predicted(price) = coefficientbedrooms x #bedrooms + coefficientbathrooms x #bathrooms + coefficientsqfeet x #sqfeet + coefficientage x age + intercept
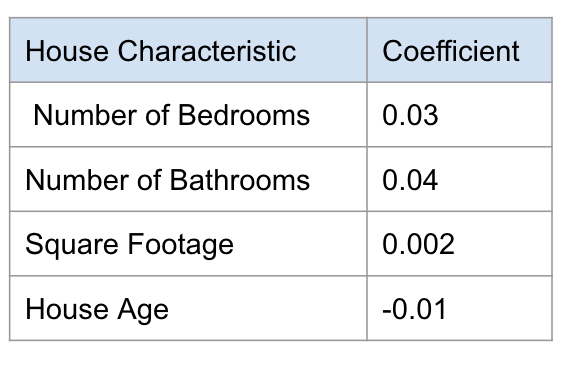
predicted(price) = 0.03 x #bedrooms + 0.04 x #bathrooms + 0.002 x #sqfeet + -0.01 x #age + intercept
predicted(price) = (0.03 x 3) + (0.04 x 2) + (0.002 x 1875) + (-0.01 x 66) + 0
predicted(price) = 3.26
Components of a linear model
predicted(price) = (coefficientbedrooms x #bedrooms) + (coefficientbathrooms x #bathrooms) + (coefficientsqfeet x #sqfeet) + (coefficientage x age) + intercept
if the coefficient is +, then ↑ the feature values ↑ the prediction value.
if the coefficient is -, then ↑ the feature values ↓ the prediction value.
if the coefficient is 0, the feature is not used in making a prediction.
Predicting
X_train.iloc[0:1]
house_age
distance_station
num_stores
latitude
longitude
172
6.6
90.45606
9
24.97433
121.5431
lm.predict(X_train.iloc[0:1])
array([52.35605528])
words_coeffs_df.T
house_age
distance_station
num_stores
latitude
longitude
Coefficients
-0.243214
-0.005337
1.258782
8.923536
-1.345233
X_train.iloc[0:1]
house_age
distance_station
num_stores
latitude
longitude
172
6.6
90.45606
9
24.97433
121.5431
intercept = lm.intercept_intercept
np.float64(-16.24051672028149)
predicted(price) = coefficienthouse_age x house_age + coefficientdistance_station x distance_station + coefficientnum_stores x num_stores + coefficientlatitude x latitude + coefficientlongitude x longitude + intercept