from sklearn.model_selection import train_test_split
housing_df = pd.read_csv("data/housing.csv")
train_df, test_df = train_test_split(housing_df, test_size=0.1, random_state=123)Regression Measurements
X_train = train_df.drop(columns=["median_house_value"])
y_train = train_df["median_house_value"]
X_test = test_df.drop(columns=["median_house_value"])
y_test = test_df["median_house_value"]
numeric_features = [ "longitude", "latitude",
"housing_median_age",
"households", "median_income",
"rooms_per_household",
"bedrooms_per_household",
"population_per_household"]
categorical_features = ["ocean_proximity"]
X_train.head(3)| longitude | latitude | housing_median_age | households | ... | ocean_proximity | rooms_per_household | bedrooms_per_household | population_per_household | |
|---|---|---|---|---|---|---|---|---|---|
| 6051 | -117.75 | 34.04 | 22.0 | 602.0 | ... | INLAND | 4.897010 | 1.056478 | 4.318937 |
| 20113 | -119.57 | 37.94 | 17.0 | 20.0 | ... | INLAND | 17.300000 | 6.500000 | 2.550000 |
| 14289 | -117.13 | 32.74 | 46.0 | 708.0 | ... | NEAR OCEAN | 4.738701 | 1.084746 | 2.057910 |
3 rows × 9 columns
numeric_transformer = Pipeline(
steps=[("imputer", SimpleImputer(strategy="median")),
("scaler", StandardScaler())]
)
categorical_transformer = Pipeline(
steps=[("imputer", SimpleImputer(strategy="constant", fill_value="missing")),
("onehot", OneHotEncoder(handle_unknown="ignore"))]
)
preprocessor = make_column_transformer(
(numeric_transformer, numeric_features),
(categorical_transformer, categorical_features),
remainder='passthrough')
pipe = make_pipeline(preprocessor, KNeighborsRegressor())
pipe.fit(X_train, y_train);6051 False
20113 False
14289 False
...
17730 False
15725 False
19966 False
Name: median_house_value, Length: 18576, dtype: boolRegression measurements
The scores we are going to discuss are:
- mean squared error (MSE)
- R2
- root mean squared error (RMSE)
- MAPE
If you want to see these in more detail, you can refer to the sklearn documentation.
Mean squared error (MSE)


R2 (quick notes)
Key points:
- The maximum value possible is 1 which means the model has perfect predictions.
- Negative values are very bad: “worse than baseline models such as
DummyRegressor”.
2570054492.048064
2570054492.0480640.8059396097446094
0.742915970464153Root mean squared error (RMSE)


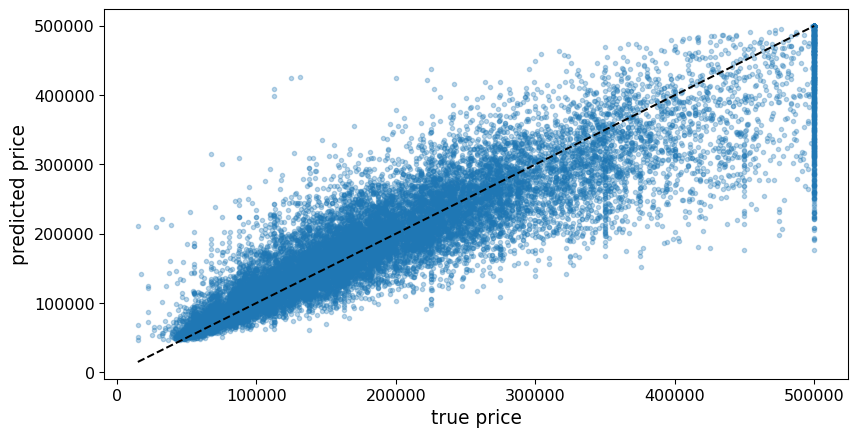
MAPE - Mean Absolute Percent Error (MAPE)
6051 -1.637324
20113 -14.632727
14289 10.346855
13665 6.713070
14471 -10.965854
Name: median_house_value, dtype: float646051 1.637324
20113 14.632727
14289 10.346855
13665 6.713070
14471 10.965854
Name: median_house_value, dtype: float64