from sklearn.metrics import classification_report
print(classification_report(y_valid, pipe_tree.predict(X_valid),
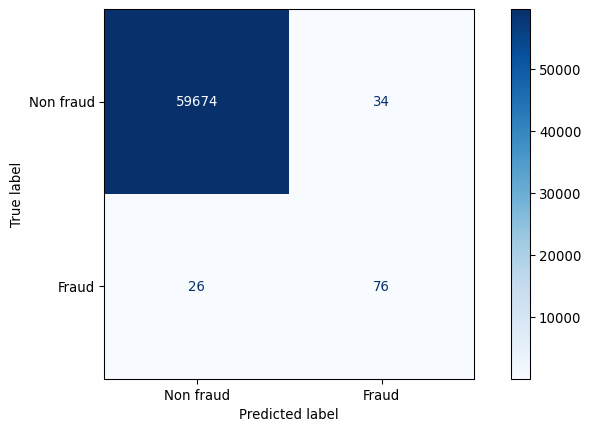
target_names=["non-fraud", "fraud"])) precision recall f1-score support
non-fraud 1.00 1.00 1.00 59708
fraud 0.69 0.75 0.72 102
accuracy 1.00 59810
macro avg 0.85 0.87 0.86 59810
weighted avg 1.00 1.00 1.00 59810