from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.tree import DecisionTreeClassifier
pipe_tree = make_pipeline(
(StandardScaler()),
(DecisionTreeClassifier(random_state=123))
)Precision, Recall and F1 Score
Recall
Among all positive examples, how many did you identify?
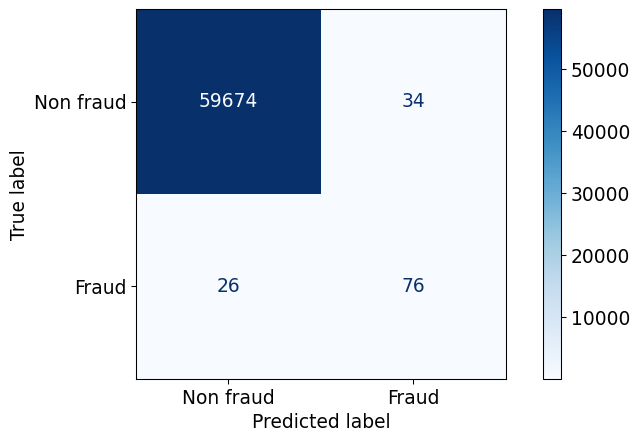
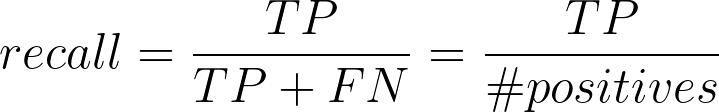
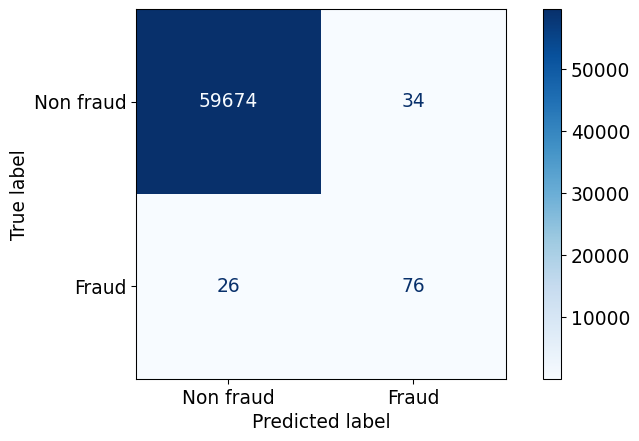
confusion_matrix(y_valid, predictions)array([[59674, 34],
[ 26, 76]])TN, FP, FN, TP = confusion_matrix(y_valid, predictions).ravel()recall = TP / (TP + FN)
recall.round(4)np.float64(0.7451)Precision
Among the positive examples you identified, how many were actually positive?
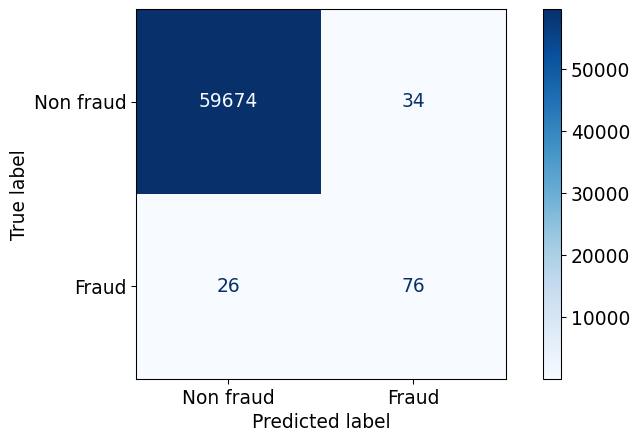
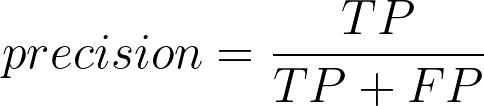
confusion_matrix(y_valid, predictions)array([[59674, 34],
[ 26, 76]])TN, FP, FN, TP = confusion_matrix(y_valid, predictions).ravel()precision = TP / (TP + FP)
precision.round(4)np.float64(0.6909)f1
f1-score combines precision and recall to give one score.
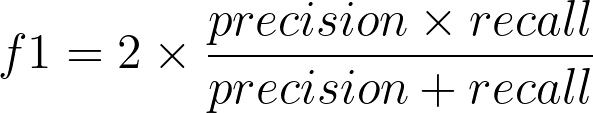
precisionnp.float64(0.6909090909090909)recallnp.float64(0.7450980392156863)f1_score = (2 * precision * recall) / (precision + recall)
f1_scorenp.float64(0.7169811320754716)