Model Tuning and Final Results¶
Hyperparameter tuning¶
As noted in our Model Selection discussion, we have decided to tune the hyperparameters of a Random Forest classifer further. Specifically, we tuned the following list of hyperparameters:
n_estimators¶
This hyperparameter controls the number of trees (models) included in the Random Forest. We note that a higher number of trees increases model complexity and have a higher risk of overfitting. We tested a values in the range of 100 to 1000 trees in tuning our model.
criterion¶
This hyperparameter controls the function that is used to measure the quality of a split at a node in a tree within the Random Forest. sklearn allows for either gini or entropy functions to be used. We tested models with both these functions.
max_depth¶
This hyperparameter controls the maximum depth of each tree in the Random Forest. We note that higher values increase model complexity and have a higher risk of overfitting. We tested a range of values from 10 to 100, incremented in steps of 5, in tuning our model.
max_features¶
This is the number of features that are considered when making a split at a node in a tree in the Random Forest. We tested the following values in our model tuning:
autowhich setsmax_features=sqrt(n_features), the square root of the number of features.log2which setsmax_features=log2(n_features), log base 2 of the number of features.
min_samples_split¶
This is the minimum number of samples required to split an internal node of the tree. We tested the values 2, 4, and 8 in our hyperparameter tuning.
min_samples_leaf¶
This is the minimum number of samples required to be at a leaf node. We tested the values 1, 2, and 4 in our hyperparameter tuning.
class_weight¶
This hyperparameter can be used to deal with the imbalance in our training data. Specifically, this hyper parameter controls the weights associated with each class. We tested balanced which uses the values of our target label to automatically adjust weights inversely proportional to class frequencies as n_samples / (n_classes * np.bincount(y)). We also considered a value of None, which does not adjust class weights.
Please note that this is not a full list of the hyperparameters available for tuning in sklearn. For the full list, please see the documentation.
Randomized search¶
In order to tune the hyperparameters of our model we used randomized search cross validation, which is implemented in sklearn with RandomizedSearchCV. We set a budget of 100 models to train. Based on this random search, we found that the following hyperparameters worked the best for our model, in the sense that they obtained the highest recall score of 0.81.
| value | |
|---|---|
| class_weight | balanced |
| criterion | entropy |
| max_depth | 10 |
| max_features | log2 |
| min_samples_leaf | 4 |
| min_samples_split | 4 |
| n_estimators | 892 |
Final test set results¶
Finally, we used our tuned Random Forest model to make predictions on the test set. In order to analyze how well our model did, we have included a confusion matrix and classification report below.
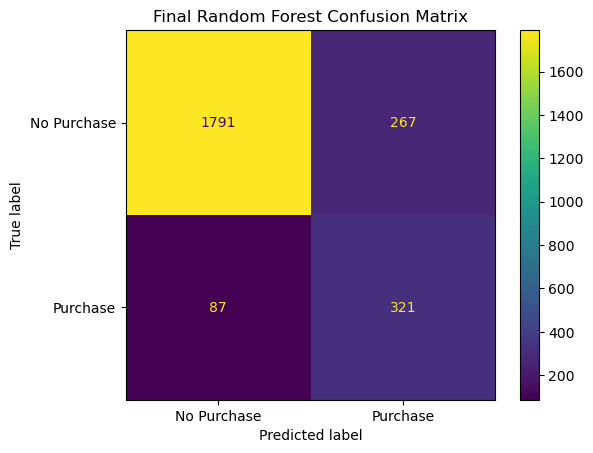
Classification report¶
| precision | recall | f1-score | support | |
|---|---|---|---|---|
| No Purchase | 0.954 | 0.870 | 0.910 | 2058.000 |
| Purchase | 0.546 | 0.787 | 0.645 | 408.000 |
| accuracy | 0.856 | 0.856 | 0.856 | 0.856 |
| macro avg | 0.750 | 0.829 | 0.777 | 2466.000 |
| weighted avg | 0.886 | 0.856 | 0.866 | 2466.000 |
Table.3 - Evaluation metrics for tuned random forest model
Discussion of results¶
Based of Figure 7 and Table 3 we note that our tuned Random Forest obtained the following results on the test set:
1790 true positives, and 321 true negatives
268 false positives, and 87 false negatives
A macro average recall score is 0.830 and the macro average precision score is 0.751
The macro average precision score is above our budget of 0.60 that we set at the beginning of our project
Conclusion¶
We have demonstrated that it is feasible to create a machine learning model to predict purchase conversion using session data in an e-commerce setting. Even though the features in the dataset are high level and aggregated, we are still able to find signals that can help with our prediction problem. Performance may be improved with more granular dataset, such as individual page history data of a user in a session. Deploying a real-time machine learning model for this use case may be challenging. Hence, we recommend to start with simple rule-based triggers on important features like PageValues and BounceRates as an ‘early win’, before transitioning to a machine learning model to futher boost conversion rate.