This is the first in what will hopefully become a series of posts on our curriculum for the Master of Data Science (MDS) program at UBC. Our program is structured as six four-week blocks, each containing four mini-courses, for a total of 24 mini-courses. Each of these mini-courses is about one third the size of a regular university course. The image below summarizes our current schedule:
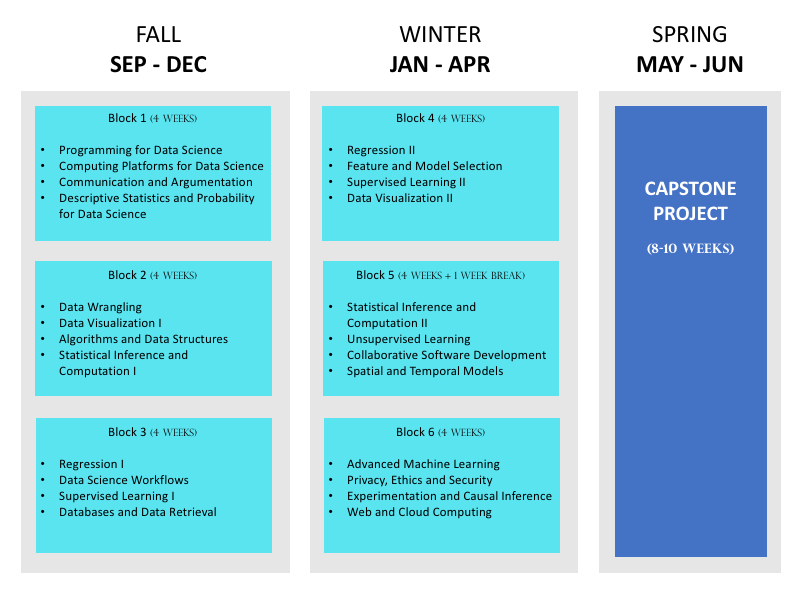
(For more details on each of these courses, see here.)
Internally, we have come to view our courses as falling into one of the following three categories, or streams:
Computer science / machine learning stream
- Programming for Data science
- Algorithms and Data Structures
- Databases and Data Retrieval
- Supervised Learning I
- Supervised Learning II
- Unsupervised Learning
- Feature and Model Selection
- Advanced Machine Learning
Statistics stream
- Descriptive Statistics and Probability for Data Science
- Statistical Inference and Computation I
- Statistical Inference and Computation II
- Regression I
- Regression II
- Spatial and Temporal Models
- Experimentation and Causal Inference
“Data science” stream (tools, workflows, visualization, soft skills)
- Computing Platforms for Data Science
- Communication and Argumentation
- Data Wrangling
- Data Visualization I
- Data Visualization II
- Data Science Workflows
- Privacy, Ethics and Security
- Collaborative Software Development
- Web and Cloud Computing
In this post, I will elaborate on some of the thinking that went into the computer science / machine learning (CS/ML) stream.
The main challenge in designing our curriculum was the very short duration of the program. For example, in our undergraduate CS curriculum here at UBC, we offer two semester-long database courses and three algorithms courses. Thus, we were faced with condensing 6+ months of material down to one month in each case. This is clearly not possible! So, the question became: Since we can’t do it all, what are the absolute essentials for our graduates? We’ve designed our courses according to this question, aiming for both the essentials needed to work as data scientists right after graduation, but also a foundation for effective self-learning into the future.
As an example, in Algorithms and Data Structures, we cover the following topics (roughly one per 90-minute lecture):
- Introduction to time complexity, big O, linear and binary search
- Space complexity, symbol tables, hashing, hash tables
- Recursion
- Trees, binary trees, binary search trees
- Introduction to graphs (directed and undirected)
- Graph searches; breadth-first and depth-first search
- Dynamic programming
- More on discrete optimization
(You can view our labs for this course here.)
Although we can’t go into full detail in only one lecture per topic, I’m pretty happy with how it works out. For more information, we also have a blog post on how we teach discrete optimization.
In the databases course, we focus mainly on writing SQL queries, with a little bit of conceptual background (like ER diagrams) and a bit of XML parsing. This course feels jam-packed; I think this is an area where our alumni often continue their learning on the job, after graduation. That’s not necessarily a bad thing, though, as long as we’re setting them up with a solid foundation to enable effective further learning. Finally, as if SQL/XML weren’t enough for 4 weeks, we may also move in some content on NoSQL, which is currently taught in our Web & Cloud Computing course (another jam-packed offering!).
The machine learning courses focus on when and how to apply ML in a variety of settings. However, this isn’t just about how to use scikit-learn! We talk a lot about how to interpret the inputs (what do these hyperparameters mean?) and outputs (can we trust the predicted class probabilities or feature importances coming out of logistic regression?) of our models. Our unofficial motto for MDS is to teach responsible use of existing data science tools. The first part of the ML sequence, consisting of Supervised Learning I, Unsupervised Learning, and Feature and Model Selection, follow this style. Then, in Supervised Learning II, we deviate from this style a bit and talk about optimization, loss functions, and how to actually implement some of these methods in numerically sane ways (teaching materials available here). This gives students a taste of what it’s like to implement machine learning algorithms, in case they wish to pursue it further, and is also a useful context for deep learning, which comes in the second half of the same course.
The curriculum has also been evolving in the short time since we launched MDS. For example, since we run various Capstone projects each year, we’ve had the opportunity to see what machine learning techniques are most often needed by our partner organizations. Aside from the usual suspects (e.g. classification), some common themes are natural language processing, time series data, and recommender systems. While the earlier machine learning courses are mostly spoken for by essential ML material, our Advanced Machine Learning course serves as a nice venue for these kinds of additions. We’re also in close touch with our growing community of alumni, who often have useful insights on the latest tools and models.
If you enjoyed reading this, stay tuned for posts on the other two streams of the UBC MDS program!
Mike Gelbart is an Instructor in the MDS program and the Department of Computer Science at UBC.