from sklearn.compose import ColumnTransformerColumnTransformer
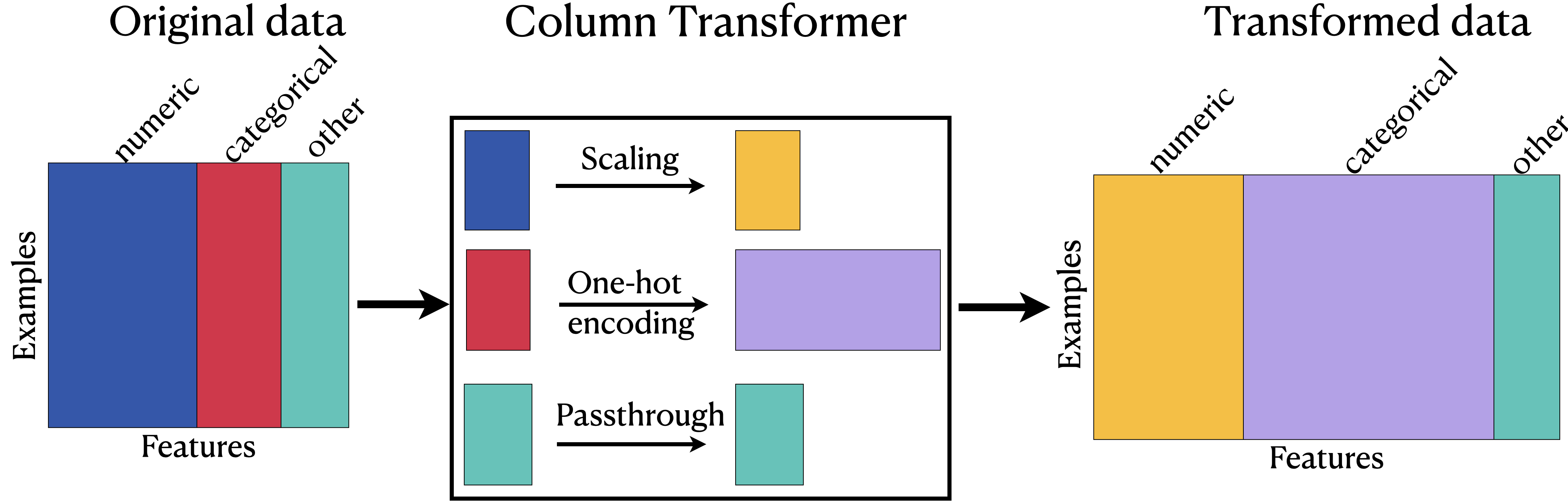
Problem: We have different transformations for different columns
Before we fit our model, we want to apply different transformations on different columns.
- Numeric columns:
- imputation
- scaling
- Categorical columns:
- imputation
- one-hot encoding
- imputation
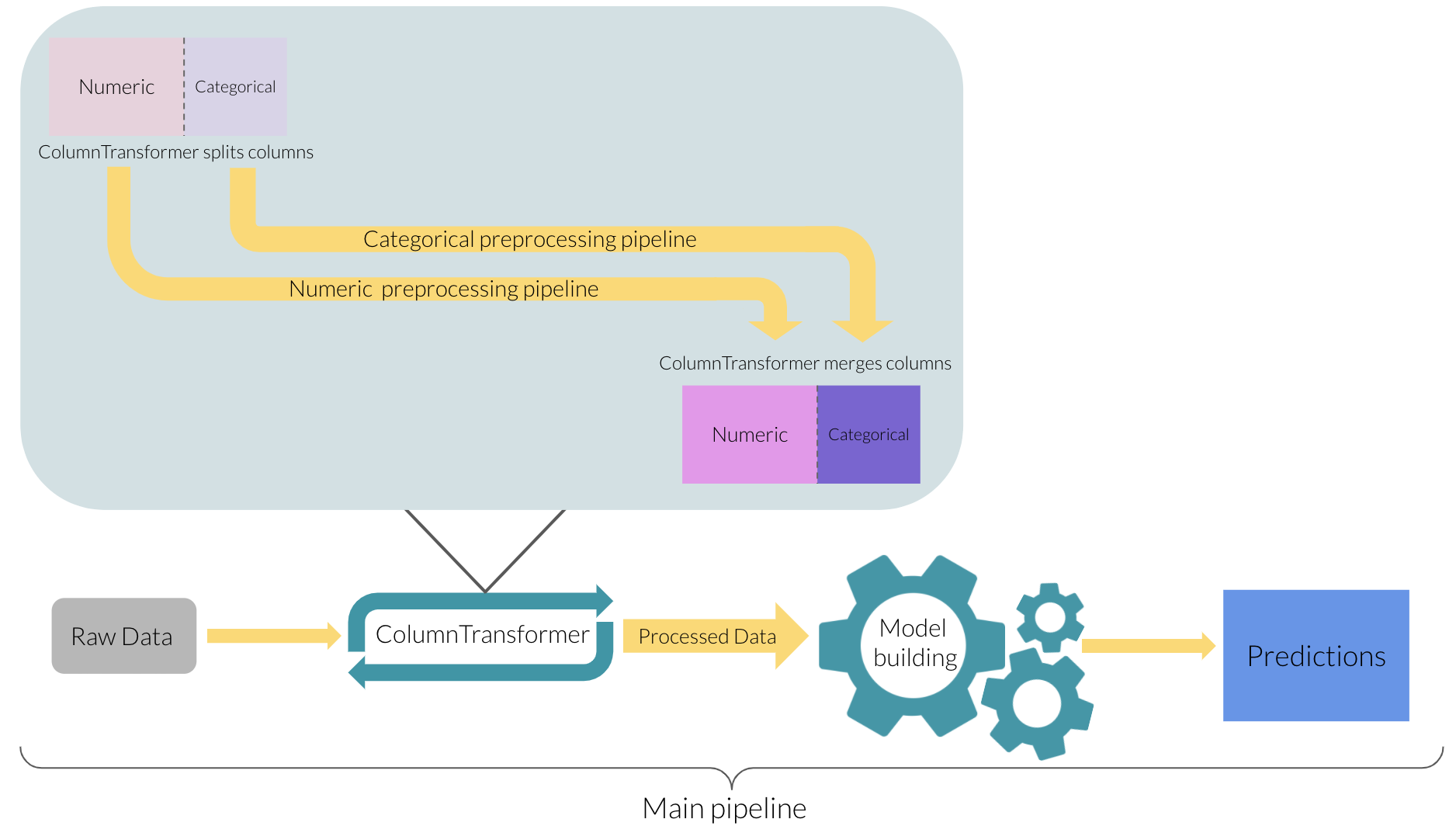
ColumnTransformer
| longitude | latitude | housing_median_age | households | ... | ocean_proximity | rooms_per_household | bedrooms_per_household | population_per_household | |
|---|---|---|---|---|---|---|---|---|---|
| 6051 | -117.75 | 34.04 | 22.0 | 602.0 | ... | INLAND | 4.897010 | 1.056478 | 4.318937 |
| 20113 | -119.57 | 37.94 | 17.0 | 20.0 | ... | INLAND | 17.300000 | 6.500000 | 2.550000 |
| 14289 | -117.13 | 32.74 | 46.0 | 708.0 | ... | NEAR OCEAN | 4.738701 | 1.084746 | 2.057910 |
| 13665 | -117.31 | 34.02 | 18.0 | 285.0 | ... | INLAND | 5.733333 | 0.961404 | 3.154386 |
| 14471 | -117.23 | 32.88 | 18.0 | 1458.0 | ... | NEAR OCEAN | 3.817558 | 1.004801 | 4.323045 |
5 rows × 9 columns
longitude float64
latitude float64
housing_median_age float64
...
rooms_per_household float64
bedrooms_per_household float64
population_per_household float64
Length: 9, dtype: objectfrom sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
numeric_transformer = Pipeline(
steps=[("imputer", SimpleImputer(strategy="median")),
("scaler", StandardScaler())]
)
categorical_transformer = Pipeline(
steps=[("imputer", SimpleImputer(strategy="constant", fill_value="missing")),
("onehot", OneHotEncoder(handle_unknown="ignore"))]
)ColumnTransformer(remainder='passthrough',
transformers=[('numeric',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='median')),
('scaler', StandardScaler())]),
['longitude', 'latitude', 'housing_median_age',
'households', 'median_income',
'rooms_per_household',
'bedrooms_per_household',
'population_per_household']),
('categorical',
Pipeline(steps=[('imputer',
SimpleImputer(fill_value='missing',
strategy='constant')),
('onehot',
OneHotEncoder(handle_unknown='ignore'))]),
['ocean_proximity'])])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| transformers | [('numeric', ...), ('categorical', ...)] | |
| remainder | 'passthrough' | |
| sparse_threshold | 0.3 | |
| n_jobs | None | |
| transformer_weights | None | |
| verbose | False | |
| verbose_feature_names_out | True | |
| force_int_remainder_cols | 'deprecated' |
['longitude', 'latitude', 'housing_median_age', 'households', 'median_income', 'rooms_per_household', 'bedrooms_per_household', 'population_per_household']
Parameters
| missing_values | nan | |
| strategy | 'median' | |
| fill_value | None | |
| copy | True | |
| add_indicator | False | |
| keep_empty_features | False |
Parameters
| copy | True | |
| with_mean | True | |
| with_std | True |
['ocean_proximity']
Parameters
| missing_values | nan | |
| strategy | 'constant' | |
| fill_value | 'missing' | |
| copy | True | |
| add_indicator | False | |
| keep_empty_features | False |
Parameters
| categories | 'auto' | |
| drop | None | |
| sparse_output | True | |
| dtype | <class 'numpy.float64'> | |
| handle_unknown | 'ignore' | |
| min_frequency | None | |
| max_categories | None | |
| feature_name_combiner | 'concat' |
[]
passthrough
| longitude | latitude | housing_median_age | households | ... | ocean_proximity | rooms_per_household | bedrooms_per_household | population_per_household | |
|---|---|---|---|---|---|---|---|---|---|
| 6051 | -117.75 | 34.04 | 22.0 | 602.0 | ... | INLAND | 4.897010 | 1.056478 | 4.318937 |
| 20113 | -119.57 | 37.94 | 17.0 | 20.0 | ... | INLAND | 17.300000 | 6.500000 | 2.550000 |
| 14289 | -117.13 | 32.74 | 46.0 | 708.0 | ... | NEAR OCEAN | 4.738701 | 1.084746 | 2.057910 |
| 13665 | -117.31 | 34.02 | 18.0 | 285.0 | ... | INLAND | 5.733333 | 0.961404 | 3.154386 |
| 14471 | -117.23 | 32.88 | 18.0 | 1458.0 | ... | NEAR OCEAN | 3.817558 | 1.004801 | 4.323045 |
5 rows × 9 columns
x = list(X_train.columns.values)
del x[5]
X_train_pp = col_transformer.transform(X_train)
pd.DataFrame(X_train_pp, columns= (x + list(col_transformer.named_transformers_["categorical"].named_steps["onehot"].get_feature_names_out(categorical_features)))).head()| longitude | latitude | housing_median_age | households | ... | ocean_proximity_INLAND | ocean_proximity_ISLAND | ocean_proximity_NEAR BAY | ocean_proximity_NEAR OCEAN | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.908140 | -0.743917 | -0.526078 | 0.266135 | ... | 1.0 | 0.0 | 0.0 | 0.0 |
| 1 | -0.002057 | 1.083123 | -0.923283 | -1.253312 | ... | 1.0 | 0.0 | 0.0 | 0.0 |
| 2 | 1.218207 | -1.352930 | 1.380504 | 0.542873 | ... | 0.0 | 0.0 | 0.0 | 1.0 |
| 3 | 1.128188 | -0.753286 | -0.843842 | -0.561467 | ... | 1.0 | 0.0 | 0.0 | 0.0 |
| 4 | 1.168196 | -1.287344 | -0.843842 | 2.500924 | ... | 0.0 | 0.0 | 0.0 | 1.0 |
5 rows × 13 columns
onehot_cols = col_transformer.named_transformers_["categorical"].named_steps["onehot"].get_feature_names_out(categorical_features)
onehot_colsarray(['ocean_proximity_<1H OCEAN', 'ocean_proximity_INLAND', 'ocean_proximity_ISLAND', 'ocean_proximity_NEAR BAY', 'ocean_proximity_NEAR OCEAN'], dtype=object)['longitude',
'latitude',
'housing_median_age',
'households',
'median_income',
'rooms_per_household',
'bedrooms_per_household',
'population_per_household',
'ocean_proximity_<1H OCEAN',
'ocean_proximity_INLAND',
'ocean_proximity_ISLAND',
'ocean_proximity_NEAR BAY',
'ocean_proximity_NEAR OCEAN']from sklearn.model_selection import cross_validate
with_categorical_scores = cross_validate(main_pipe, X_train, y_train, return_train_score=True)
pd.DataFrame(with_categorical_scores)| fit_time | score_time | test_score | train_score | |
|---|---|---|---|---|
| 0 | 0.031270 | 0.259699 | 0.695818 | 0.801659 |
| 1 | 0.031045 | 0.251676 | 0.707483 | 0.799575 |
| 2 | 0.030849 | 0.257668 | 0.713788 | 0.795944 |
| 3 | 0.030219 | 0.262499 | 0.686938 | 0.801232 |
| 4 | 0.030064 | 0.216829 | 0.724608 | 0.832498 |
no_categorical_scores = cross_validate(pipe, X_train.drop(columns=['ocean_proximity']), y_train, return_train_score=True)
pd.DataFrame(no_categorical_scores)| fit_time | score_time | test_score | train_score | |
|---|---|---|---|---|
| 0 | 0.019661 | 0.168070 | 0.693883 | 0.792395 |
| 1 | 0.019378 | 0.159174 | 0.685017 | 0.789108 |
| 2 | 0.018734 | 0.162906 | 0.694409 | 0.787796 |
| 3 | 0.019095 | 0.167182 | 0.677055 | 0.792444 |
| 4 | 0.018919 | 0.134032 | 0.714494 | 0.823421 |
fit_time 0.019158
score_time 0.158273
test_score 0.692972
train_score 0.797033
dtype: float64Pipeline(steps=[('preprocessor',
ColumnTransformer(remainder='passthrough',
transformers=[('numeric',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='median')),
('scaler',
StandardScaler())]),
['longitude', 'latitude',
'housing_median_age',
'households',
'median_income',
'rooms_per_household',
'bedrooms_per_household',
'population_per_household']),
('categorical',
Pipeline(steps=[('imputer',
SimpleImputer(fill_value='missing',
strategy='constant')),
('onehot',
OneHotEncoder(handle_unknown='ignore'))]),
['ocean_proximity'])])),
('reg', KNeighborsRegressor())])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| steps | [('preprocessor', ...), ('reg', ...)] | |
| transform_input | None | |
| memory | None | |
| verbose | False |
Parameters
| transformers | [('numeric', ...), ('categorical', ...)] | |
| remainder | 'passthrough' | |
| sparse_threshold | 0.3 | |
| n_jobs | None | |
| transformer_weights | None | |
| verbose | False | |
| verbose_feature_names_out | True | |
| force_int_remainder_cols | 'deprecated' |
['longitude', 'latitude', 'housing_median_age', 'households', 'median_income', 'rooms_per_household', 'bedrooms_per_household', 'population_per_household']
Parameters
| missing_values | nan | |
| strategy | 'median' | |
| fill_value | None | |
| copy | True | |
| add_indicator | False | |
| keep_empty_features | False |
Parameters
| copy | True | |
| with_mean | True | |
| with_std | True |
['ocean_proximity']
Parameters
| missing_values | nan | |
| strategy | 'constant' | |
| fill_value | 'missing' | |
| copy | True | |
| add_indicator | False | |
| keep_empty_features | False |
Parameters
| categories | 'auto' | |
| drop | None | |
| sparse_output | True | |
| dtype | <class 'numpy.float64'> | |
| handle_unknown | 'ignore' | |
| min_frequency | None | |
| max_categories | None | |
| feature_name_combiner | 'concat' |
[]
passthrough
Parameters
| n_neighbors | 5 | |
| weights | 'uniform' | |
| algorithm | 'auto' | |
| leaf_size | 30 | |
| p | 2 | |
| metric | 'minkowski' | |
| metric_params | None | |
| n_jobs | None |
Do we need to preprocess categorical values in the target column?
- Generally, there is no need for this when doing classification.
sklearnis fine with categorical labels (y-values) for classification problems.