from sklearn.model_selection import train_test_split cities_df = pd.read_csv("data/canada_usa_cities.csv") train_df, test_df = train_test_split(cities_df, test_size=0.2, random_state=123) X_train, y_train = train_df.drop(columns=["country"], axis=1), train_df["country"] X_test, y_test = test_df.drop(columns=["country"], axis=1), test_df["country"] train_df.head()
from sklearn.linear_model import LogisticRegression lr = LogisticRegression() lr.fit(X_train, y_train);
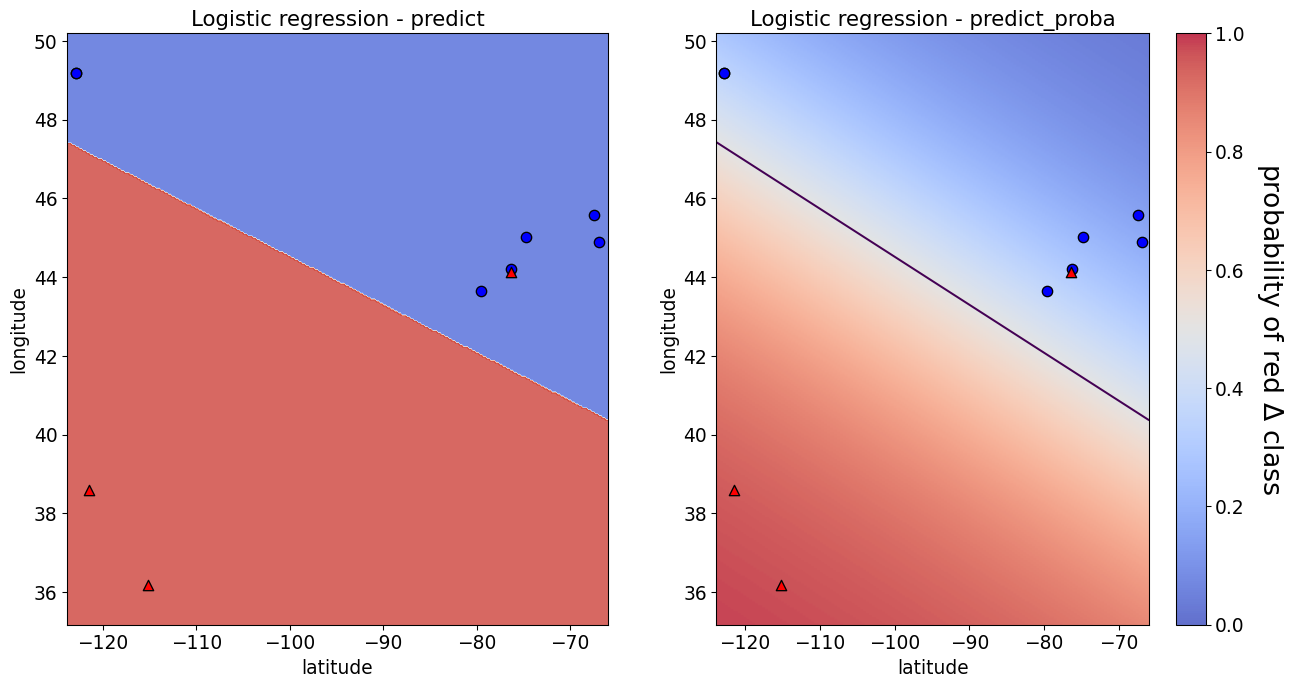
lr.predict(X_test[:1])
array(['Canada'], dtype=object)
lr.predict_proba(X_test[:1])
array([[0.87849316, 0.12150684]])
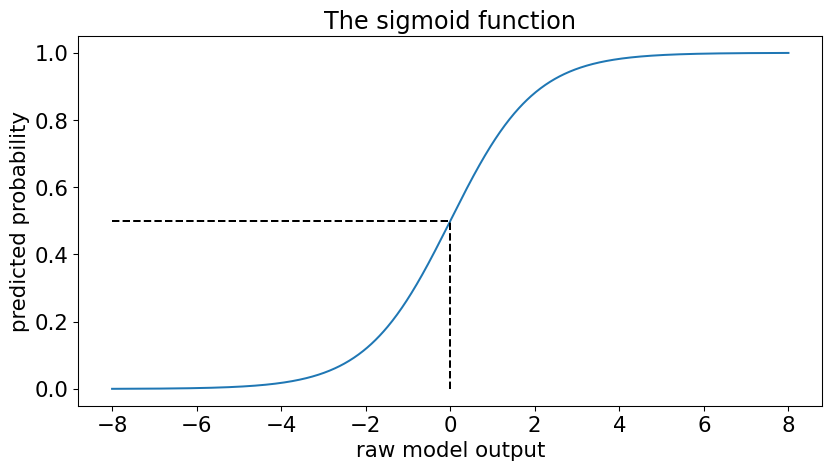
For linear regression we used something like this:
predicted(value) = coefficientfeature1 x feature1 + coefficientfeature2 x feature2 + … + intercept
But this won’t work with probabilities.
predict_y = lr.predict(X_train) predict_y[-5:]
array(['Canada', 'Canada', 'USA', 'Canada', 'Canada'], dtype=object)
y_proba = lr.predict_proba(X_train) y_proba[-5:]
array([[0.69849181, 0.30150819], [0.76971285, 0.23028715], [0.05301371, 0.94698629], [0.63295092, 0.36704908], [0.81540984, 0.18459016]])
data_dict = {"y":y_train, "pred y": predict_y.tolist(), "probabilities": y_proba.tolist()} pd.DataFrame(data_dict).tail(10)
10 rows × 3 columns
lr_targets = pd.DataFrame({"y":y_train, "pred y": predict_y.tolist(), "probability_canada": y_proba[:,0].tolist()}) lr_targets.head(3)
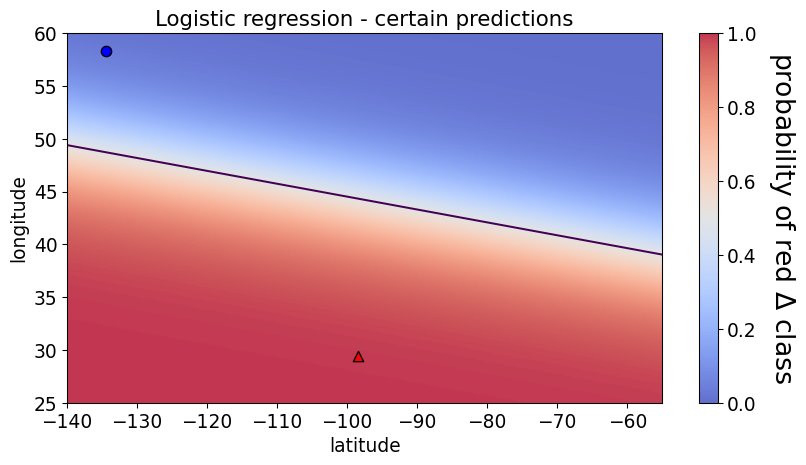
lr_targets.sort_values(by='probability_canada')
167 rows × 3 columns
X_train.loc[[1,37]]
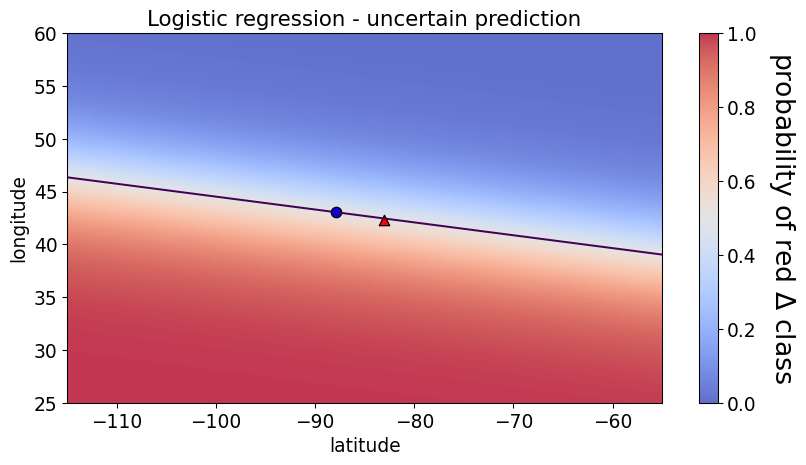
lr_targets = pd.DataFrame({"y":y_train, "pred y": predict_y.tolist(), "prob_difference": (abs(y_proba[:,0] - y_proba[:,1])).tolist()}) lr_targets.sort_values(by="prob_difference").head()
X_train.loc[[61, 54]]