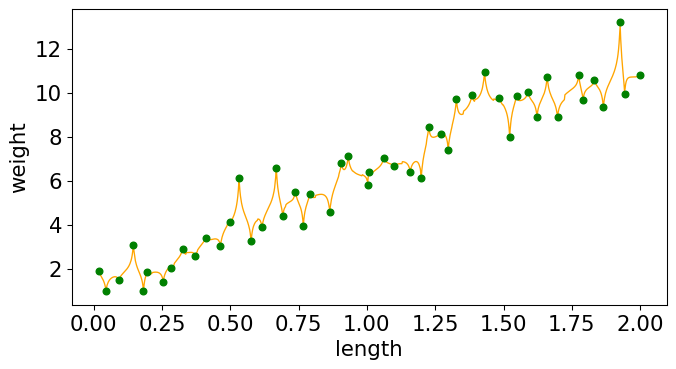
knnr = KNeighborsRegressor(n_neighbors=10, weights="distance") knnr.fit(X_train, y_train);
n_neighbors
fit