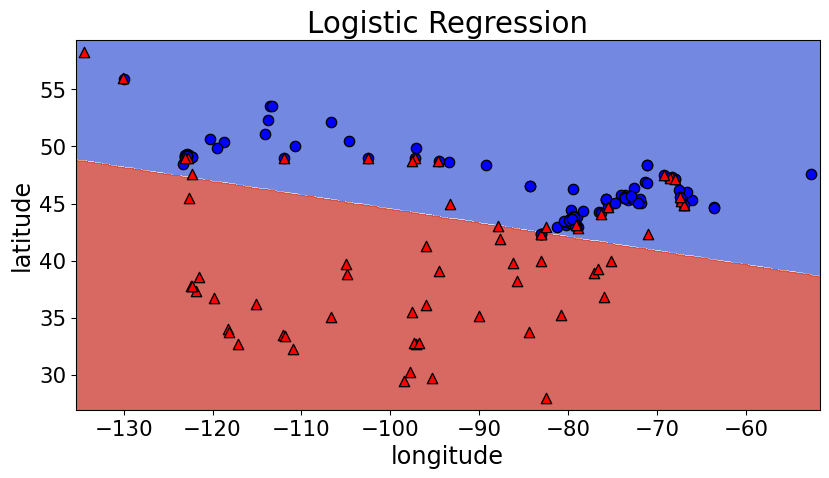
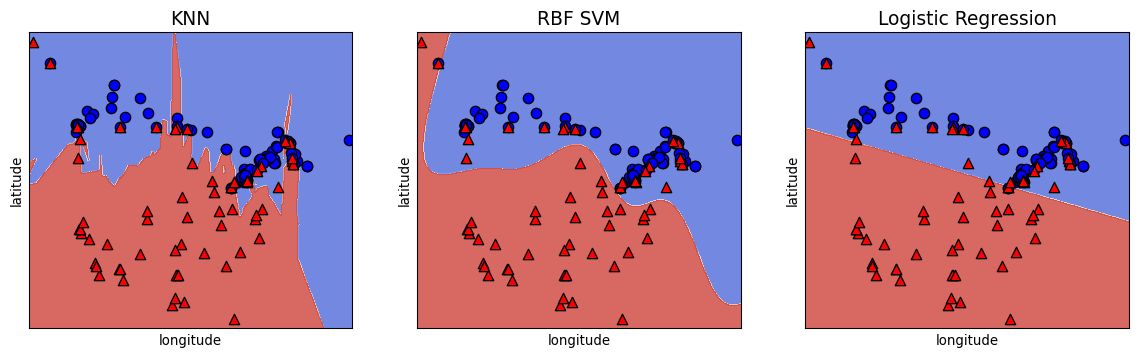
Fitting 5 folds for each of 10 candidates, totalling 50 fits
grid_search.best_params_
{'C': np.float64(1.5229072268322374)}
grid_search.best_score_
np.float64(0.8201426024955436)
Logistic regression with text data
X = ["URGENT!! As a valued network customer you have been selected to receive a £900 prize reward!","Lol you are always so convincing.","Nah I don't think he goes to usf, he lives around here though","URGENT! You have won a 1 week FREE membership in our £100000 prize Jackpot!","Had your mobile 11 months or more? U R entitled to Update to the latest colour mobiles with camera for Free! Call The Mobile Update Co FREE on 08002986030","As per your request 'Melle Melle (Oru Minnaminunginte Nurungu Vettam)' has been set as your callertune for all Callers. Press *9 to copy your friends Callertune"]y = ["spam", "non spam", "non spam", "spam", "spam", "non spam"]
URGENT!! As a valued network customer you have been selected to receive a £900 prize reward!
0
0
0
1
...
0
0
1
0
Lol you are always so convincing.
0
0
0
0
...
0
0
1
0
Nah I don't think he goes to usf, he lives around here though
0
0
0
0
...
0
0
0
0
URGENT! You have won a 1 week FREE membership in our £100000 prize Jackpot!
0
1
0
0
...
0
1
1
0
Had your mobile 11 months or more? U R entitled to Update to the latest colour mobiles with camera for Free! Call The Mobile Update Co FREE on 08002986030
1
0
1
0
...
1
0
0
1
As per your request 'Melle Melle (Oru Minnaminunginte Nurungu Vettam)' has been set as your callertune for all Callers. Press *9 to copy your friends Callertune