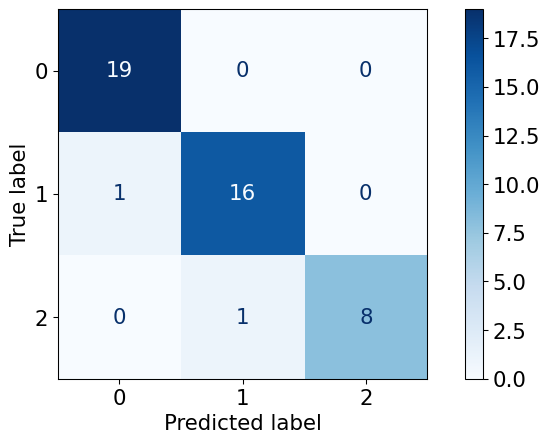
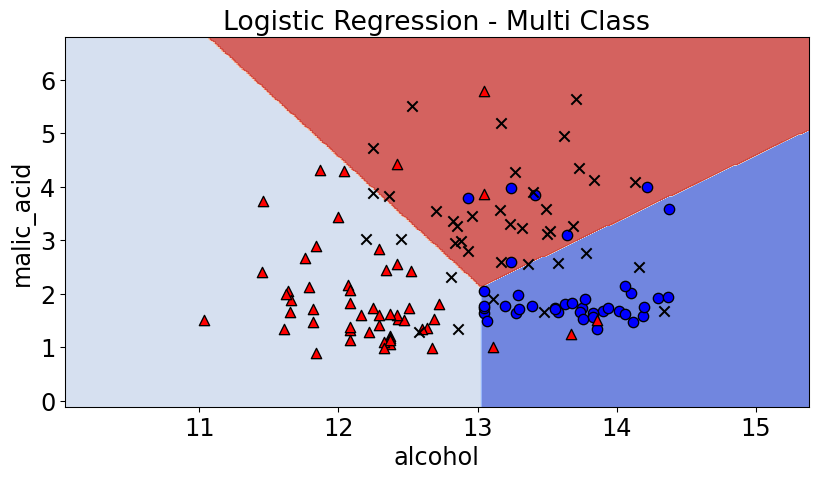
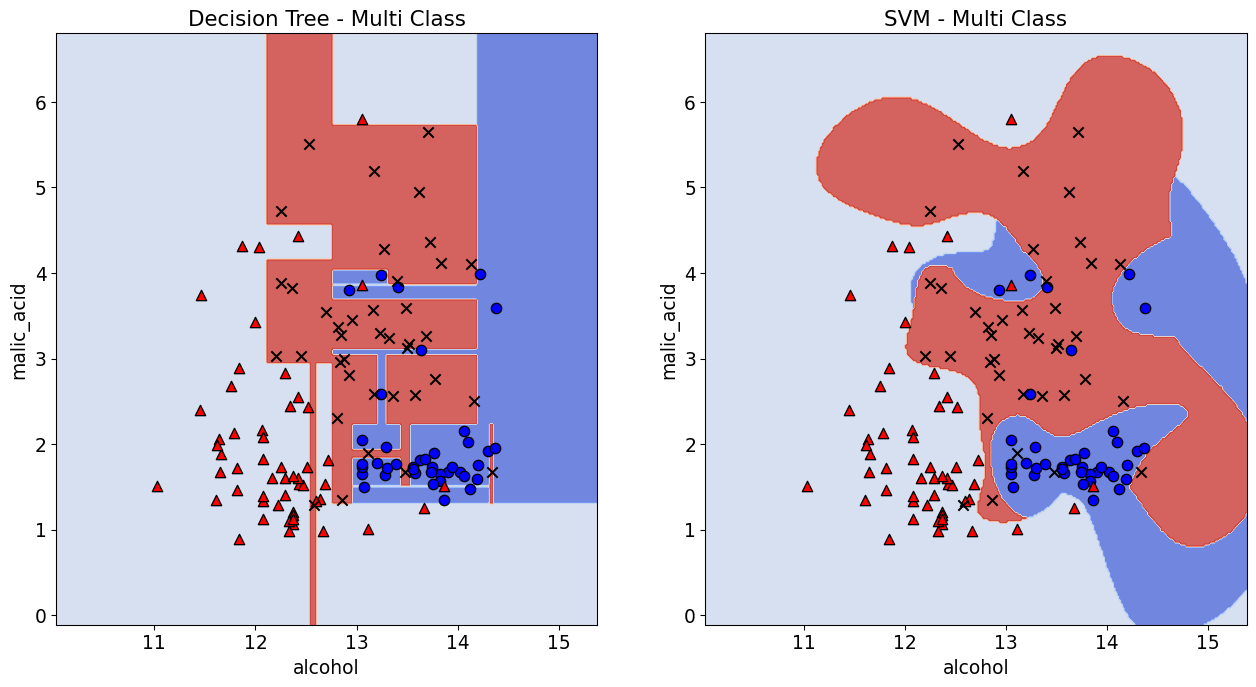
from sklearn import datasets
from sklearn.model_selection import train_test_split
data = datasets.load_wine()
X = pd.DataFrame(data['data'], columns=data["feature_names"])
y = data['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=2021)
X_train.head()| alcohol | malic_acid | ash | alcalinity_of_ash | ... | color_intensity | hue | od280/od315_of_diluted_wines | proline | |
|---|---|---|---|---|---|---|---|---|---|
| 36 | 13.28 | 1.64 | 2.84 | 15.5 | ... | 4.60 | 1.09 | 2.78 | 880.0 |
| 77 | 11.84 | 2.89 | 2.23 | 18.0 | ... | 2.65 | 0.96 | 2.52 | 500.0 |
| 131 | 12.88 | 2.99 | 2.40 | 20.0 | ... | 5.40 | 0.74 | 1.42 | 530.0 |
| 159 | 13.48 | 1.67 | 2.64 | 22.5 | ... | 11.75 | 0.57 | 1.78 | 620.0 |
| 4 | 13.24 | 2.59 | 2.87 | 21.0 | ... | 4.32 | 1.04 | 2.93 | 735.0 |
5 rows × 13 columns