X = [
"URGENT!! As a valued network customer you have been selected to receive a £900 prize reward!",
"Lol you are always so convincing.",
"Nah I don't think he goes to usf, he lives around here though",
"URGENT! You have won a 1 week FREE membership in our £100000 prize Jackpot!",
"Had your mobile 11 months or more? U R entitled to Update to the latest colour mobiles with camera for Free! Call The Mobile Update Co FREE on 08002986030",
"As per your request 'Melle Melle (Oru Minnaminunginte Nurungu Vettam)' has been set as your callertune for all Callers. Press *9 to copy your friends Callertune"]
y = ["spam", "non spam", "non spam", "spam", "spam", "non spam"]Text Data


Bag of words (BOW) representation
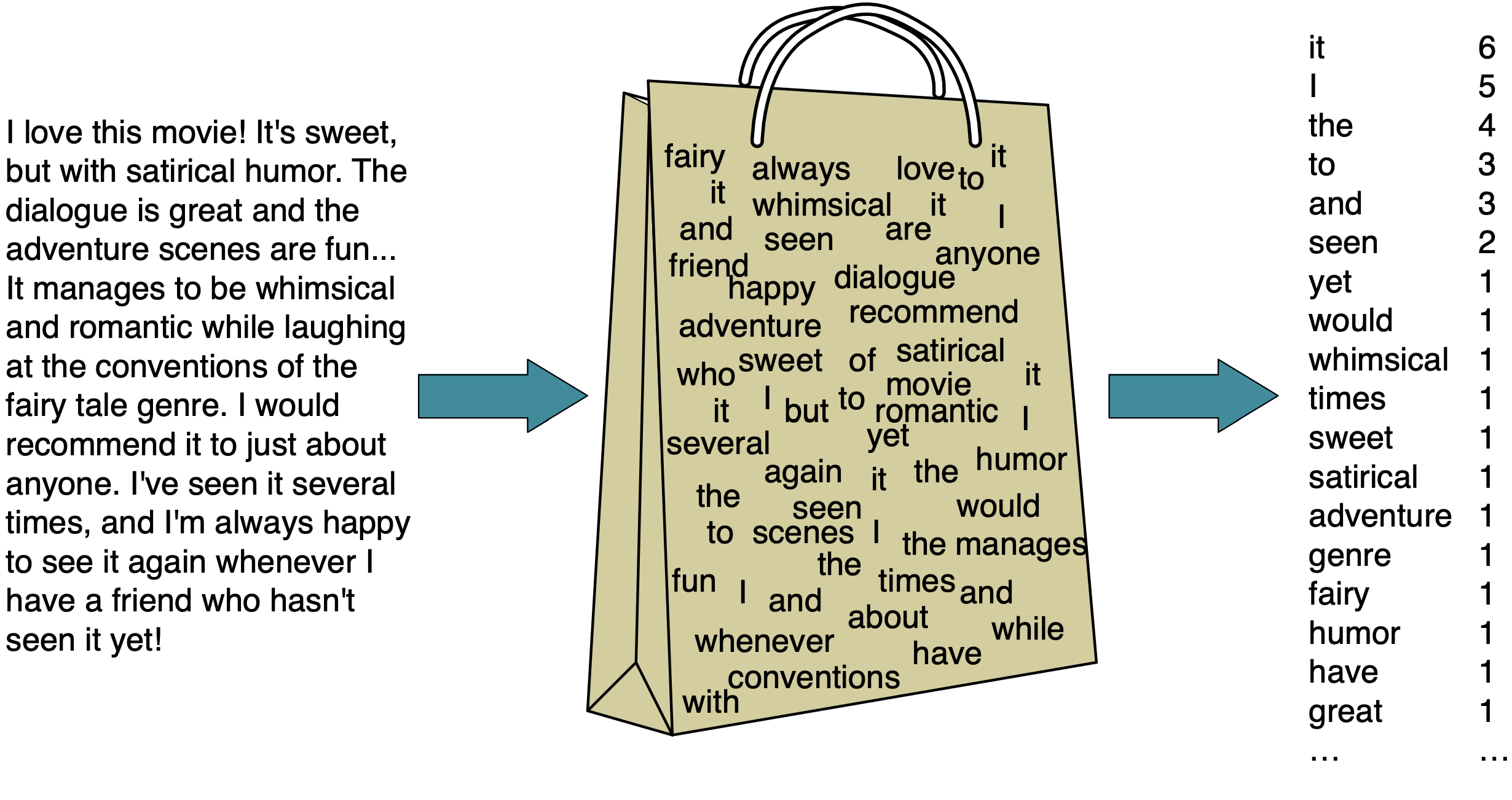
Extracting BOW features using scikit-learn
from sklearn.feature_extraction.text import CountVectorizer
vec = CountVectorizer()
X_counts = vec.fit_transform(X);
bow_df = pd.DataFrame(X_counts.toarray(), columns=sorted(vec.vocabulary_), index=X)
bow_df| 08002986030 | 100000 | 11 | 900 | ... | with | won | you | your | |
|---|---|---|---|---|---|---|---|---|---|
| URGENT!! As a valued network customer you have been selected to receive a £900 prize reward! | 0 | 0 | 0 | 1 | ... | 0 | 0 | 1 | 0 |
| Lol you are always so convincing. | 0 | 0 | 0 | 0 | ... | 0 | 0 | 1 | 0 |
| Nah I don't think he goes to usf, he lives around here though | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 |
| URGENT! You have won a 1 week FREE membership in our £100000 prize Jackpot! | 0 | 1 | 0 | 0 | ... | 0 | 1 | 1 | 0 |
| Had your mobile 11 months or more? U R entitled to Update to the latest colour mobiles with camera for Free! Call The Mobile Update Co FREE on 08002986030 | 1 | 0 | 1 | 0 | ... | 1 | 0 | 0 | 1 |
| As per your request 'Melle Melle (Oru Minnaminunginte Nurungu Vettam)' has been set as your callertune for all Callers. Press *9 to copy your friends Callertune | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 3 |
6 rows × 72 columns
Important hyperparameters of CountVectorizer
binary:- Whether to use absence/presence feature values or counts.
max_features:- Only considers top
max_featuresordered by frequency in the corpus.
- Only considers top
max_df:- When building the vocabulary ignore terms that have a document frequency strictly higher than the given threshold.
min_df:- When building the vocabulary ignore terms that have a document frequency strictly lower than the given threshold.
ngram_range:- Consider word sequences in the given range.
Preprocessing
[ "URGENT!! As a valued network customer you have been selected to receive a £900 prize reward!",
"Lol you are always so convincing.",
"Nah I don't think he goes to usf, he lives around here though",
"URGENT! You have won a 1 week FREE membership in our £100000 prize Jackpot!",
"Had your mobile 11 months or more? U R entitled to Update to the latest colour mobiles with camera for Free! Call The Mobile Update Co FREE on 08002986030",
"As per your request 'Melle Melle (Oru Minnaminunginte Nurungu Vettam)' has been set as your callertune for all Callers. Press *9 to copy your friends Callertune"]Preprocessing
array(['08002986030', '100000', '11', '900', 'all', 'always', 'are', 'around', 'as', 'been', 'call', 'callers', 'callertune', 'camera', 'co', 'colour', 'convincing', 'copy', 'customer', 'don', 'entitled', 'for', 'free', 'friends', 'goes', 'had', 'has', 'have', 'he', 'here', 'in', 'jackpot', 'latest', 'lives', 'lol', 'melle', 'membership', 'minnaminunginte', 'mobile', 'mobiles', 'months', 'more',
'nah', 'network', 'nurungu', 'on', 'or', 'oru', 'our', 'per', 'press', 'prize', 'receive', 'request', 'reward', 'selected', 'set', 'so', 'the', 'think', 'though', 'to', 'update', 'urgent', 'usf', 'valued', 'vettam', 'week', 'with', 'won', 'you', 'your'], dtype=object)X_new = [
"Congratulations! You have been awarded $1000!",
"Mom, can you pick me up from soccer practice?",
"I'm trying to bake a cake and I forgot to put sugar in it smh. ",
"URGENT: please pick up your car at 2pm from servicing",
"Call 234950323 for a FREE consultation. It's your lucky day!" ]
y_new = ["spam", "non spam", "non spam", "non spam", "spam"]Is this a realistic representation of text data?
Of course, this is not a great representation of language.
- We are throwing out everything we know about language and losing a lot of information.
- It assumes that there is no syntax and compositional meaning in language.
…But it works surprisingly well for many tasks.