knn_unscaled = KNeighborsClassifier();
knn_unscaled.fit(X_train, y_train)
print('Train score: ', (round(knn_unscaled.score(X_train, y_train), 2)))
print('Test score: ', (round(knn_unscaled.score(X_test, y_test), 2)))
KNeighborsClassifier()
Train score: 0.71
Test score: 0.45
knn_scaled = KNeighborsClassifier();
knn_scaled.fit(X_train_scaled, y_train)
print('Train score: ', (round(knn_scaled.score(X_train_scaled, y_train), 2)))
print('Test score: ', (round(knn_scaled.score(X_test_scaled, y_test), 2)))
KNeighborsClassifier()
Train score: 0.94
Test score: 0.89
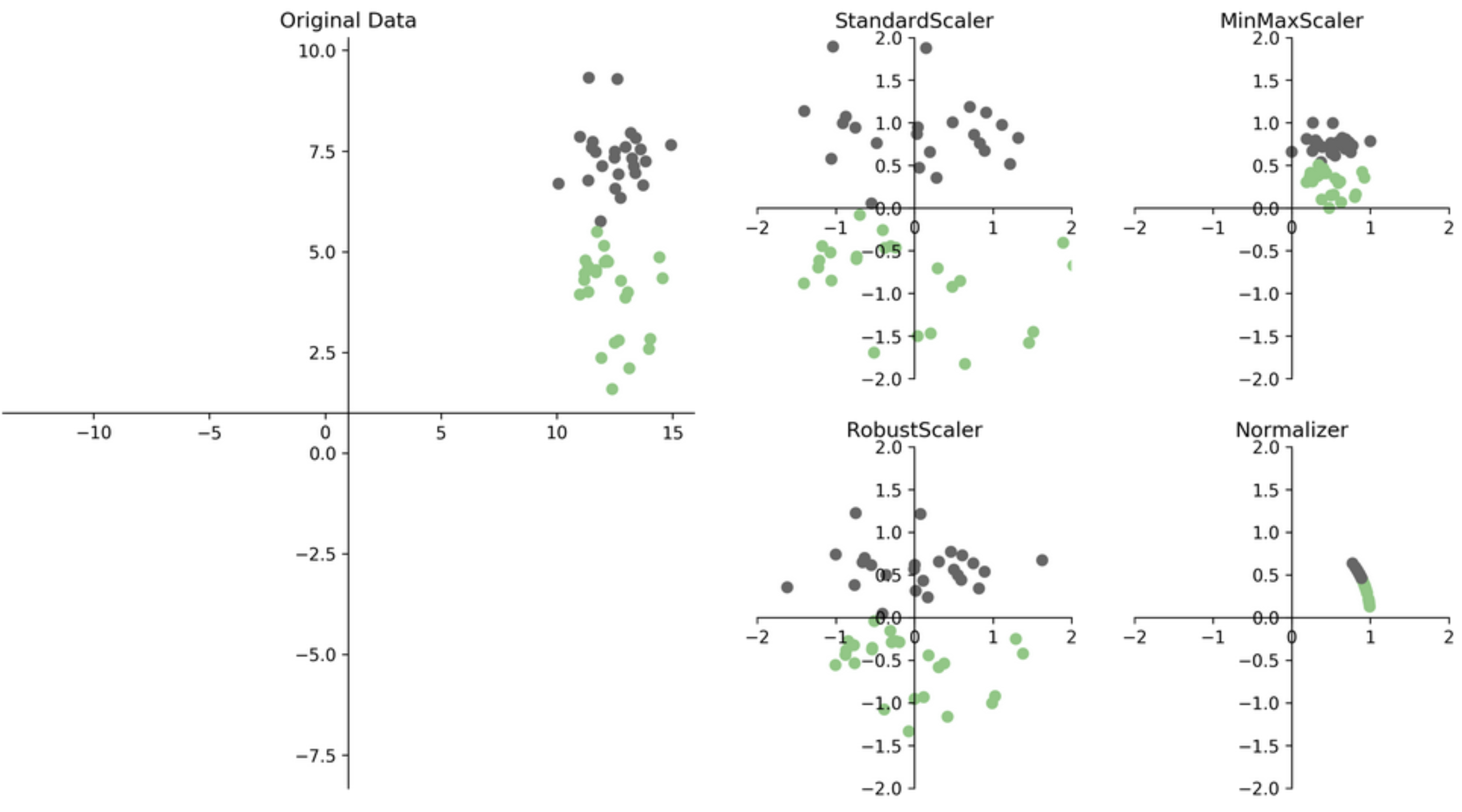
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_train_scaled = scaler.fit_transform(X_train_imp)
X_test_scaled = scaler.transform(X_test_imp)
pd.DataFrame(X_train_scaled, columns=X_train.columns, index=X_train.index).head()
| 6051 |
0.657371 |
0.159405 |
0.411765 |
0.098832 |
0.181039 |
0.028717 |
0.021437 |
0.002918 |
| 20113 |
0.476096 |
0.573858 |
0.313725 |
0.003124 |
0.205942 |
0.116642 |
0.182806 |
0.001495 |
| 14289 |
0.719124 |
0.021254 |
0.882353 |
0.116264 |
0.148998 |
0.027594 |
0.022275 |
0.001099 |
| 13665 |
0.701195 |
0.157279 |
0.333333 |
0.046703 |
0.325099 |
0.034645 |
0.018619 |
0.001981 |
| 14471 |
0.709163 |
0.036132 |
0.333333 |
0.239599 |
0.093661 |
0.021064 |
0.019905 |
0.002922 |