Proposal Report - Checklists and LLM prompts for efficient and effective test creation in data analysis
by John Shiu, Orix Au Yeung, Tony Shum, Yingzi Jin
Executive Summary
The rapid growth of global artificial intelligence (AI) markets presents opportunities and challenges. While AI systems have the potential to impact various aspects of human life, ensuring their software quality remains a significant concern. Current testing strategies for machine learning (ML) systems lack standardization and comprehensiveness, which poses risks to stakeholders, such as financial losses and safety hazards.
Our proposal addresses this challenge by developing a manually curated checklist which contains best practices and recommendations in testing ML systems. Additionally, an end-to-end application incorporating the checklist and Large Language Model (LLM) will be developed to analyze given ML system source codes and provide test completeness evaluation, missing test recommendations, and test function specification generation. Our proposed solution will enable users to systematically assess, improve, and include tests tailored to their ML systems through a combination of human expertise codified within the checklist and parametric memory from LLMs.
In the following weeks, we will develop and refine our product through a swift and efficient iterative development approach, with the aim to deliver a rigorously tested and fully-documented system to our partners by the end of the project.
Introduction
Problem Statement
The global artificial intelligence (AI) market is growing exponentially (Grand-View-Research 2021), driven by its ability to autonomously make complex decisions impacting various aspects of human life, including financial transactions, autonomous transportation, and medical diagnosis.
However, ensuring the software quality of these systems remains a significant challenge (Openja et al. 2023). Specifically, the lack of a standardized and comprehensive approach to testing machine learning (ML) systems introduces potential risks to stakeholders. For example, inadequate quality assurance in ML systems can lead to severe consequences, such as substantial financial losses (Regidi 2019) and safety hazards.
Therefore, defining and promoting an industry standard and establishing robust testing methodologies for these systems is crucial. But how?
Our Objectives
We propose to develop testing suites diagnostic tools based on Large Language Models (LLMs) and curate a checklist to facilitate comprehensive testing of ML systems with flexibility. Our goal is to enhance applied ML software’s trustworthiness, quality, and reproducibility across both the industry and academia (Kapoor and Narayanan 2022).
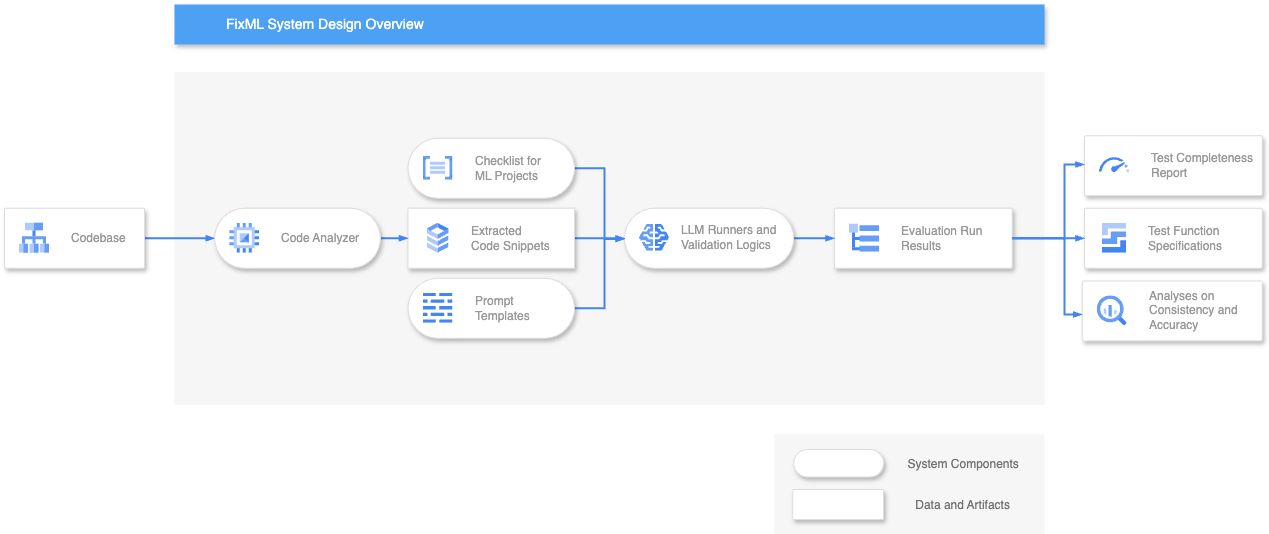
Our Product
Our solution offers an end-to-end application for evaluating and enhancing the robustness of users’ ML systems.
One big challenge in utilizing LLMs to reliably and consistently evaluate ML systems is their tendency to generate illogical and/or factually wrong information known as hallucination (Zhang et al. 2023).
To combat this, the proposed system will incorporate a checklist (Fig. 1) which would be curated manually and incorporate best practices in software testing and identified areas to be tested inside ML pipeline from human experts and past research.
This checklist will be our basis in evaluating the effectiveness and completeness of existing tests in a given codebase. Relevant information will be injected into a prompt template, which the LLMs would then be prompted to follow the checklist exactly during the evaluation.
Here is an example of how the proposed checklist would be structured:
%YAML 1.2
---
Title: Checklist for Tests in Machine Learning Projects
Description: >
This is a comprehensive checklist for evaluating the data and ML pipeline
based on identified testing strategies from experts in the field.
Test Areas:
- Topic: General
Description: >
The following items describe best practices for all tests to be
written.
Tests:
- Title: Write Descriptive Test Names
Requirement: >
Every test function should have a clear, descriptive name
Explanation: >
If out tests are narrow and sufficiently descriptive, the test
name itself may give us enough information to start debugging.
This also helps us to identify what is being tested inside the
function.
References:
- https://testing.googleblog.com/2014/10/testing-on-toilet-writing-descriptive.html
- https://testing.googleblog.com/2024/05/test-failures-should-be-actionable.html
- Title: Keep Tests Focused
Requirement: >
Each test should only test one scenario, meaning that in each
test we should only use one set of mock data.
Explanation: >
If we test multiple scenarios in a single test, it is hard to
idenitfy exactly what went wrong. Keeping one scenario in a
single test helps us to isolate problematic scenarios.
References:
- https://testing.googleblog.com/2018/06/testing-on-toilet-keep-tests-focused.html
- Title: Prefer Narrow Assertions in Unit Tests
Requirement: >
The assertions inside the tests should be narrow, meaning that
when checking a complex object, any unrelated behavior should
not be tested - Assert on only relevant behaviors.
Explanation: >
If we have overly wide assertions (such as depending on every
field of a complex output proto), the test may fail for many
unimportant reasons. False positives are the opposite of
actionable.
References:
- https://testing.googleblog.com/2024/04/prefer-narrow-assertions-in-unit-tests.html
- Title: Keep Cause and Effect Clear
Requirement: >
The modifications and the assertions of an object's behavior
in a single test should not be far away from each other.
Explanation: >
Refrain from using large global test data structures shared
across multiple unit tests. This will allow for clear
identification of each test's setup and the cause and effect.
References:
- https://testing.googleblog.com/2017/01/testing-on-toilet-keep-cause-and-effect.html
- Topic: Data Presence
Description: >
The following items describe tests that need to be done for testing
the presence of data.
Tests:
- Title: ...
Requirement: ...
Explanation: ...
References:
- ...
- Topic: Data Quality
Description: >
The following items describe tests that need to be done for testing
the quality of data.
Tests:
- Title: ...
Requirement: ...
Explanation: ...
References:
- ...
- Topic: Data Ingestion
Description: >
The following items describe tests that need to be done for testing
if the data is ingestion properly.
Tests:
- Title: ...
Requirement: ...
Explanation: ...
References:
- ...
- Topic: Model Fitting
Description: >
The following items describe tests that need to be done for testing
the model fitting process.
Tests:
- Title: ...
Requirement: ...
Explanation: ...
References:
- ...
- Topic: Model Evaluation
Description: >
The following items describe tests that need to be done for testing
the model evaluation process.
Tests:
- Title: ...
Requirement: ...
Explanation: ...
References:
- ...
- Topic: Artifact Testing
Description: >
The following items describe tests that need to be done for testing
any artifacts that are created from the project.
Tests:
- Title: ...
Requirement: ...
Explanation: ...
References:
- ...Evaluation Artifacts
The end goal of our product is to generate the following three artifacts in relation to the evaluation of a given ML system codebase:
ML Test Completeness Score: The application utilizes LLMs and our curated checklist to analyze users’ ML system source code and returns a comprehensive score of the system’s test quality.
Missing Test Recommendations: The application evaluates the adequacy of existing tests for users’ ML code and offers recommendations for additional, system-specific tests to enhance testing effectiveness.
Test Function Specification Generation: Users select desired test recommendations and prompt the application to generate test function specifications and references. These are reliable starting points for users to enrich the ML system test suites.
Success Metrics
Our product’s success will depend on mutation testing of the test functions developed based on our application-generated specifications. The evaluation metric is the success rate of detecting the perturbations introduced to the ML project code.
Our partners and stakeholders expect a significant improvement in the testing suites of their ML systems post-application usage. As a result, the testing suites will demonstrate high accuracy in detecting faults, ensuring consistency and high quality of ML projects during updates.
Data Science Approach
Data: GitHub Repositories
In this project, GitHub repositories are our data.
To develop our testing checklist, we will collect 11 repositories studied in (Openja et al. 2023). Additionally, we will collect 377 repositories identified in the study by (Wattanakriengkrai et al. 2022) for our product development.
For each repository, we are interested in the metadata and the ML modeling- and test-related source code. The metadata will be retrieved using the GitHub API, while the source code will be downloaded and filtered using our custom scripts. To ensure the relevance of the repositories to our study, we will apply the following criteria for filtering: 1. Repositories that are related to ML systems. 2. Repositories that include test cases. 3. Repositories whose development is written in the Python programming language.
Methodologies
Our data science methodology incorporates human expert evaluation and prompt engineering to assess and enhance the test quality of ML systems.
Human Expert Evaluation
We will begin by formulating a comprehensive checklist for evaluating the data and ML pipeline based on the established testing strategies outlined in (Openja et al. 2023) as the foundational framework. Based on the formulated checklist, our team will manually assess the test quality within each repository data. We will refine the checklist to ensure applicability and robustness when testing general ML systems.
Prompt Engineering
We will engineer the prompts for LLM to incorporate with the ML system code and the curated checklist and to serve various purposes across the three-stage process:
- Prompts to examine test cases within the ML system source codes and deliver test completeness scores.
- Prompts to compare and contrast the existing tests and the checklist and deliver recommendations.
- Prompts to generate system-specific test specifications based on user-selected testing recommendations (Schäfer et al. 2023)
Iterative Development Approach
We begin by setting up a foundational framework based on the selected GitHub repositories and research on ML testing. The framework might not cover all ML systems or testing practices. Therefore, we adopt an iterative development approach by establishing an open and scalable framework to address these considerations. The application will be continuously refined based on contributors’ insights.
Users are encouraged to interpret the generated artifacts with a grain of salt and recognize the evolving nature of ML system testing practices.
Delivery Timeline
Our team follows the timeline below for our product delivery and prioritizes close communication with our partners to ensure that our developments align closely with their expectations.
| Timeline | Milestones |
|---|---|
| Week 1 (Apr 29 - May 3) | Prepare and Present Initial Proposal. Scrape repository data. |
| Week 2 - 3 (May 6 - 17) | Deliver Proposal. Deliver Draft of ML Pipeline Test Checklist. Develop Minimum Viable Product (Test Completeness Score, Missing Test Recommendation) |
| Week 4 - 5 (May 20 - May 31) | Update Test Checklist. Develop Test Function Specification Generator. |
| Week 6 (Jun 3 - Jun 7) | Update Test Checklist. Wrap Up Product. |
| Week 7 (Jun 10 - Jun 14) | Finalize Test Checklist. Perform Product System Test. Present Final Product. Prepare Final Product Report. |
| Week 8 (Jun 17 - Jun 21) | Deliver Final Product. Deliver Final Product Report. |