sample_n30 <- tibble(values = c(
24.9458614574341, 7.23174970992907, 4.16136401519179, 5.60304128237143,
5.37929488345981, 1.40547217217847, 7.0701988485075, 2.84055356831115,
0.894746121019125, 2.9016381111011, 3.19011222943664, 11.0930137682099,
3.49700326472521, 46.2914818498428, 2.00653892990149, 2.87363994969391,
11.4050390862658, 11.6616687767937, 12.8855835341646, 3.88483320176601,
0.406148910522461, 25.7642258988289, 8.4743227359272, 4.17410666868091,
1.84968510270119, 2.15972620035141, 10.5289600339151, 6.44162824716339,
10.6035323139645, 66.6861112673485
))Lecture 7: Maximum Likelihood Estimation
1 Slides
2 Learning Goals
By the end of this lecture, you should be able to:
- Explain the concept of a random sample.
- Explain the concept of maximum likelihood estimation.
- Define the likelihood function for a parametric model and recall why we often take its logarithm.
- Apply maximum likelihood estimation for cases with one population parameter (i.e., univariate maximum likelihood estimation).
- Use
Rto implement maximum likelihood estimation by an empirical approach.
Warning
Let us make a note on plotting. You are not expected to create plots like those in these lecture notes. You will check different plotting techniques until DSCI 531: Data Visualization I.
It is time to delve into a fascinating statistical concept: estimating distributional parameters in a population or system using sample data. Today’s lecture will focus on maximum likelihood estimation (MLE) as a fundamental tool in this process. MLE is closely connected to the probabilistic concepts we have been discussing over the past six lectures in this block. As a result, we will partially transition from the realm of probability to the realm of inference. However, we will only cover parameter estimation in today’s lecture.
We will start with a statistical concept on which classical MLE relies heavily: a random sample. Note that this concept carries forward the notion of independence in random variables.
3 Random Samples
Let us start with the formal definition of a random sample.
Definition of Random Sample
A random sample is a collection of random outcomes/variables. Using mathematical notation, a random sample of size \(n\) is usually depicted with random variables \(X_1, \ldots, X_n\). We think of data as being a random sample.
Unless we make additional sampling assumptions, a default random sample is said to be independent and identically distributed (or iid) if:
- Each pair of observations are independent, and
- each observation comes from the same distribution.
Important
Why is sampling important in statistical practice? Well, populations or systems of interest are governed by fixed parameters (under a frequentist paradigm) since we assume that the data from these populations or systems of interest can be modelled via diverse discrete and/or continuous distributions. These parameters are considered to be the true ones. Within these parameters, you could encounter measures of central tendency, e.g., the mean \(\mu\) of the Normal distribution or the mean \(\beta\) of the Exponential distribution. Also, one could encounter measures of uncertainty such as the variance \(\sigma^2\) of the Normal distribution.
We will never know these true parameters in practice, but we aim to estimate them via sampled data collected from these populations or systems of interest. Using our observed sampled data, we can perform the corresponding parameter estimation via MLE (for instance!) and then proceed to statistical inference (i.e., the topics from DSCI 552: Statistical Inference and Computation I).
4 Estimating true parameters!
As previously discussed, we can use MLE to estimate the true parameters from a given population or system of interest. This method heavily relies on a random sample of \(n\) observations from the population or system of interest. There could be cases with only one parameter; therefore, we will apply univariate MLE. On the other hand, we might encounter cases involving more than one parameter to estimate; this is called multivariate MLE.
MLE provides you with a great way to find estimators, which are usually well-behaved (asymptotically speaking, i.e., when we collect a large enough number of data points \(n\)). Finding good estimators is a difficult task. For example, the sample mean
\[\bar{Y} = \sum_{i = 1}^n \frac{Y_i}{n}\]
is a trivial case with a very intuitive answer. Still, as we will see in today’s MLE, this intuitive answer is backed up with interesting statistical modelling assumptions.
On the other hand, in practical contexts involving more than one variable, you are trying to estimate something much more complex. For example \(\beta_0\) and \(\beta_1\) from a linear regression model:
\[Y = \beta_0 + \beta_1 X_1 + \varepsilon.\]
How would you estimate these parameters when \(\varepsilon \sim \mathcal{N}(0, \sigma^2)\)? MLE can help with that! It is an alternative to least squares estimation (to be seen in DSCI 561: Regression I). In more complex regression frameworks, such as generalized linear models (GLMs) to be covered in DSCI 562: Regression II, MLE is the go-to parameter estimation method.
Important
Since the scope of this lecture is mostly about the conceptual understanding of the MLE process regarding distributional parameters, we will narrow down the attention to univariate cases. This also extends to lab4 and quiz2. That said, in day-to-day statistical practice, this conceptual understanding can also be extended to multivariate cases for more complex data modelling.
4.1 A first example!
Suppose we have an empirical distribution of standard deviations of gene expression for different genes. This empirical distribution corresponds to a random sample of standard deviations. Moreover, we would like to estimate the parameters from the population this sample is coming from!
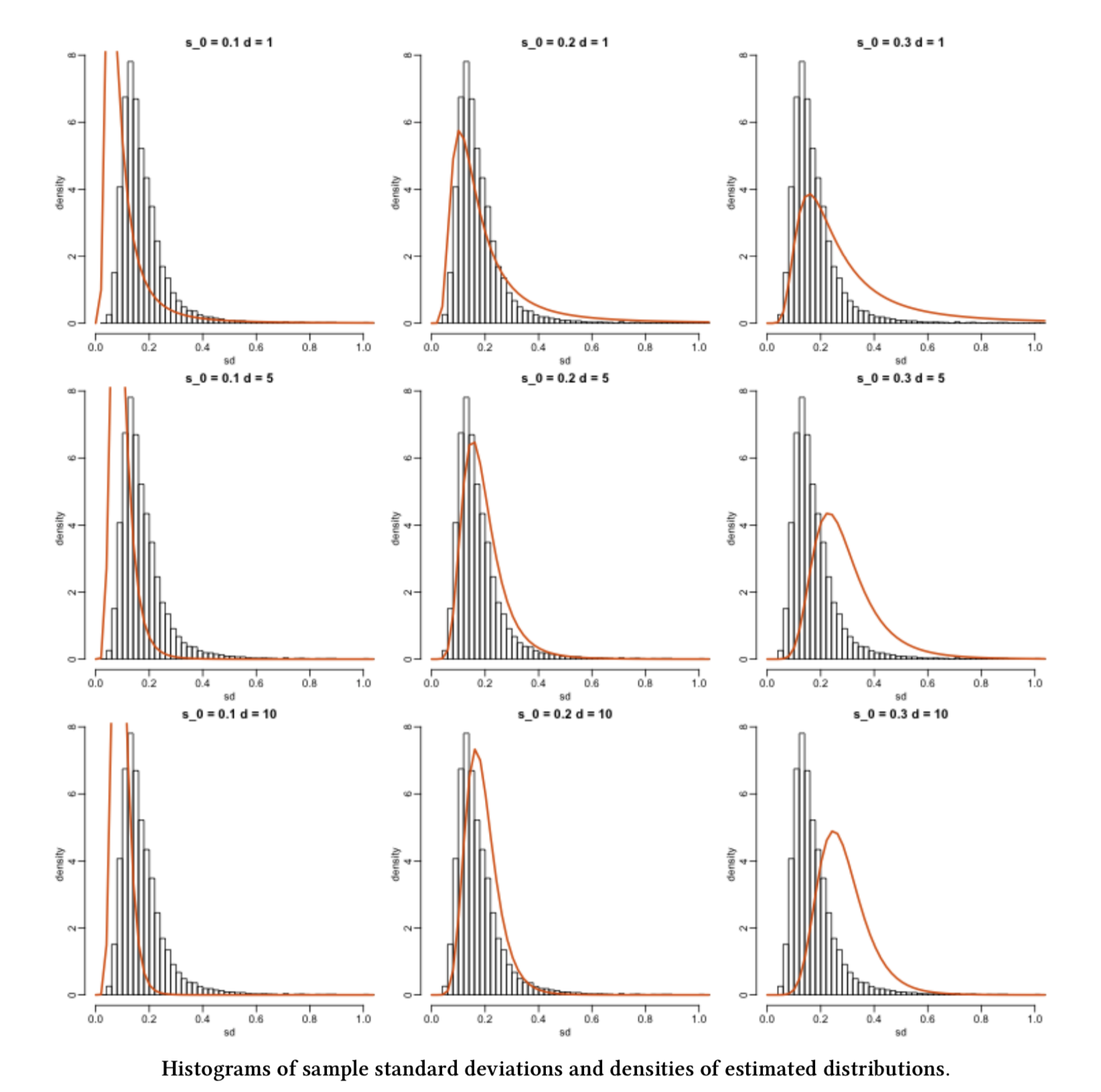
4.2 How can we do this?
Figure 1 gives us some ideas. First, note that the same histogram corresponding to the observed random sample appears in each grid cell. Second, each orange line represents a given theoretical probability density function (PDF) under specific population parameters.
Now, we might wonder: what orange line fits the histogram better? Or in other words, what orange line makes the observed sample THE MOST LIKELY?
The question above is the intuition of MLE!
5 What is the definition of MLE?
MLE is a method that, given some observed data and some assumed family of probability distributions, seeks to find values of the parameters that would make the observed data most likely to have occurred.
Alternatively: MLE is a method that, given some observed data and some assumed family of probability distributions, seeks to find the distribution that would make the observed data most likely to have occurred. The distributional parameters specify this distribution.
These are the EMPIRICAL steps we follow for our previous example using MLE:
Firstly, we choose a family of theoretical distributions that we assume our observed sample data comes from. Here, we chose an \(F\)-distribution.
Next, we vary the parameter(s) for that parametric family of theoretical distributions to find a specific, single distribution that best fits the observed data. This resembles a trial and error approach.
In our previous example, from the histograms, can we do it just by eyeballing it? Not precisely!
So how can we do this? MLE is one way and it involves, as the name says, finding a maximum likelihood. Let us now explore how this is achieved.
5.1 Some key ideas…
Let us explore some further key ideas on the process behind MLE:
- One crucial element to consider is the nature of our variable of interest (is it continuous or discrete?).
- Then, we aim to estimate the parameters of a theoretical distribution (e.g., \(\lambda\) in a Poisson distribution, or \(\mu\) and \(\sigma^2\) in the case of a Normal distribution).
- Therefore, we need to make a distributional assumption for our data – at the family level, i.e., choose a distribution: Normal, Exponential, Poisson, Binomial, etc.
- Afterwards, we play around with the parameters for that family of distributions to find the one that would be most likely given our data and choose the corresponding parametric estimates.
- To obtain these estimates, we use the likelihood function of our observed random sample. This involves maximizing this likelihood function (which is an optimization matter!).
5.2 But, what is the likelihood function?
Important
Before we dive into the maximum likelihood estimation (MLE) case for this lecture, we must emphasize that the following elaboration is not just theoretical and abstract. It is important to provide practical examples when learning this crucial statistical topic to develop a strong understanding of it in the context of our everyday Data Science work. This understanding will be especially useful when dealing with more complex data modelling. However, the core principles of MLE still apply in these more intricate models.
Let us take a look at Figure 2.

Great! Now that we have the first case impression, let us elaborate on our MLE inquiry about ice cream.
Imagine you are the owner of a large fleet of ice cream carts, around 900 to be exact. These ice cream carts operate across different parks in the following Canadian cities: Vancouver, Victoria, Edmonton, Calgary, Winnipeg, Ottawa, Toronto, and Montréal. Furthermore, suppose you have a well-defined overall population of interest for those above eight Canadian cities: all our potential ice cream customers during any given Summer day.
For the sake of our MLE case, we will call the corresponding statistical query a time query. As a critical component of demand planning, the Operations staff currently requires a realistic estimation of the average wait time from one customer to the next one in any given cart during Summer days in these eight Canadian cities.
Important
There is a crucial characteristic on our time query that we will always have to keep in mind:
This average wait time would allow the operations team to plan carefully how much stock each cart should have so there will not be any waste or shortage.
Summertime represents the most profitable season from a business perspective, thus, solving the time query is a significant priority for your company. Hence, you decided to organize a meeting with your eight general managers (one per Canadian city) by last mid-summer. Finally, during the meeting with the general managers, it was first (and wrongly!) discussed to do the following:
Since the operations team has not previously recorded any historical data, ALL vendor staff from 900 carts will start collecting data on the wait time in minutes between each customer this upcoming Summer days of 2026.
Nonetheless, when agreeing on the specific operations protocol to start recording wait times for all the 900 vending carts this upcoming Summer of 2026, Ottawa’s general manager provides a comment for further statistical food for thought:
The operations protocol for recording wait times in the 900 vending carts looks too cumbersome to implement straightforwardly this upcoming Summer. Why don’t we select A SMALLER GROUP of ice cream carts across the eight cities to have a more efficient process implementation that would allow us to optimize operational costs?
Bingo! Ottawa’s general manager just nailed the probabilistic way of estimating our population parameter interest for our time query. Indeed, their comment was primarily framed from a business perspective of optimizing operational costs. Still, this fact does not take away a crucial insight on which statistical estimation is built: a random sample.
Furthermore, in this example and many others, let us emphasize that probability can be viewed as the language to decode random phenomena that occur in any given population or system of interest. Regarding our specific time query, a phenomenon of this kind can be represented by any randomly recorded wait time between two customers during a Summer weekend in any of the ice cream carts of the above eight Canadian cities.
Important
Having said all this, supposing there was a concrete final action plan from the above meeting with the general managers, let us clarify what three facts were agreed as crucial for the corresponding estimation process to be used in the time query:
- Population of interest: All our potential ice cream customers during any given Summer day in the following Canadian cities: Vancouver, Victoria, Edmonton, Calgary, Winnipeg, Ottawa, Toronto, and Montréal.
- Parameter of interest: Mean wait time in minutes between each customer during a given Summer (continuous and non-negative).
- How to estimate the parameter of interest: Let us use MLE via an observed random sample of \(n\) wait times across a representative small subset of the ice cream carts of the above eight Canadian cities during a given Summer. The company plans to run the sample data collection this upcoming Summer of 2026.
Warning
How we sample our data for parameter estimation depends heavily on the structure of our population or system of interest. That said, the simplest way to sample is called simple random sampling in which any element of this population or system has the same probability of being sampled.
That said, statistical practice has more than one sampling scheme (besides simple random sampling). This sampling scheme is another key factor in our parameter estimation (either classical univariate MLE, as in this ice cream example, or a more complex statistical model that could also involve multivariate MLE). Sampling techniques are out of the scope of this lecture, course, and MDS in general. If you want to get deeper information on sampling techniques, Lohr (2021) is a must-read for different sampling techniques.
Since the Summer of 2026 is still far away, you decided to run a really small pilot study across the eight Canadian cities by the end of the past Summer (to define a robust sampling protocol). You implemented a quick simple random sampling from these eight Canadian cities overall and got a sample of size \(n = 30\) wait times in minutes (taken from a really small set of ice cream carts).
Let us use this sample data to show how MLE works for our already defined parameter of interest. It is stored in sample_n30.
Firstly, let us plot the empirical (sample) distribution as a histogram (we have continuous data) but using a density scale as a first step (see Figure 3).
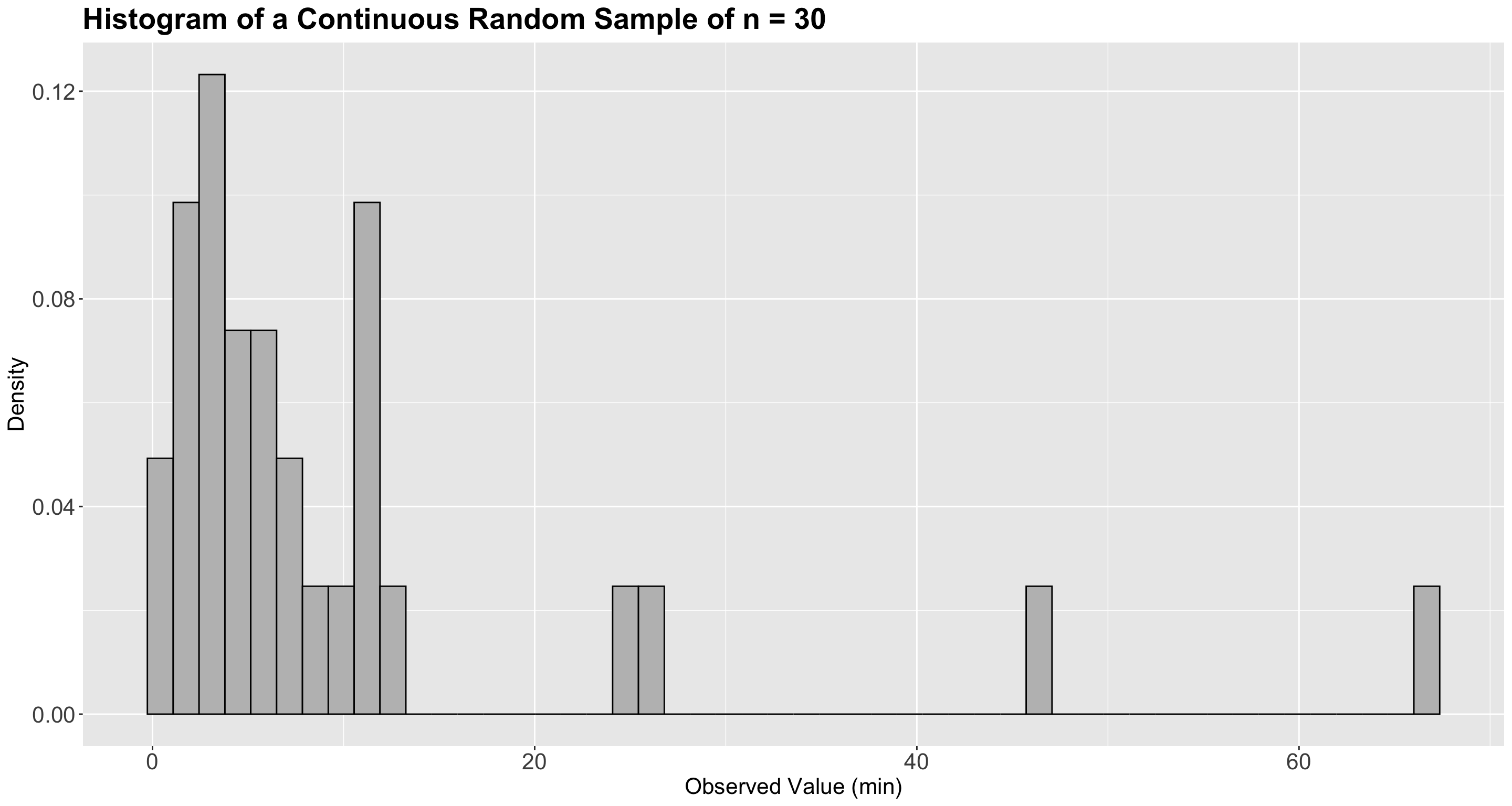
It is time to exercise our learning from lecture6, and choose an appropriate theoretical distribution to model our wait times. The Exponential distribution is a suitable one! As we previously discussed, it is a continuous and non-negative distribution that allows us to model wait times. Therefore, let us go ahead with this distribution. But beforehand, let us check an iClicker question.
Exercise 35
Besides the Exponential distribution, what other suitable distribution can we used?
Select the correct option:
A. Poisson
B. Log-Normal
C. Binomial
D. Weibull
It is important to emphasize that the Exponential distribution has two parametrizations: one for the mean wait time \(\beta > 0\) and another one for the average rate \(\lambda > 0\) at which events happen (e.g., ice creams sold per hour). In the context of our time query, the population mean wait time \(\beta > 0\) parametrization is the most suitable one. Therefore, we need to estimate \(\beta\).
Therefore, let us start with some mathematical notation. Suppose we have a random sample of size \(n = 30\) of the following independent and identically distributed (iid) random variables (which are non-negative and continuous wait times):
\[Y_1, Y_2, Y_3, \dots, Y_{28}, Y_{29}, Y_{30}.\]
Moreover, given our distributional assumption, each random variable is modelled as:
\[Y_i \sim \text{Exponential}(\beta) \quad \text{for } i = 1, 2, \dots 30.\]
Exercise 36
Answer TRUE or FALSE:
Assuming complete independence between the random variables of our sample of size \(n = 30\) across the eight Canadian cities is an entirely realistic assumption.
A. TRUE
B. FALSE
Moving along with our data analysis, each observation is \(y_i\) (\(i = 1, \dots, 30\)), such as the values in sample_n30, with the following PDF:
\[f_{Y_i}(y_i \mid \beta) = \frac{1}{\beta} \exp(-y_i / \beta).\]
Important
Note that the standalone PDF for the random variable \(Y_i\) shows a lowercase \(y_i\). This lowercase is not arbitrary; it refers to the observed value \(y_i\) in our random sample.
How can we estimate the population’s mean wait time \(\beta\) in minutes? MLE is one possible approach to overcome this matter:
- First, we choose a theoretical distribution that we believe our sample’s empirical distribution is coming. The equation \(f_{Y_i}(y_i \mid \beta)\) will be extremely useful. Here, we chose a distribution such as the Exponential given our right-skewed
hist_sample_n30(the empirical distribution in Figure 3) and the nature of our observed sample (non-negative and continuous). - In our random sample, we assume all the \(n\) observations are iid. This assumption leads to the following joint PDF:
\[f_{Y_1, \dots, Y_n}(y_1, \dots, y_n \mid \beta) = \prod_{i = 1}^n \frac{1}{\beta} \exp(-y_i / \beta). \tag{1}\]
Note the above joint PDF of our random sample has a form such all the \(n\) standalone PDFs are multiplying each other, since the corresponding random variables \(Y_1, Y_2, Y_3, \dots, Y_{28}, Y_{29}, Y_{30}\) are assumed as independent. Moreover, given that they are assumed as identically distributed, we use the same standalone PDF but \(n\) times.
Now, you might wonder: where is the likelihood function? The likelihood function is a function of the parameters of a given/chosen theoretical distribution.
Important
A likelihood function is equivalent (mathematically!) to the joint PDF of the random sample (or joint probability mass function, PMF, if the random variables are discrete, as we will see in lab4).
However, we must change our perspective: we do not know the population parameter, but the sample’s observed values.
From our previous example with the joint PDF \(f_{Y_1, \dots, Y_n}(y_1, \dots, y_n \mid \beta)\) in Equation 1, this implies:
\[L(\beta \mid y_1, \dots, y_n) = f_{Y_1, \dots, Y_n}(y_1, \dots, y_n \mid \beta) = \prod_{i = 1}^n \frac{1}{\beta} \exp(-y_i / \beta). \tag{2}\]
Equation 2 is quite particular on its left-hand side; the expression \(L(\beta \mid y_1, \dots, y_n)\) indicates the following:
The likelihood of encountering our population mean wait time \(\beta\) GIVEN our observed sampled values \(y_1, \dots, y_n\).
But still, mathematically speaking, this likelihood \(L(\beta \mid y_1, \dots, y_n)\) is equivalent to the joint PMF \(f_{Y_1, \dots, Y_n}(y_1, \dots, y_n \mid \beta)\).
5.3 How do we compute the likelihood?
Let us start with a smaller and different sample of \(n = 3\):
Suppose we only have three observations of wait times in minutes (note the lowercases!): \(y_1 = 0.8\), \(y_2 = 2.1\), and \(y_3 = 2.4\). Moreover, we will assume they come from the family of Exponential distributions. The likelihood function would be the joint PDF of this sample:
\[ \begin{align*} L(\beta \mid y_1, y_2, y_3) &= \frac{1}{\beta} \exp(-y_1 / \beta) \times \frac{1}{\beta} \exp(-y_2 / \beta) \times \frac{1}{\beta} \exp(-y_3 / \beta) \\ &= \frac{1}{\beta} \exp(-0.8 / \beta) \times \frac{1}{\beta} \exp(-2.1 / \beta) \times \frac{1}{\beta} \exp(-2.4 / \beta). \end{align*} \]
Look at the left-hand side of the above likelihood equation! The likelihood function is NOT a joint PDF, even though it mathematically looks the same as the joint PDF of your sample. The likelihood function is a function of the parameter \(\beta\) and not \(y_1\), \(y_2\), and \(y_3\).
Calculating the likelihood value:
Since we want to calculate the likelihood of a specific theoretical distribution given the data we have observed:
\[L(\text{distributional parameter}\, | \,\text{observed data});\]
to calculate the likelihood for a specific distribution for that family, we choose a specific value for \(\beta\). Then, we calculate the likelihood. For instance, what is the likelihood of an Exponential distribution where the population mean wait time \(\beta = 0.5\) minutes given the data we observed?
\(L(\beta \mid y_1, y_2, y_3) = \frac{1}{0.5} \exp(-0.8 / 0.5) \times \frac{1}{0.5} \exp(-2.1 / 0.5) \times \frac{1}{0.5} \exp(-2.4 / 0.5)\)
Let us use R!
[1] 0.0001993281Or more easily (via dexp()):
data <- c(0.8, 2.1, 2.4)
prod(dexp(data, rate = 1 / 0.5)) # dexp() is parametrized as rate = 1 / beta = 1 / 0.5[1] 0.0001993281We can use another two \(\beta\) values to compute the corresponding likelihood given the data we observed. Let us use \(\beta = 2\) and \(20\) minutes.
Removing the curtain!
The observed data for this small case (\(y_1 = 0.8\), \(y_2 = 2.1\), and \(y_3 = 2.4\)) was actually drawn from an Exponential distribution with \(\beta = 2\). Thus, it is not a surprise that the likelihood is higher for this value of \(\beta\) than the other two we tried.
5.4 Going back to our sample_n30
We will choose a few different Exponential distributions (by varying \(\beta\)), calculate the likelihood for those distributions given the data we observed, and then overlay those distributions on the empirical distributions (i.e., histograms) to see how they map together.
Let us try the following \(\beta\) values: \(20\), \(8\) and \(2\) minutes.
sample_n30# A tibble: 30 × 1
values
<dbl>
1 24.9
2 7.23
3 4.16
4 5.60
5 5.38
6 1.41
7 7.07
8 2.84
9 0.895
10 2.90
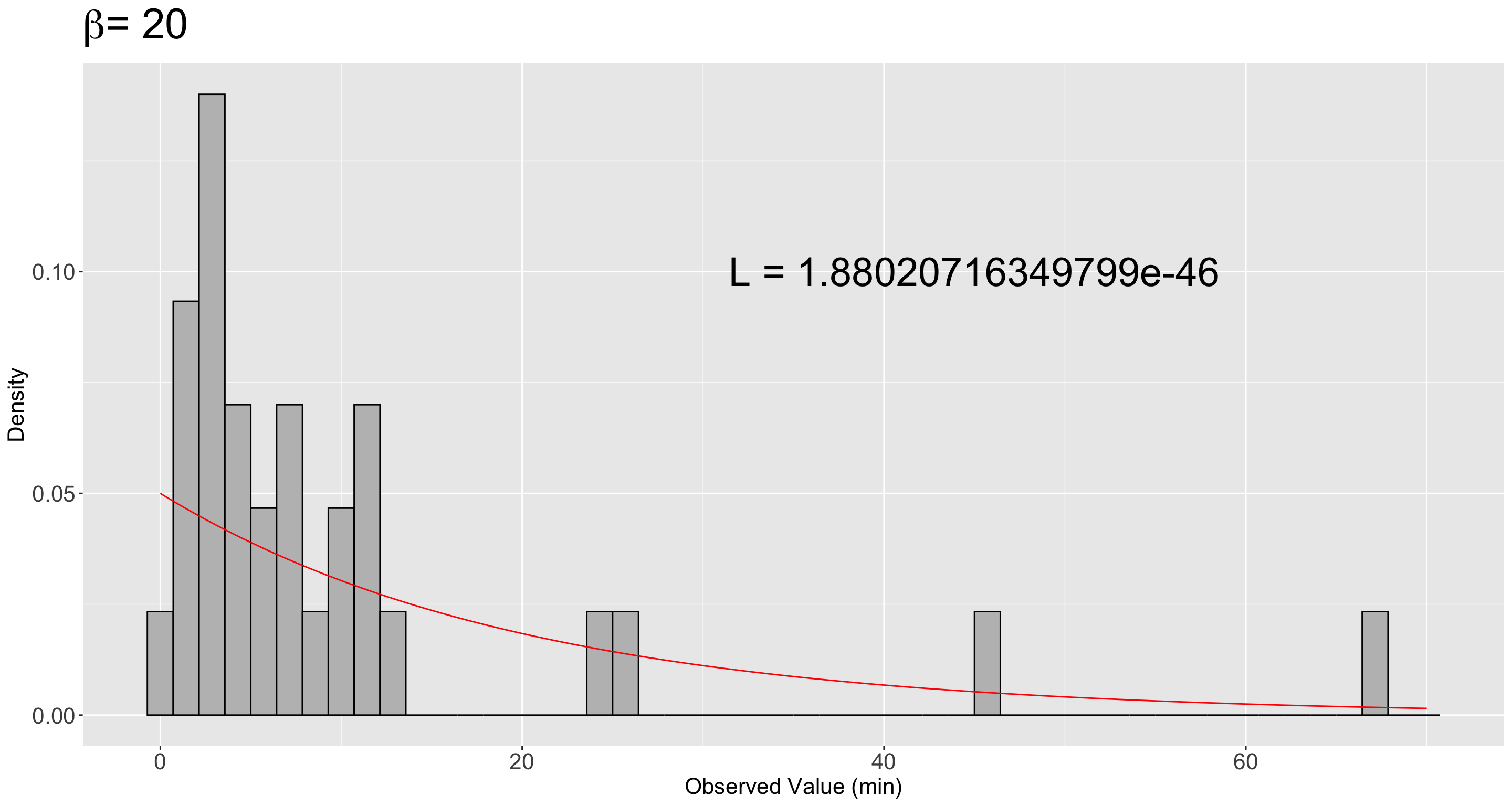
# ℹ 20 more rowsWe will calculate the theoretical joint PDF (density_20 in our code) of an Exponential distribution with \(\beta = 20\) minutes for a sequence of values (x) from 0 to 70 by 0.05:
# A tibble: 1,401 × 2
x density
<dbl> <dbl>
1 0 0.05
2 0.05 0.0499
3 0.1 0.0498
4 0.15 0.0496
5 0.2 0.0495
6 0.25 0.0494
7 0.3 0.0493
8 0.35 0.0491
9 0.4 0.0490
10 0.45 0.0489
# ℹ 1,391 more rowsThen, we plot this theoretical density on top of the empirical (sample) distribution (i.e., the histogram) in Figure 4.
Now for \(\beta\) values of \(8\) and \(2\):
# A tibble: 1,401 × 2
x density
<dbl> <dbl>
1 0 0.125
2 0.05 0.124
3 0.1 0.123
4 0.15 0.123
5 0.2 0.122
6 0.25 0.121
7 0.3 0.120
8 0.35 0.120
9 0.4 0.119
10 0.45 0.118
# ℹ 1,391 more rows# A tibble: 141 × 2
x density
<dbl> <dbl>
1 0 0.5
2 0.5 0.389
3 1 0.303
4 1.5 0.236
5 2 0.184
6 2.5 0.143
7 3 0.112
8 3.5 0.0869
9 4 0.0677
10 4.5 0.0527
# ℹ 131 more rowsThen, we plot these theoretical densities on top of the same the empirical (sample) distribution (i.e., the histogram) in Figure 5.
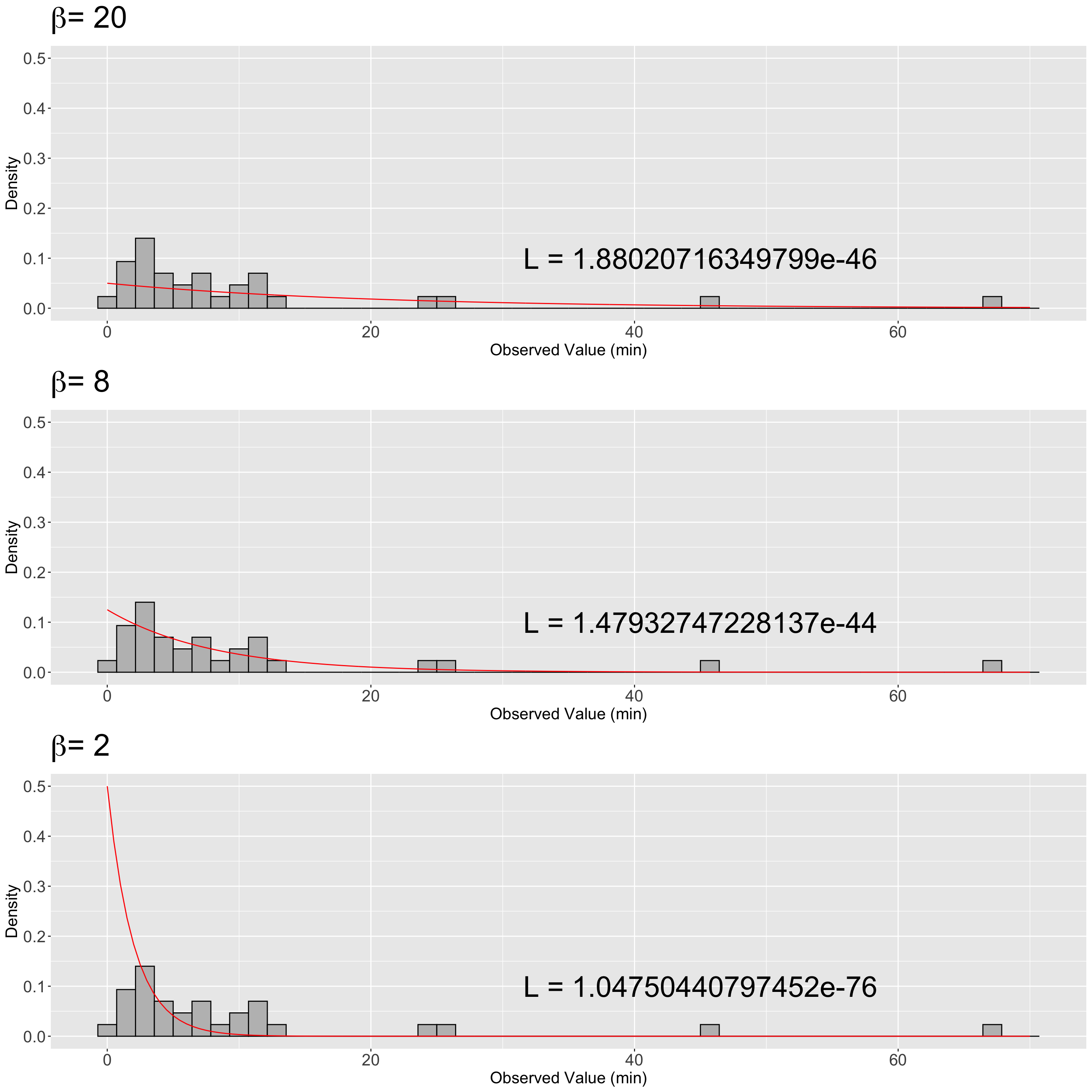
We can see that the largest likelihood value maps onto the Exponential distribution that best fits the observed data: the one with \(\beta = 8\) minutes (note the \(y\)-axis scale is the same for the three histograms).
5.5 Interlude: The wonders of log-likelihood
Let us re-check the three previous likelihood values coming from sample_n30:
- For \(\beta = 20\):
likelihood_20 [1] 1.880207e-46- For \(\beta = 8\):
likelihood_8 [1] 1.479327e-44- For \(\beta = 2\):
likelihood_2 [1] 1.047504e-76Likelihood values are super small! Hence, we could make a logarithmic transformation (i.e., a monotonic transformation) on the base \(e\) for the likelihood function: the log-likelihood function.
The use of the log-likelihood function is common in MLE for mathematical and numerical optimization purposes.
As previously stated, we would not know the real value for \(\beta\). The empirical use above, to estimate the value for \(\beta\), shows us that \(\beta = 8\) provides the maximum value (i.e., the least negative value) for the log-likelihood function from these three possible options. This \(\beta = 8\) is the value under which our random sample is more likely (under the assumption of an Exponential distribution).
However, to find the maximum likelihood value (and hence best \(\beta\) to obtain our specific Exponential distribution) using this approach would take forever and/or be impossible.
Let us instead calculate and visualize the likelihoods for a wide range of \(\beta\) and choose the specific distribution with the maximum likelihood.
Important
Even though we will automatically try a wide range of \(\beta\) values to obtain the one that yields the maximum likelihood, this is an empirical solution, not an analytical solution.
5.6 Finding the maximum likelihood and log-likelihood using a range of \(\beta\) values
Let us calculate the likelihood and log-likelihood values for a range of \(\beta\) for our hist_sample_n30 and then plot these.
What range? We will try a sequence \(5\) to \(50\) by \(0.5\).
Note the following in the data frame exp_values:
- Each row in
possible_betasindicates a candidate value for \(\beta\) to try in our search for the maximum. - Column
likelihoodindicates the value of the exponential likelihood equation with the \(n = 30\) observed wait times stored insample_n30$values. - Column
log_likelihoodindicates the logarithmic transformation on the base \(e\) of columnlikelihood.
exp_values <- tibble(
possible_betas = seq(5, 50, 0.5),
likelihood = map_dbl(1 / possible_betas, ~ prod(dexp(sample_n30$values, .))),
log_likelihood = map_dbl(1 / possible_betas, ~ log(prod(dexp(sample_n30$values, .))))
)
exp_values# A tibble: 91 × 3
possible_betas likelihood log_likelihood
<dbl> <dbl> <dbl>
1 5 1.78e-48 -110.
2 5.5 2.78e-47 -107.
3 6 2.18e-46 -105.
4 6.5 1.03e-45 -104.
5 7 3.30e-45 -102.
6 7.5 7.85e-45 -102.
7 8 1.48e-44 -101.
8 8.5 2.32e-44 -100.
9 9 3.13e-44 -100.
10 9.5 3.75e-44 -100.0
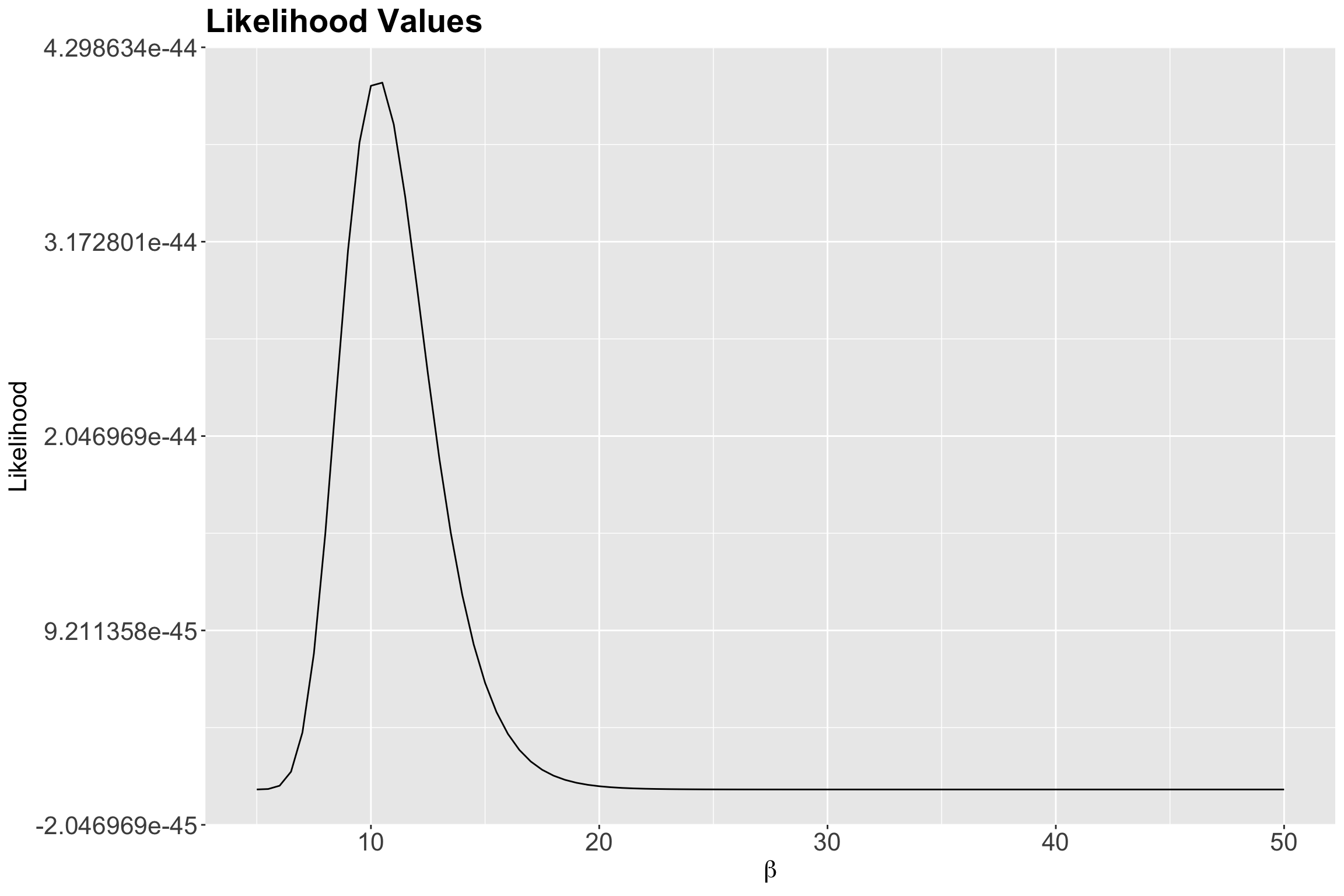
# ℹ 81 more rowsThen, we plot the possible \(\beta\)s against the likelihood of observing them given our data in Figure 6.
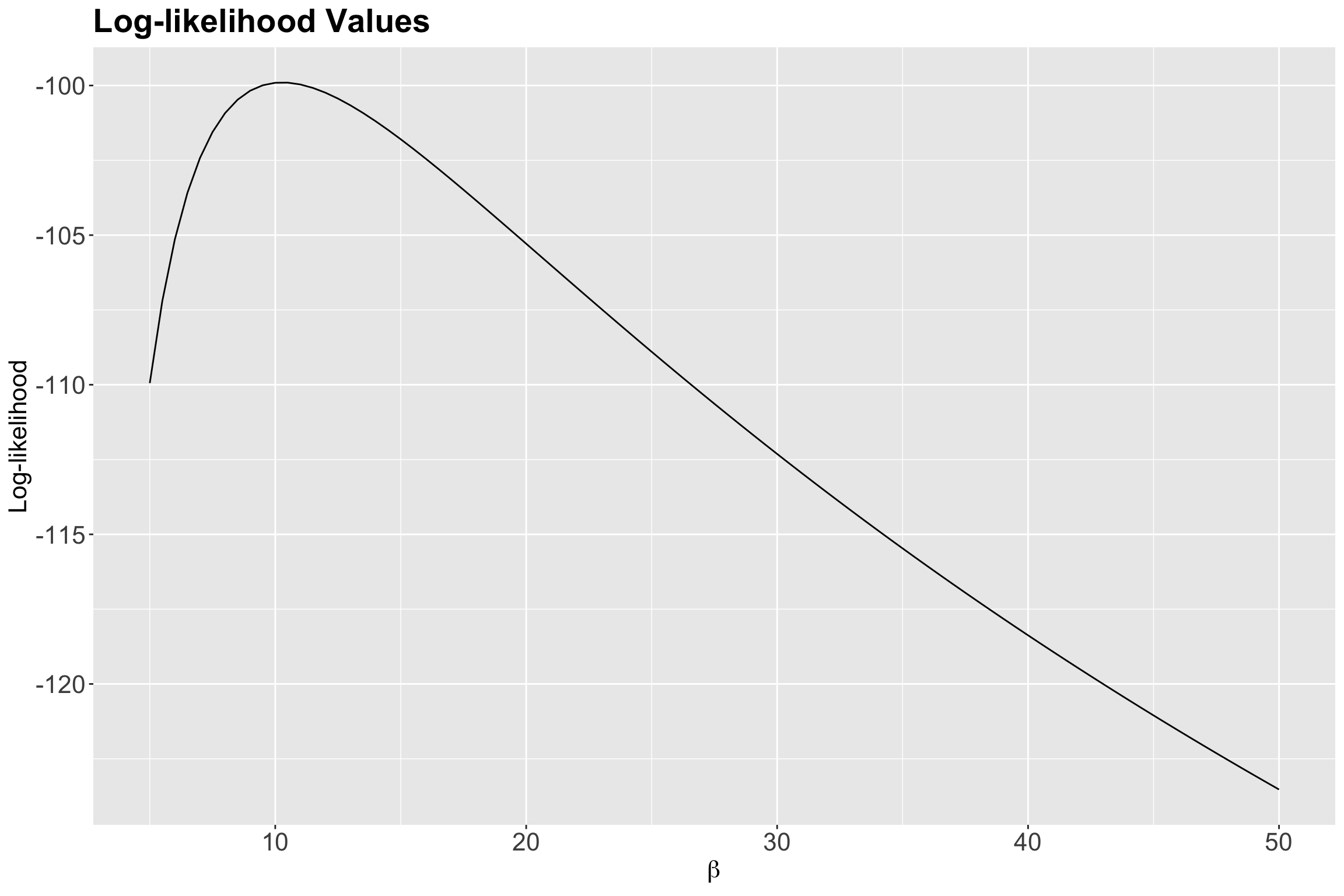
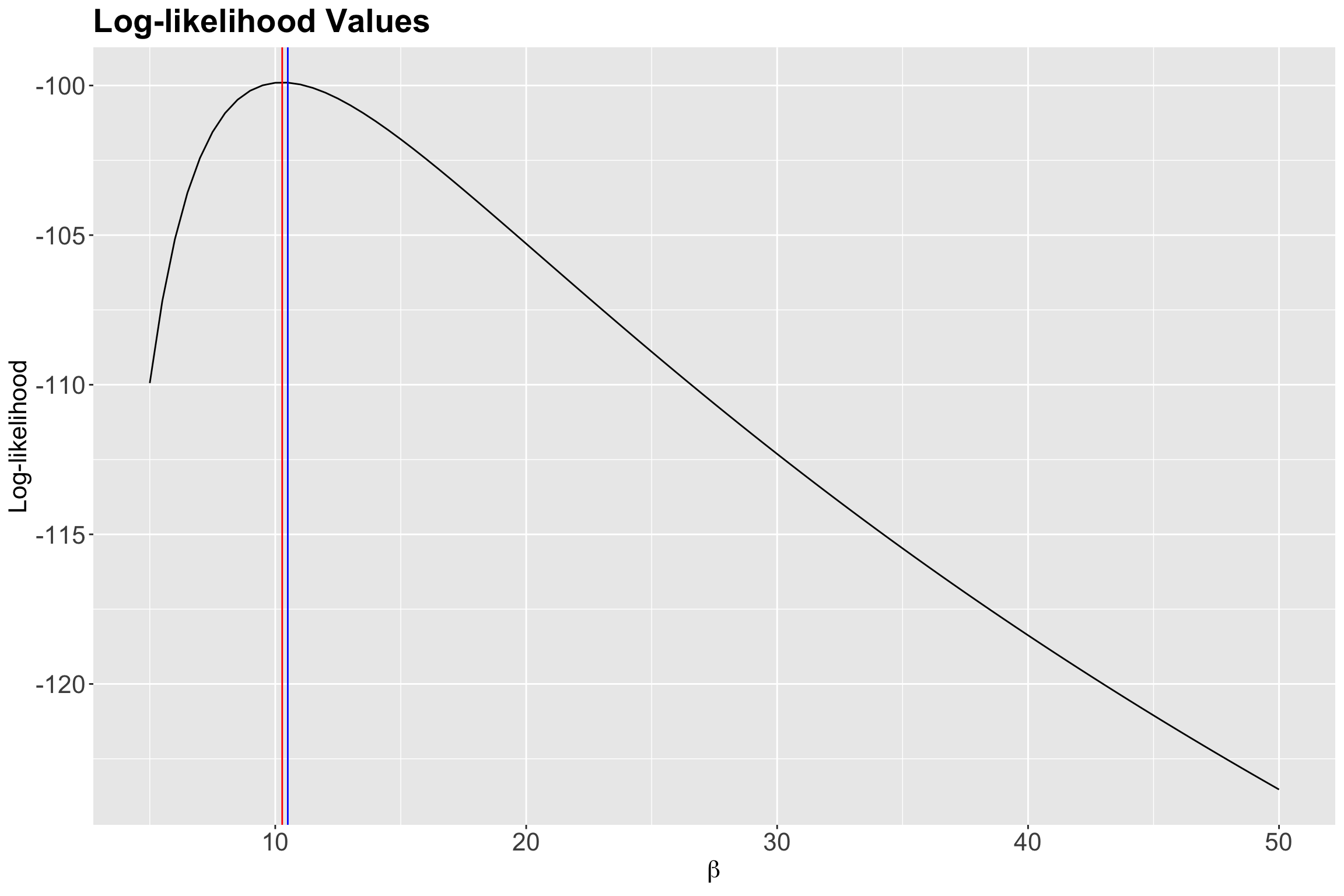
How about the log-likelihood values? Let us check Figure 7.
What is the maximum? Reading off the graph is a bit difficult, so we will grab the maximum from data frame empirical_MLE:
empirical_MLE <- exp_values |>
arrange(desc(likelihood)) |>
slice(1)
empirical_MLE# A tibble: 1 × 3
possible_betas likelihood log_likelihood
<dbl> <dbl> <dbl>
1 10.5 4.09e-44 -99.9According to the previous output, our empirical maximum likelihood estimate of the mean population wait time between customers is 10.5 minutes. Let us double-check this matter by plotting it as a vertical blue line on our previous two plots:
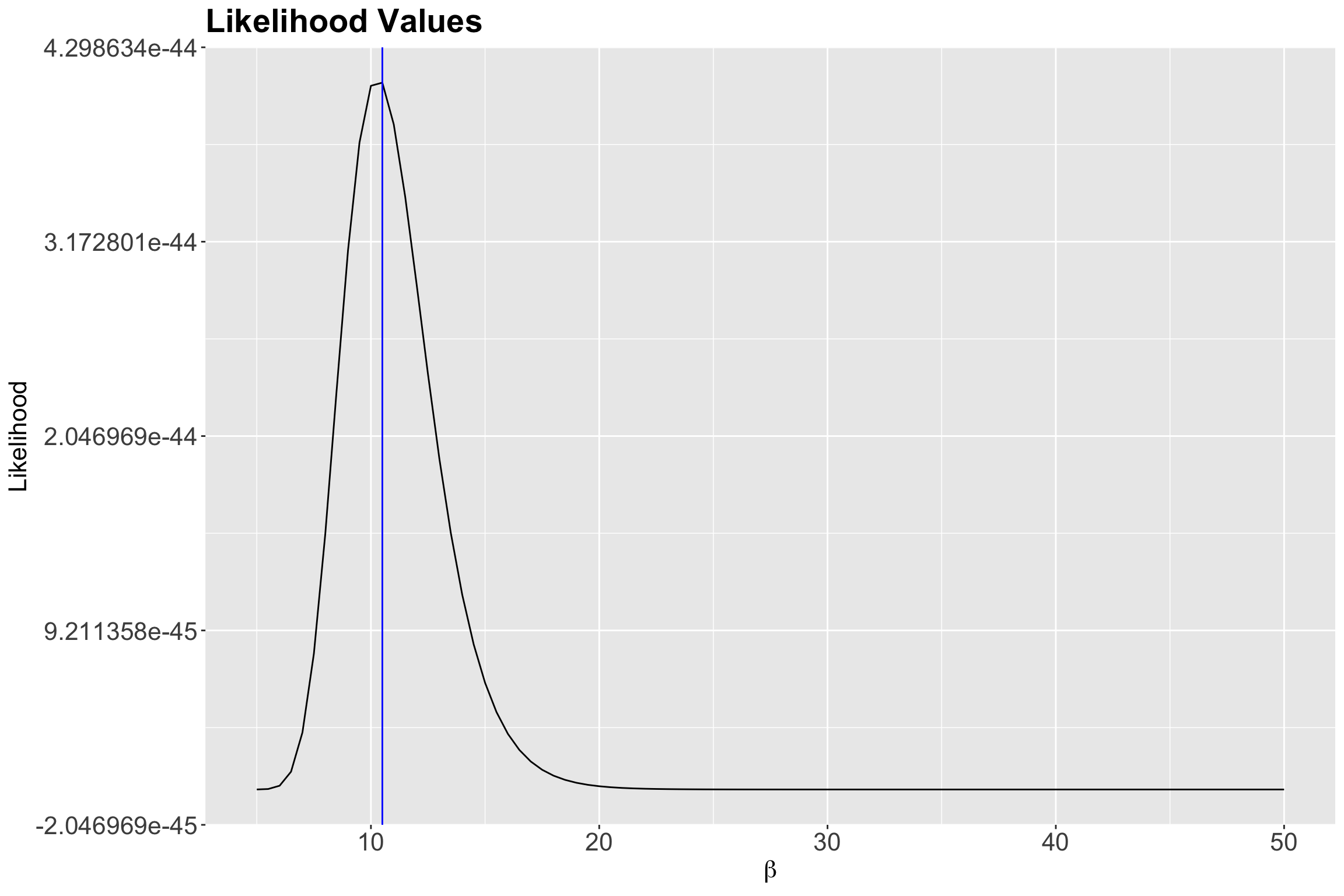
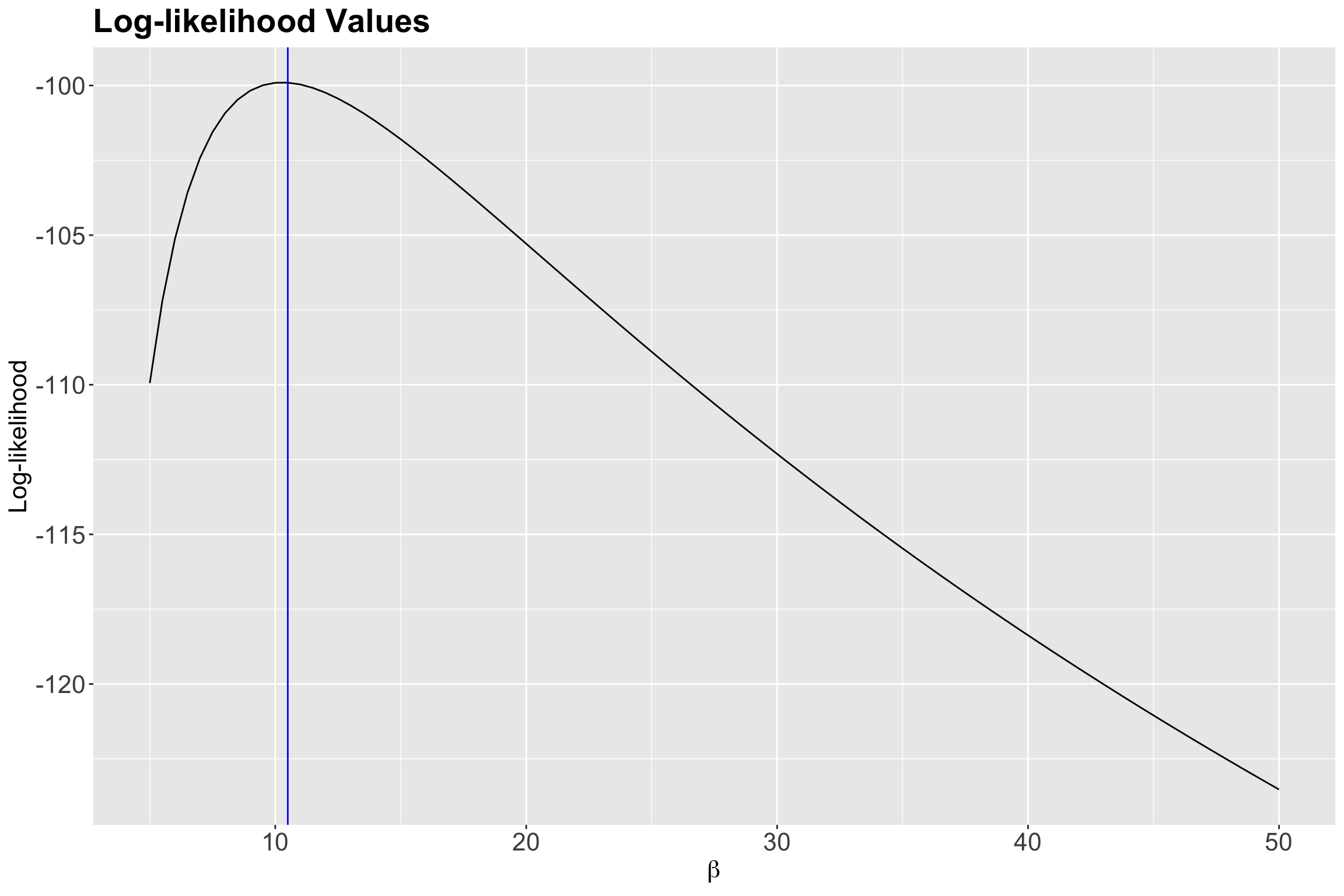
Indeed, we have empirically found a maximum at 10.5 minutes!
Important
Let us recall our population parameter to estimate: the mean wait time in minutes between each ice cream customer during a given Summer day. Moreover, our population is all our potential ice cream customers during any given Summer day in the following Canadian cities: Vancouver, Victoria, Edmonton, Calgary, Winnipeg, Ottawa, Toronto, and Montréal.
That said, our pilot study with \(n = 30\) sampled wait times indicates that, on average, the estimated wait time between each ice cream customer is 10.5 minutes during a given Summer day via empirical MLE overall in these eight cities. The precision of the maximum likelihood estimate we can develop, using this empirical method, depends on the increments we vary \(\beta\).
Note that this is a primary approach in which we only estimate a single parameter, making this a univariate MLE case. We can expand our estimations to more than one overall mean wait time via alternative modelling approaches. For instance, we can also work around a more complex regression model to estimate different mean wait times per city. Nonetheless, this is part of DSCI 562.
6 Can we apply MLE analytically?
Yes, we can!
And it will involve multivariate Calculus since we have an optimization problem.
For the Exponential distribution, it can be shown that
\[\hat{\beta} = {\bar{Y}} = \frac{\sum_{i = 1}^n Y_i}{n},\]
which is the sample mean!
Let us do it with \(\beta\) in the Exponential distribution!
- We will generalize our derivation by assuming a random sample of \(n\) observations (they are iid). Recall that the \(i\)th observation (\(i = 1, \dots, n\)) has the following PDF:
\[f_{Y_i}(y_i \mid \beta) = \frac{1}{\beta} \exp(-y_i / \beta).\]
- Since the \(n\) observations are assumed iid, the joint PDF is as follows:
\[f_{Y_1, \dots, Y_n}(y_1, \dots, y_n \mid \beta) = \prod_{i = 1}^n \frac{1}{\beta} \exp(-y_i / \beta).\]
- The joint likelihood function is mathematically equivalent to the joint PDF. Thus, along with some algebraic rearrangements, we have:
\[ \begin{align*} L(\beta \mid y_1, \dots , y_{n}) &= \prod_{i = 1}^n \frac{1}{\beta} \exp(-y_i / \beta) \\ &= \frac{1}{\beta^n} \exp \bigg( -\frac{1}{\beta} \sum_{i = 1}^n y_i \bigg). \end{align*} \]
- Now, we apply some logarithmic properties to obtain the log-likelihood function:
\[ \log L(\beta \mid y_1, \dots , y_{n}) = -n \log (\beta) - \frac{1}{\beta} \sum_{i = 1}^n y_i. \]
- We take the first partial derivative, with respect to \(\beta\), of the joint log-likelihood function:
\[ \begin{align*} \frac{\partial}{\partial \beta} \log L(\beta \mid y_1, \dots , y_{n}) &= -\frac{n}{\beta} + \frac{1}{\beta^2} \sum_{i = 1}^n y_i \\ &= \frac{1}{\beta} \left(-n + \frac{1}{\beta} \sum_{i = 1}^n y_i \right). \end{align*} \]
- Then, we set this derivative equal to zero and solve for \(\beta\):
\[ \begin{gather*} \frac{1}{\beta} \left(-n + \frac{1}{\beta} \sum_{i = 1}^n y_i \right) = 0 \\ -n + \frac{1}{\beta} \sum_{i = 1}^n y_i = 0 \\ \frac{1}{\beta} \sum_{i = 1}^n y_i = n \\ \hat{\beta} = \frac{\sum_{i = 1}^n Y_i}{n} = \bar{Y}. \end{gather*} \]
Important
Since we are obtaining the maximum likelihood estimator, the notation in \(\hat{\beta}\) on the right-hand side changes to uppercases (random variables).
Furthermore, these six steps also apply to other distributional parameters. For instance, \(\mu\) and \(\sigma^2\) in the Normal distribution or \(\lambda\) in the Poisson distribution.
Warning
Aside from the previous six steps, there is another step in which we check whether the maximum likelihood estimate is a local maximum. This is called the second derivative test. The second derivative is obtained from the first derivative:
\[\frac{\partial^2}{\partial \beta^2} \log L(\beta \mid y_1, \dots , y_{n}) = \frac{n}{\beta^2} - \frac{2}{\beta^3} \sum_{i = 1}^n y_i.\]
Then, we plug in the maximum likelihood estimator as an estimate (i.e., observed values denoted by lowercase \(y_i\)):
\[ \begin{align*} \frac{\partial^2}{\partial \beta^2} \log L(\beta \mid y_1, \dots , y_{n}) &= \frac{n}{\left( \frac{\sum_{i = 1}^n y_i}{n} \right)^2} - \frac{2}{\left( \frac{\sum_{i = 1}^n y_i}{n} \right)^3} \sum_{i = 1}^n y_i \\ &= \frac{n^3}{\left(\sum_{i = 1}^n y_i\right)^2} - \frac{2 n^3}{\left( \sum_{i = 1}^n y_i \right)^2} \\ &= -\frac{n^3}{\left(\sum_{i = 1}^n y_i\right)^2} < 0. \end{align*} \]
According to the second derivative test, if our second derivative is less than zero evaluated at our estimate, then our maximum likelihood estimate is indeed a local maximum.
Finally…
Let us convince ourselves of this by overlaying our analytical \(\hat{\beta}\) using our observed sample_n30 on our plots (the vertical red line indicates this analytical maximum likelihood estimate \(\hat{\beta}\)):
analytical_MLE <- mean(sample_n30$values) # We use the sample mean() function from R!
round(analytical_MLE, 2)[1] 10.28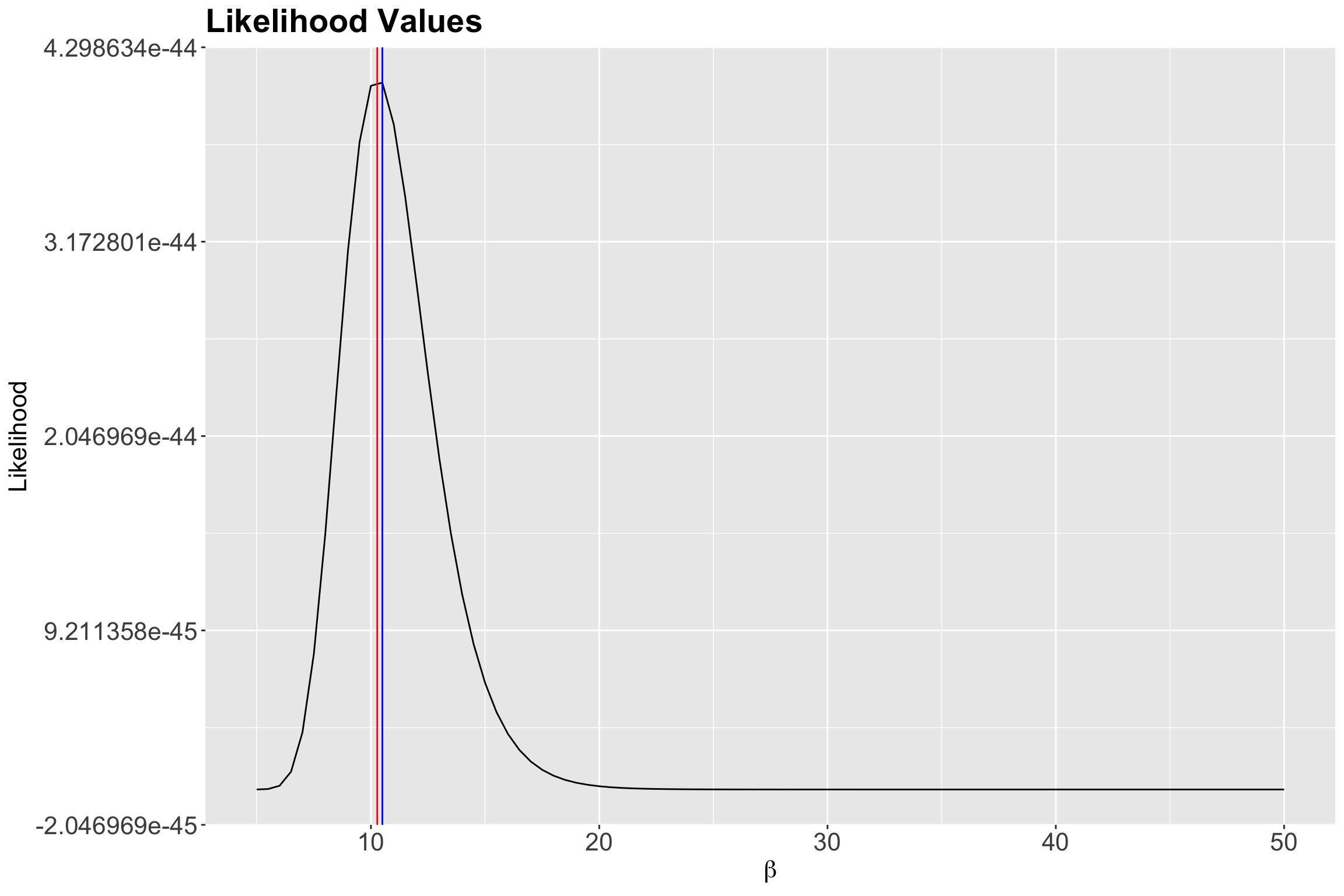
7 Wrapping up!
MLE allows us to estimate population parameters via the observed values of a random sample. This is a classical theory-based method where one needs to make strong distributional assumptions on the data (i.e., the distributions we have seen this block). Moreover, the respective estimators are usually well-behaved (asymptotically speaking, which means when the sample size \(n \rightarrow \infty\)).
Understanding the foundations of MLE is crucial, especially in fields like regression or survival analysis, where it finds practical applications in GLMs or parametric survival regression.
If we want to estimate our population parameters of interest assuming a distribution that has more than one parameter (e.g., \(F\)-distribution or regression models with multiple parameters), things get a bit more complicated:
- Mathematically, solving this matter involves complex partial derivatives without a closed solution.
-
Numerical optimization in
Ris possible using theoptimize()function. - Moreover, we can find different
Rpackages that provide ready-to-use estimation functions such asglm()for GLMs.
It is important to note that we have covered two distinct paths in MLE: the empirical and analytical. A conceptual understanding of both is essential for a thorough grasp of MLE.
7.1 Steps for Empirical MLE
Step 1: Choose the right distribution for the \(i\)th (\(i = 1 , \dots, n\)) PDF or probability mass function (PMF)
- Using information you know about your sample of size \(n\), choose a family of distributions.
- Identify the corresponding PDF (for continuous data) or PMF (for discrete data).
Step 2: Obtain the joint or PDF or PMF
Once we have the \(i\)th PDF or PMF, build the joint probability distribution of the sample of \(n\) random variables.
Step 3: Obtain the joint likelihood function
Recall this function is mathematically equivalent to the joint PDF or PMF.
Step 4: Obtain the joint log-likelihood function
Use the rules of logarithms on the joint likelihood function.
Step 5: Vary the parameters for that family of distribution and calculate the likelihood or log-likelihood
- Use information about the observed sample to help choose the range of values to vary the parameter over.
- Given your observed sample and the likelihood or log-likelihood functions, vary the parameter’s value all over that range and compute their corresponding function values.
Step 6: Choose the parameter value that gives you the maximum likelihood or log-likelihood
This value will be the maximum likelihood estimate under which your observed data is most likely.
7.2 Steps for Analytical MLE
Steps 1, 2, 3, and 4 are the same from above.
Step 5: Obtain the partial derivative with respect to the parameter of interest
You have to use the log-likelihood function since its form makes derivation easier.
Step 6: Set the partial derivative equal to zero and solve for the parameter of interest
We are doing this because it is an optimization problem.
Important
In cases of no analytical solution in this step, we need a numerical optimization method.
Step 7: Check you have a maximum
You can do it using the second partial derivative criterion with respect to the same parameter of interest.
8 (Optional) Supplementary Material
8.1 The use of the optimize() function
Let us use R’s optimize(), to obtain \(\hat{\beta}\) with sample_n30. This function uses numerical optimization and finds the point where the slope is 0 (maximum).
optimize() needs at least these 3 things:
- The log-likelihood function (that references your data)
- A range of values to vary the parameter over (here
5to50). - Whether to return the minimum or the maximum of the function.
LL <- function(l) log(prod(dexp(sample_n30$values, rate = 1 / l)))
optimize(LL, c(5, 50), maximum = TRUE)$maximum
[1] 10.27704
$objective
[1] -99.89738Note the optimized maximum coming from optimize() matches the analytical maximum likelihood estimate.
9 Questions you might have…
- In previous statistical courses, when we estimated things like mean, standard deviation, or proportion of successes, we only calculated these values from the sample using a simple formula. So why are we using more complicated math now to arrive at essentially the same thing?
MLE provides you with a great way to FIND estimators, which are usually well-behaved (asymptotically speaking!). Finding good estimators is a difficult task. The sample mean is a trivial case with a very intuitive answer. However, sometimes you are trying to estimate something much more complex. For example \(\beta_0\) and \(\beta_1\) from a linear regression model:
\[Y = \beta_0 + \beta_1 X_1 + \varepsilon\]
How would you estimate these parameters when \(\varepsilon \sim \mathcal{N}(0, \sigma^2)\)? MLE can help with that! It is an alternative to ordinary least-squares estimation (to be seen in DSCI 561). In more complex regression frameworks, such as GLMs, MLE is the go-to parameter estimation method.
- OK, we are using a different estimation technique - what about that plausible range for an estimate? For example, if I use MLE to estimate a mean and a standard deviation, how do I calculate a plausible range (i.e., confidence intervals for this estimate to be covered in DSCI 552)?
We can come up with the sampling distribution like we do for any given estimator: through asymptotics or bootstraping (to be covered in DSCI 552).
- When we talked about estimation in general, we said you could estimate any “thing/object.” Primarily, we have been working with point estimates, but it could be a function (e.g., empirical distribution function or empirical cumulative distribution function) or other things (a classifier, for example). Are we “limited” to estimating distributions and/or distributional parameters of probability distributions when using MLE?
The MLE is “limited” to estimating parameters, specifically. But we can then use those estimates to compute other things (and one can prove that those computations are also the MLE, if we were to re-parameterize in terms of that quantity). Same with a classifier - first get the MLE of a parameter (like in logistic regression), then do classification. You will see this in the upcoming Machine Learning courses.