

Lecture 5: Topic Modeling#
UBC Master of Data Science program, 2023-24
Instructor: Varada Kolhatkar
Lecture plan, imports, LO#
Imports#
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
pd.set_option("display.max_colwidth", 200)
Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.
Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
Learning outcomes#
From this lesson you will be able to
Explain the general idea of topic modeling.
Identify and name the two main approaches for topic modeling.
Describe the key differences between Latent Semantic Analysis (LSA) and Latent Dirichlet Allocation (LDA).
Outline the process of data generation within an LDA topic model.
Explain the process of updating topic assignments in the LDA model at a high level.
Explain the importance of preprocessing in topic modeling.
Visualize the topics extracted through topic modeling.
Interpret the output of topic modeling.
Name a few possible ways to evaluate a topic model.
Use coherence scores as a guiding tool to choose the number of topics.
Use
Top2Vecpackage for topic modeling.
1. Why topic modeling?#
1.1 Topic modeling motivation#
Topic modeling introduction activity (~5 mins)
Consider the following documents.
toy_df = pd.read_csv("data/toy_clustering.csv")
toy_df
| text | |
|---|---|
| 0 | famous fashion model |
| 1 | elegant fashion model |
| 2 | fashion model at famous probabilistic topic model conference |
| 3 | fresh elegant fashion model |
| 4 | famous elegant fashion model |
| 5 | probabilistic conference |
| 6 | creative probabilistic model |
| 7 | model diet apple kiwi nutrition |
| 8 | probabilistic model |
| 9 | kiwi health nutrition |
| 10 | fresh apple kiwi health diet |
| 11 | health nutrition |
| 12 | fresh apple kiwi juice nutrition |
| 13 | probabilistic topic model conference |
| 14 | probabilistic topic model |
Discuss the following questions with your neighbour and write your answers in this Google doc.
Suppose you are asked to identify topics discussed in these documents manually. How many topics would you identify?
What are the prominent words associated with each topic?
Are there documents which are a mixture of multiple topics?
Humans are pretty good at reading and understanding a document and answering questions such as
What is it about?
Which documents is it related to?
What if you’re given a large collection of documents on a variety of topics.
Example: A corpus of news articles
Example: A corpus of food magazines
A corpus of scientific articles

(Credit: Dave Blei’s presentation)
It would take years to read all documents and organize and categorize them so that they are easy to search.
You need an automated way
to get an idea of what’s going on in the data or
to pull documents related to a certain topic
Topic modeling gives you an ability to summarize the major themes in a large collection of documents (corpus).
Example: The major themes in a collection of news articles could be
politics
entertainment
sports
technology
…
Topic modeling is a great EDA tool to get a sense of what’s going on in a large corpus.
Some examples
If you want to pull documents related to a particular lawsuit.
You want to examine people’s sentiment towards a particular candidate and/or political party and so you want to pull tweets or Facebook posts related to election.
1.2 How do you do topic modeling?#
A common tool to solve such problems is unsupervised ML methods.
Given the hyperparameter \(K\), the goal of topic modeling is to describe a set of documents using \(K\) “topics”.
In unsupervised setting, the input of topic modeling is
A large collection of documents
A value for the hyperparameter \(K\) (e.g., \(K = 3\))
and the output is
Topic-words association
For each topic, what words describe that topic?
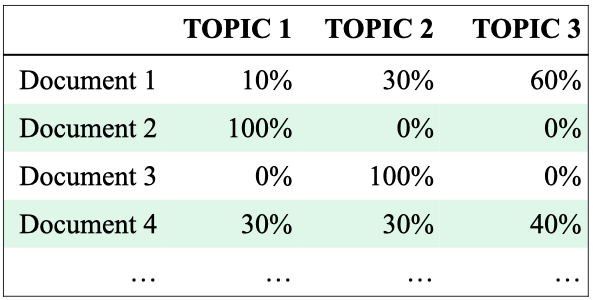
Document-topics association
For each document, what topics are expressed by the document?
Topic modeling: example 1
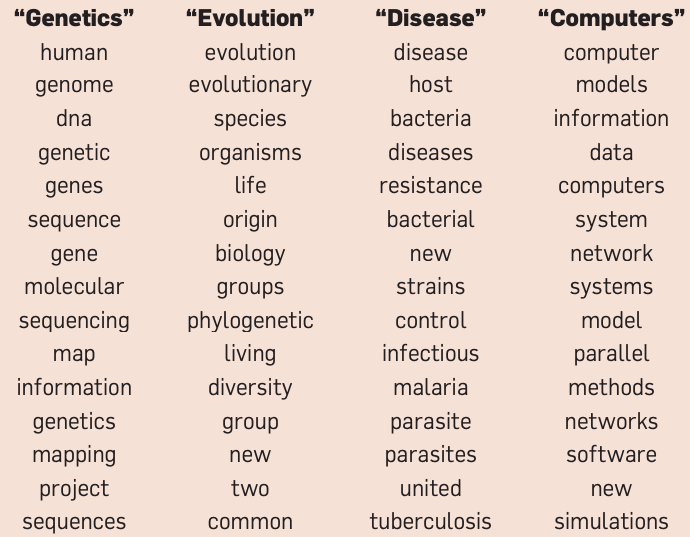
Topic-words association
For each topic, what words describe that topic?
A topic is a mixture of words.

Document-topics association
For each document, what topics are expressed by the document?
A document is a mixture of topics.
Topic modeling example 2: Scientific papers
Topic modeling: Input
Credit: David Blei’s presentation
Topic modeling: output

(Credit: David Blei’s presentation)
Assigning labels is a human thing.
(Credit: David Blei’s presentation)
Topic modeling example 3: LDA topics in Yale Law Journal

(Credit: David Blei’s paper)
Topic modeling example 3: LDA topics in social media
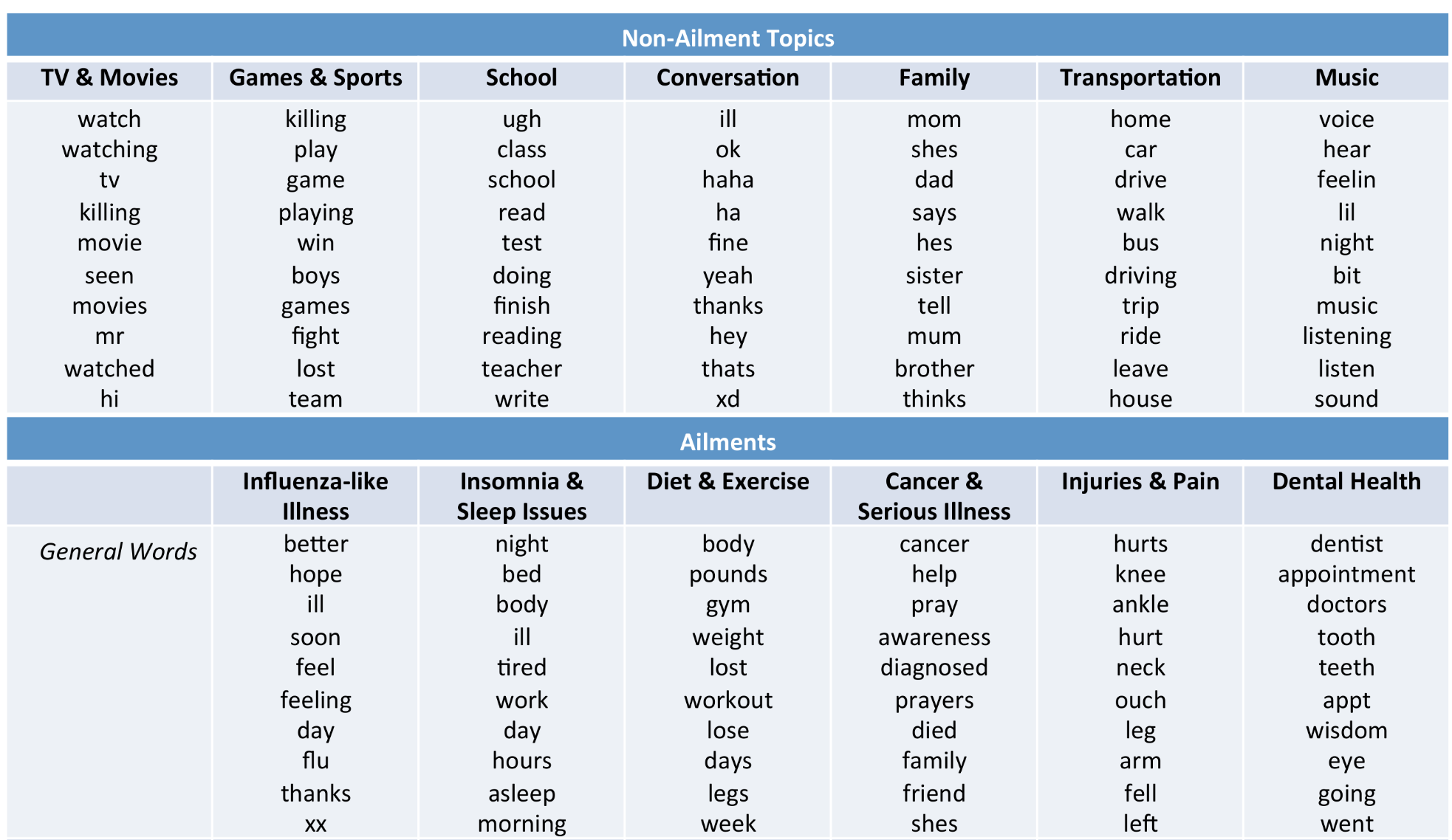
(Credit: Health topics in social media)
Based on the tools in your toolbox what would you use for topic modeling?
There are two main approaches for topic modeling
Topic modeling as matrix factorization (LSA)
Latent Dirichlet Allocation (LDA)
Topic modeling as matrix factorization
We have seen this before in DSCI 563!
You can think of topic modeling as a matrix factorization problem.
Where
\(n \rightarrow \) Number of documents
\(k \rightarrow \) Number of topics
\(d \rightarrow \) Number of features (e.g., the size of vocabulary)
\(Z\) gives us document-topic assignments and \(W\) gives us topic-word assignments.
This is LSA and we used
sklearn’sTruncatedSVDfor matrix factorization using SVD (without centering the data).The idea is to reduce the dimensionality of the data to extract some semantically meaningful components.
Let’s try LSA on the toy dataset above.
toy_df
| text | |
|---|---|
| 0 | famous fashion model |
| 1 | elegant fashion model |
| 2 | fashion model at famous probabilistic topic model conference |
| 3 | fresh elegant fashion model |
| 4 | famous elegant fashion model |
| 5 | probabilistic conference |
| 6 | creative probabilistic model |
| 7 | model diet apple kiwi nutrition |
| 8 | probabilistic model |
| 9 | kiwi health nutrition |
| 10 | fresh apple kiwi health diet |
| 11 | health nutrition |
| 12 | fresh apple kiwi juice nutrition |
| 13 | probabilistic topic model conference |
| 14 | probabilistic topic model |
Let’s get BOW representation of the documents.
from sklearn.decomposition import TruncatedSVD
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer(stop_words="english")
bow = cv.fit_transform(toy_df["text"]).toarray()
bow_df = pd.DataFrame(bow, columns=cv.get_feature_names_out(), index=toy_df["text"])
bow_df
| apple | conference | creative | diet | elegant | famous | fashion | fresh | health | juice | kiwi | model | nutrition | probabilistic | topic | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| text | |||||||||||||||
| famous fashion model | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| elegant fashion model | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| fashion model at famous probabilistic topic model conference | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 2 | 0 | 1 | 1 |
| fresh elegant fashion model | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| famous elegant fashion model | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| probabilistic conference | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| creative probabilistic model | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
| model diet apple kiwi nutrition | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 |
| probabilistic model | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
| kiwi health nutrition | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 |
| fresh apple kiwi health diet | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
| health nutrition | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
| fresh apple kiwi juice nutrition | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 0 |
| probabilistic topic model conference | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 |
| probabilistic topic model | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 |
Let’s extract latent features from this data.
from sklearn.pipeline import make_pipeline
lsa_pipe = make_pipeline(
CountVectorizer(stop_words="english"), TruncatedSVD(n_components=3)
)
Z = lsa_pipe.fit_transform(toy_df["text"]);
pd.DataFrame(
np.round(Z, 4),
columns=["latent topic 1 ", "latent topic 2", "latent topic 3"],
index=toy_df["text"],
)
| latent topic 1 | latent topic 2 | latent topic 3 | |
|---|---|---|---|
| text | |||
| famous fashion model | 1.3170 | -0.1541 | 0.7692 |
| elegant fashion model | 1.2495 | -0.0921 | 0.9877 |
| fashion model at famous probabilistic topic model conference | 2.8596 | -0.4921 | -0.3107 |
| fresh elegant fashion model | 1.3314 | 0.2235 | 1.1163 |
| famous elegant fashion model | 1.4893 | -0.1560 | 1.2093 |
| probabilistic conference | 0.5718 | -0.2149 | -0.8377 |
| creative probabilistic model | 1.1374 | -0.1828 | -0.5709 |
| model diet apple kiwi nutrition | 0.9899 | 1.6467 | -0.1801 |
| probabilistic model | 1.0893 | -0.1682 | -0.4951 |
| kiwi health nutrition | 0.1632 | 1.2857 | -0.2039 |
| fresh apple kiwi health diet | 0.3019 | 1.8677 | -0.0742 |
| health nutrition | 0.0888 | 0.7542 | -0.1332 |
| fresh apple kiwi juice nutrition | 0.3019 | 1.8677 | -0.0742 |
| probabilistic topic model conference | 1.5426 | -0.3380 | -1.0799 |
| probabilistic topic model | 1.3320 | -0.2547 | -0.7839 |
Let’s examine the components learned by LSA.
How much variance is covered by the components?
lsa_pipe.named_steps["truncatedsvd"].explained_variance_ratio_.sum()
0.6558779404028763
W = lsa_pipe.named_steps['truncatedsvd'].components_
W
array([[ 0.06747017, 0.21056851, 0.04815134, 0.05468907, 0.17230783,
0.23986307, 0.34912148, 0.0819255 , 0.02344878, 0.01278109,
0.07437837, 0.72804564, 0.06535676, 0.3612223 , 0.24275193],
[ 0.42900399, -0.08329132, -0.01457154, 0.28013182, -0.00196643,
-0.06394139, -0.05347004, 0.31555664, 0.31147456, 0.14887217,
0.53148783, -0.03665847, 0.44273421, -0.13157525, -0.08646649],
[-0.04364109, -0.29598848, -0.07583183, -0.03377992, 0.44010496,
0.22151674, 0.50099603, 0.1285553 , -0.05464361, -0.00986116,
-0.07072982, 0.04664235, -0.07856237, -0.54170558, -0.28884399]])
print("W.shape: {}".format(W.shape))
vocab = lsa_pipe.named_steps['countvectorizer'].get_feature_names_out()
W.shape: (3, 15)
import sys
sys.path.append("code/.")
from plotting_functions import *
plot_lda_w_vectors(W, ['topic 0', 'topic 1', 'topic 2'], vocab, width=800, height=600)
Let’s print the topics:
W_sorted = np.argsort(W, axis=1)[:, ::-1]
feature_names = np.array(
lsa_pipe.named_steps["countvectorizer"].get_feature_names_out()
)
print_topics(
topics=[0, 1, 2], feature_names=feature_names, sorting=W_sorted, n_words=5
)
topic 0 topic 1 topic 2
-------- -------- --------
model kiwi fashion
probabilistic nutrition elegant
fashion apple famous
topic fresh fresh
famous health model
Our features are word counts.
LSA has learned useful “concepts” or latent features from word count features.
2. Topic modeling with Latent Dirichlet Allocation (LDA)#
Attribution: Material and presentation in the next slides is adapted from Jordan Boyd-Graber’s excellent material on LDA.
Another common approach to topic modeling
A Bayesian, probabilistic, and generative approach
Similar to Gaussian Mixture Models (GMMs), you can think of this as a procedure to generate the data
Developed by David Blei and colleagues in 2003.
One of the most cited papers in the last 20 years.
Produces topics which are more interpretable and distinct from each other.
DISCLAIMER
We won’t go into the math because it’s a bit involved and we do not have the time.
My goal is to give you an intuition of the model and show you how to use it to solve topic modeling problems.
Suppose you are asked to create a probabilistic generative story of how our toy data came to be.
toy_df
| text | |
|---|---|
| 0 | famous fashion model |
| 1 | elegant fashion model |
| 2 | fashion model at famous probabilistic topic model conference |
| 3 | fresh elegant fashion model |
| 4 | famous elegant fashion model |
| 5 | probabilistic conference |
| 6 | creative probabilistic model |
| 7 | model diet apple kiwi nutrition |
| 8 | probabilistic model |
| 9 | kiwi health nutrition |
| 10 | fresh apple kiwi health diet |
| 11 | health nutrition |
| 12 | fresh apple kiwi juice nutrition |
| 13 | probabilistic topic model conference |
| 14 | probabilistic topic model |
2.1 Possible approaches to generate documents#
LDA is a generative model, which means that it comes up with a story that tells us from what distributions our data might have been generated. In other words, our goal is to effectively convey the process of generating observable data (documents, in this case) from hidden or latent variables (topics and their distributions within documents).
Let’s brainstorm some possible ways documents might have been generated.
Let’s assume all documents have \(d\) words and word order doesn’t matter.
Approach 1: Multinomial distribution of words
Assume that each word \(w_j\) comes from a multinomial distribution over all words.
To generate a document with \(d\) words, sample \(d\) words from the multinomial distribution over words.
Drawback: Misses that some documents are about different topics
Want: We want the word distribution to depend upon the topic
Approach 2: Mixture of multinomial distributions of words
How about using a mixture model of “topics”?
Each component of a mixture has its own multinomial distribution over words
To generate a document with \(d\) words
sample a topic \(z\) from the mixture of topics
sample a word \(d\) times from topic \(z\)’s distribution
Drawback: Misses that documents usually contain multiple topics
Approach 3: Multi-topic mixture of multinomial
Let’s introduce a vector \(\theta\) of topic proportions associated with each document
To generate a document with \(d\) words given probabilities \(\theta\)
sample \(d\) topics from \(\theta\)
for each sampled topic, sample a word from the topic distribution
How do we compute \(\theta\) for a new document?
Approach 4: Latent Dirichlet Allocation (LDA)
LDA puts a prior on topic proportions \(\theta\)
To generate a document with \(d\) words
sample document topic proportions \(\theta\) from its prior
sample \(d\) topics from \(\theta\)
for each sampled topic, sample a word from the topic distribution.
2.2 Generative story of LDA#
The story that tells us how our data was generated.
The generative story of LDA to create Document 1 below:
Pick a topic from the topic distribution for Document 1.
Pick a word from the selected topic’s word distribution.
Not a realistic story but a mathematically useful story.
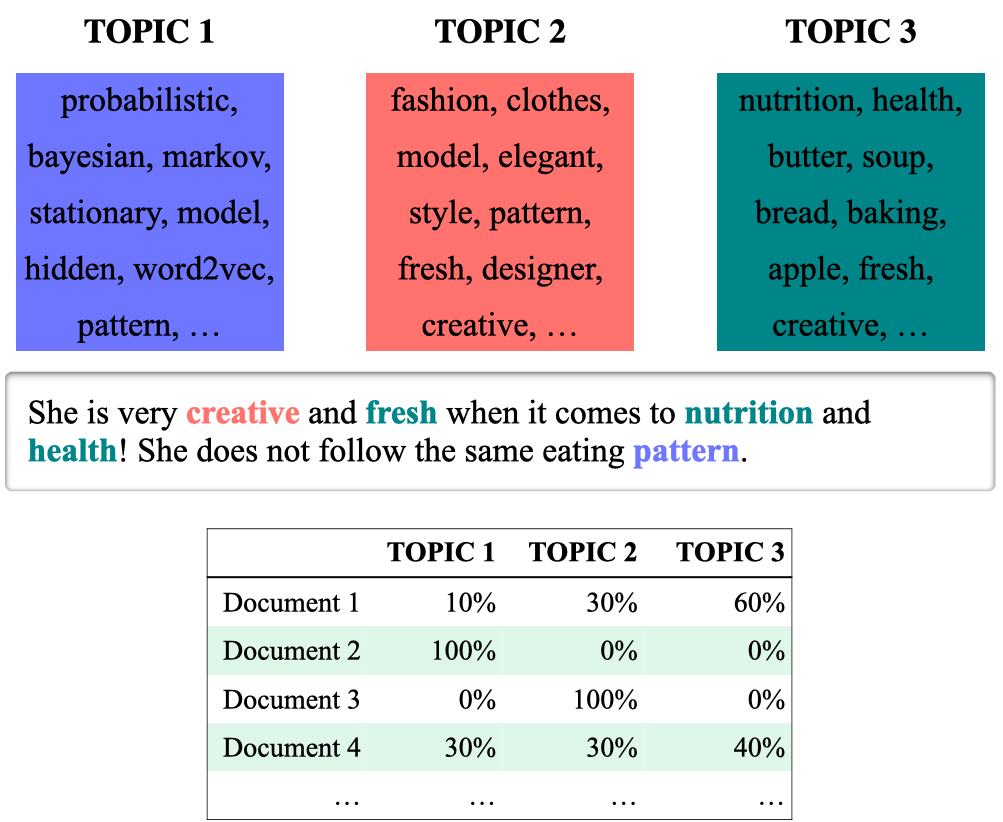
Similar to LSA, we fix the number of topics \(K\)
Topic-word distribution: Each topic is a multinomial distribution over words
Document-topic distribution: Each document is a multinomial distribution over corpus-wide topics
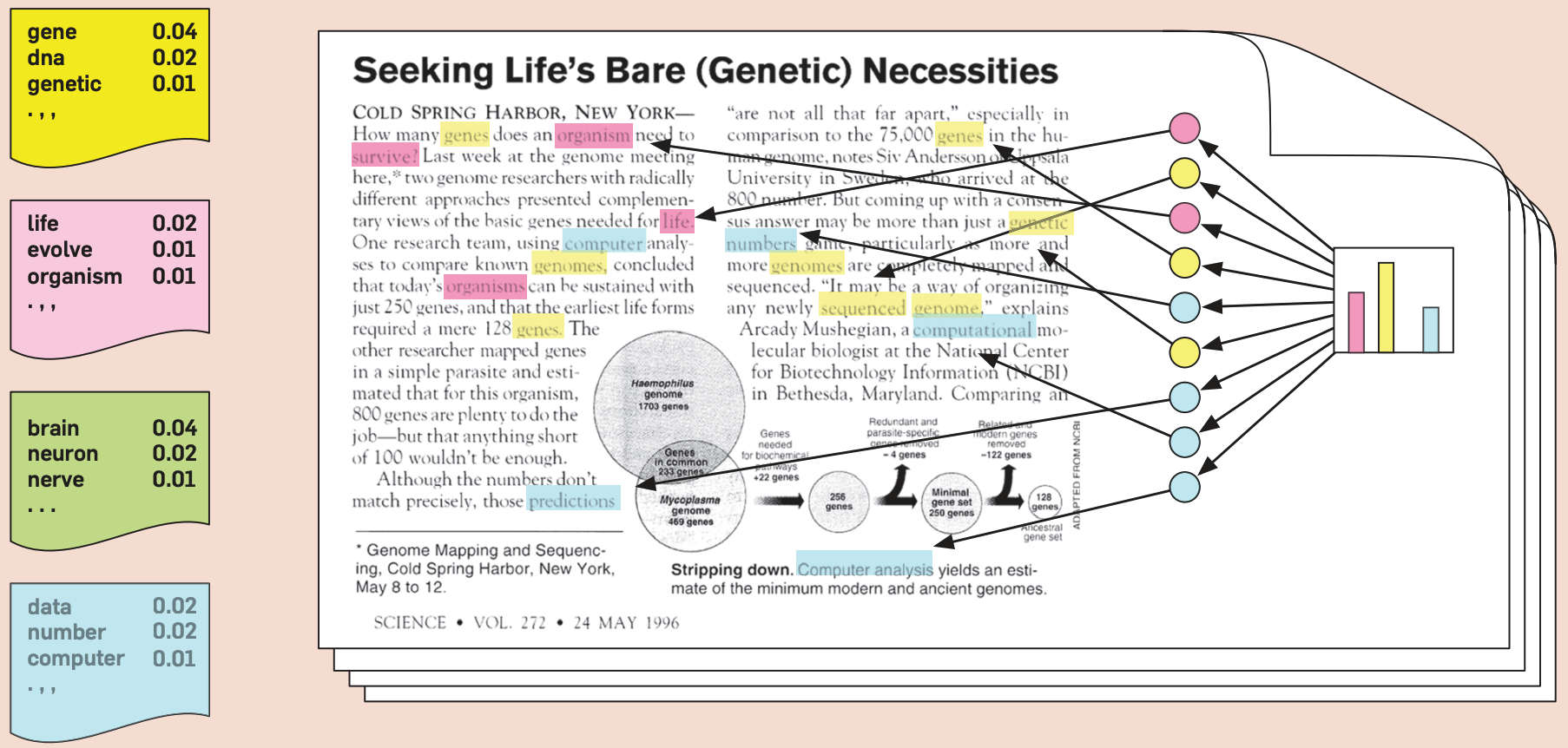
(Credit: David Blei’s presentation)
Topic-word distribution
If I pick a word from the pink topic, the probability of it being life is 0.02, evolve is 0.01, and organism is 0.01.
Equivalent to the components \(W\) in LSA.
Document-topic distribution
If I pick a random word from the document, how likely it’s going to be from yellow topic vs. pink topic vs. cyan topic.
Equivalent to the latent representation \(Z\) in LSA.
2.3 LDA inference (high-level)#
Our goal is to infer the underlying distributional structure that explains the observed data.
How can we estimate the following latent variables that characterize the underlying topic structure of the document collection?
the topic assignments for each word in a given document
the topic-word distributions
the document-topic distributions
Typically fit using Bayesian inference
Most common algorithm is MCMC
Check out Appendix D for more details.
Note
(Optional) The Dirichlet distribution is used as a prior distribution in the Bayesian inference process of estimating the topic-word and document-topic distributions because it has some desirable properties such as being a conjugate prior, which means that the posterior has the same form as that of the prior which allows us to compute the posterior distribution of the topic-word and document-topic distributions, given the observed data (i.e., the words in the documents) analytically in closed form, which simplifies the inference process.
How do we find the posterior distribution?
We are interested in the posterior distribution, i.e., the updated probability distribution of the topic assignments for each word in the document, given the observed words in the document and the current estimate of the topic proportions for that document
How do we find it?
Gibbs sampling (very accurate but very slow, appropriate for small datasets)
Variational inference (faster but less accurate, extension of expectation maximization, appropriate for medium to large datasets)
Next let’s look at an intuition of Gibbs sampling for topic modeling.
Main Steps in Gibbs Sampling for LDA
Initialization: Assign each word in each document randomly to a topic. This initial assignment gives us a starting point for our counts in the “word-topic” and “document-topic” count tables.
Update Word-Topic Assignment: For each word in each document, perform the following steps:
Decrease the counts in our count tables (“word-topic counts” and “document-topic counts”) for the current word and its current topic assignment.
Calculate the probability of each topic for this word, based on the current state of counts (both the document’s topic distribution and the word’s topic distribution across all documents).
Sample a new topic for the word based on these probabilities.
Increase the counts in the count tables to reflect this new topic assignment.
Iterate: Repeat the above step for each word in a pass. Multiple passes are done until the assignments converge, which means the changes in topic assignments between sweeps are minimal or below a certain threshold.
After many passes, we can estimate the document-topic distributions and the topic-word distributions from the count tables. These distributions are our model that tells us the topics present in the documents and the words associated with each topic.
Gibbs sampling example
Suppose the number of topics is \(3\) and the topics are numbered \(1, 2, 3\)
initialization: Randomly assign each word in each document to one of the topics.
The same word in the vocabulary may have different topic assignments in different instances.

With the current topic assignment, here are the topic counts in our document
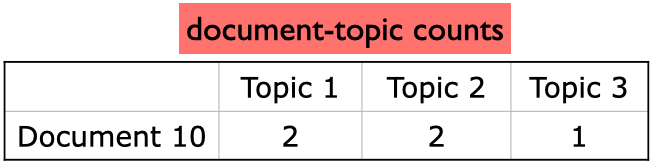
And these are word topic counts in the corpus, i.e., how much each word in the document is liked by each topic.
For each word in our current document (Document 10), calculate how often that word occurs with each topic in all documents.
Note that the counts in the toy example below are made-up counts
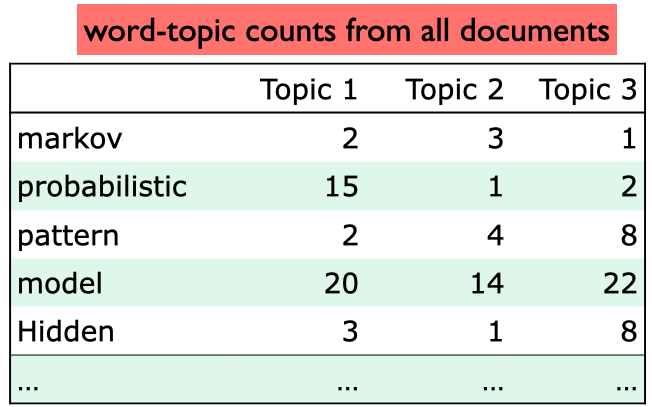
How to update Word-Topic Assignment?
Suppose our sampled word-topic assignment is the word probabilistic in Document 10 with assigned topic 3.
Goal: update this word topic assignment.
Step 1: Decrement counts
We want to update the word topic assignment of probabilistic and Topic 3.
How often does Topic 3 occur in Document 10? Once.
How often does the word probabilistic occur with Topic 3 in the corpus? Twice.
Decrement the count of the word from the word-topic counts.
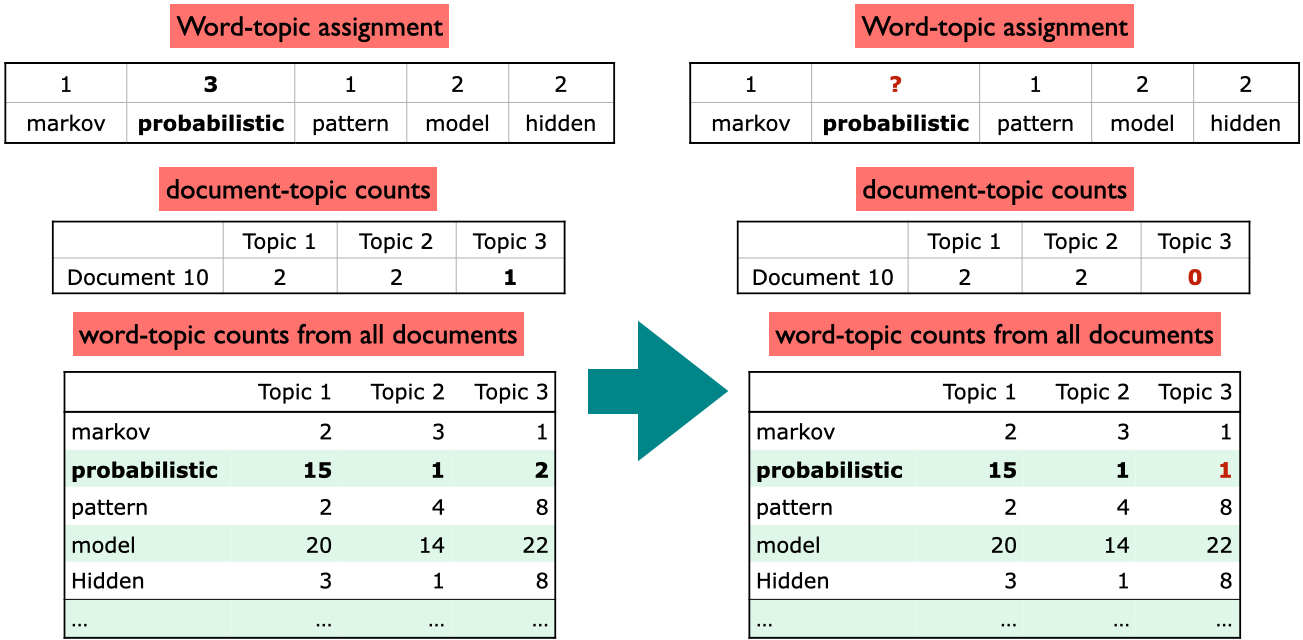
Step 2: Calculating conditional probability distribution
What is the topic preference of Document 10?
What is the preference of the word probabilistic for each topic?
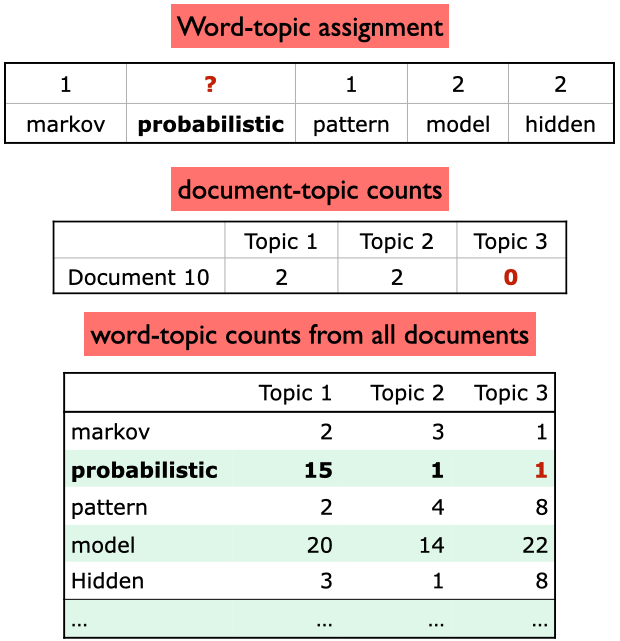
Document 10 likes Topic 1
Topic 1 likes the word probabilistic – it tends to occur a lot in Topic 1.
Step 3: Updating topic assignment
So update the topic of the current word probabilistic in document 10 to topic 1
Update the document-topic and word-topic counts accordingly.
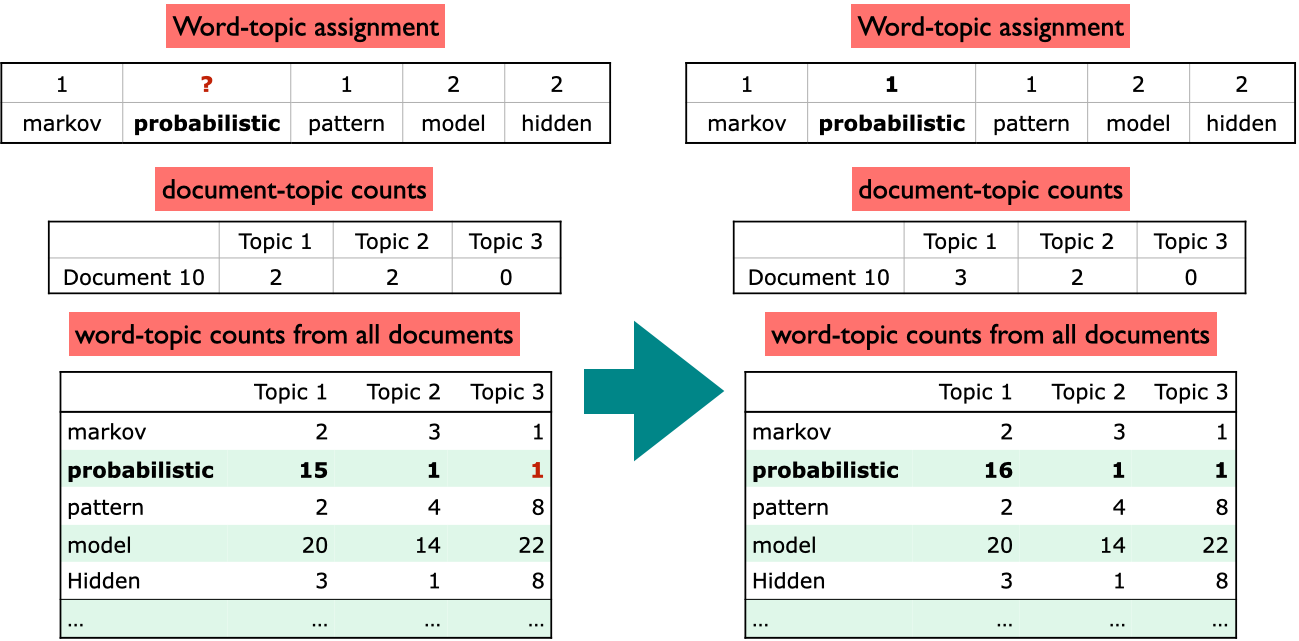
Conclusion
In one pass, the algorithm repeats the above steps for each word in the corpus
If you do this for several passes, meaningful topics emerge.

❓❓ Questions for you#
Exercise 5.1: Select all of the following statements which are True (iClicker)#
iClicker join link: https://join.iclicker.com/ZTLY
(A) Latent Dirichlet Allocation (LDA) is an unsupervised approach.
(B) The assumption in topic modeling is that different topics tend to use different words.
(C) We could use LSA for topic modeling, where \(Z\) gives us the mixture of topics per document.
(D) In LDA topic model, a document is a mixture of multiple topics.
(E) If I train a topic model on a large collection of news articles with K = 10, I would get 10 topic labels (e.g., sports, culture, politics, finance) as output.
Exercise 5.1: V’s Solutions!
A, B, C, D
Exercise 5.2: Questions for class discussion#
What’s the difference between topic modeling and document clustering using algorithms such as K-Means clustering?
Imagine that you are using LSA for topic modeling, where \(X\) is bag-of-words representation of \(N\) documents and \(V\) features (number of words in the vocabulary). Explain which matrix would give you word distribution over topics and which matrix would give you topic distribution over documents. $\(X_{N \times V} = Z_{N \times K} W_{K \times V}\)$
Exercise 5.2: V’s Solutions!
In clustering with K-Means, documents are grouped based on a similarity measure, and each document is assigned to a single cluster. In contrast, topic modeling produces distributions over words for each topic, as well as distributions over topics per document. Topic modeling can be thought of as a form of soft clustering, where documents are assigned to multiple topics based on their probability distributions rather than a single cluster.
\(Z\) would give distribution over topics per document and \(W\) would give distribution over words per topic.
3. Topic modeling with Python#
3.1 Topic modeling pipeline#
There are three components in topic modeling pipeline.
Preprocess your corpus.
Train LDA using
sklearnorGensim.Interpret your topics.
Let’s work with a slightly bigger corpus. We’ll extract text from a few Wikipedia articles and apply topic modeling on these texts.
import wikipedia
queries = [
"Artificial Intelligence",
"Supervised Machine Learning",
"Supreme Court of Canada",
"Peace, Order, and Good Government",
"Canadian constitutional law",
"ice hockey",
"Google company",
"Google litigation",
]
wiki_dict = {"wiki query": [], "text": []}
for i in range(len(queries)):
text = wikipedia.page(queries[i]).content
wiki_dict["text"].append(text)
print(len(text))
wiki_dict["wiki query"].append(queries[i])
wiki_df = pd.DataFrame(wiki_dict)
wiki_df
71729
18529
20767
16157
16998
58485
57572
19942
| wiki query | text | |
|---|---|---|
| 0 | Artificial Intelligence | Artificial intelligence (AI), in its broadest sense, is intelligence exhibited by machines, particularly computer systems. It is a field of research in computer science that develops and studies m... |
| 1 | Supervised Machine Learning | Supervised learning (SL) is a paradigm in machine learning where input objects (for example, a vector of predictor variables) and a desired output value (also known as human-labeled supervisory si... |
| 2 | Supreme Court of Canada | The Supreme Court of Canada (SCC; French: Cour suprême du Canada, CSC) is the highest court in the judicial system of Canada. It comprises nine justices, whose decisions are the ultimate applicati... |
| 3 | Peace, Order, and Good Government | In many Commonwealth jurisdictions, the phrase "peace, order, and good government" (POGG) is an expression used in law to express the legitimate objects of legislative powers conferred by statute.... |
| 4 | Canadian constitutional law | Canadian constitutional law (French: droit constitutionnel du Canada) is the area of Canadian law relating to the interpretation and application of the Constitution of Canada by the courts. All la... |
| 5 | ice hockey | Ice hockey (or simply hockey) is a team sport played on ice skates, usually on an ice skating rink with lines and markings specific to the sport. It belongs to a family of sports called hockey. In... |
| 6 | Google company | Google LLC ( , GOO-ghəl) is an American multinational corporation and technology company focusing on online advertising, search engine technology, cloud computing, computer software, quantum compu... |
| 7 | Google litigation | Google has been involved in multiple lawsuits over issues such as privacy, advertising, intellectual property and various Google services such as Google Books and YouTube. The company's legal depa... |
Preprocessing the corpus
Preprocessing is crucial!
Tokenization, converting text to lower case
Removing punctuation and stopwords
Discarding words with length < threshold or word frequency < threshold
Possibly lemmatization: Consider the lemmas instead of inflected forms.
Depending upon your application, restrict to specific part of speech;
For example, only consider nouns, verbs, and adjectives
We’ll use spaCy for preprocessing.
# !python -m spacy download en_core_web_md
import spacy
nlp = spacy.load("en_core_web_md")
def preprocess_spacy(
doc,
min_token_len=2,
irrelevant_pos=["ADV", "PRON", "CCONJ", "PUNCT", "PART", "DET", "ADP"],
):
"""
Given text, min_token_len, and irrelevant_pos carry out preprocessing of the text
and return a preprocessed string.
Parameters
-------------
doc : (spaCy doc object)
the spacy doc object of the text
min_token_len : (int)
min_token_length required
irrelevant_pos : (list)
a list of irrelevant pos tags
Returns
-------------
(str) the preprocessed text
"""
clean_text = []
for token in doc:
if (
token.is_stop == False # Check if it's not a stopword
and len(token) > min_token_len # Check if the word meets minimum threshold
and token.pos_ not in irrelevant_pos
): # Check if the POS is in the acceptable POS tags
lemma = token.lemma_ # Take the lemma of the word
clean_text.append(lemma.lower())
return " ".join(clean_text)
wiki_df["text_pp"] = [preprocess_spacy(text) for text in nlp.pipe(wiki_df["text"])]
wiki_df
| wiki query | text | text_pp | |
|---|---|---|---|
| 0 | Artificial Intelligence | Artificial intelligence (AI), in its broadest sense, is intelligence exhibited by machines, particularly computer systems. It is a field of research in computer science that develops and studies m... | artificial intelligence broad sense intelligence exhibit machine computer system field research computer science develop study method software enable machine perceive environment use learning inte... |
| 1 | Supervised Machine Learning | Supervised learning (SL) is a paradigm in machine learning where input objects (for example, a vector of predictor variables) and a desired output value (also known as human-labeled supervisory si... | supervised learning paradigm machine learning input object example vector predictor variable desire output value know human label supervisory signal train model training datum process build functi... |
| 2 | Supreme Court of Canada | The Supreme Court of Canada (SCC; French: Cour suprême du Canada, CSC) is the highest court in the judicial system of Canada. It comprises nine justices, whose decisions are the ultimate applicati... | supreme court canada scc french cour suprême canada csc high court judicial system canada comprise justice decision ultimate application canadian law grant permission litigant year appeal decision... |
| 3 | Peace, Order, and Good Government | In many Commonwealth jurisdictions, the phrase "peace, order, and good government" (POGG) is an expression used in law to express the legitimate objects of legislative powers conferred by statute.... | commonwealth jurisdiction phrase peace order good government pogg expression law express legitimate object legislative power confer statute phrase appear imperial acts parliament letters patent co... |
| 4 | Canadian constitutional law | Canadian constitutional law (French: droit constitutionnel du Canada) is the area of Canadian law relating to the interpretation and application of the Constitution of Canada by the courts. All la... | canadian constitutional law french droit constitutionnel canada area canadian law relate interpretation application constitution canada court law canada provincial federal conform constitution law... |
| 5 | ice hockey | Ice hockey (or simply hockey) is a team sport played on ice skates, usually on an ice skating rink with lines and markings specific to the sport. It belongs to a family of sports called hockey. In... | ice hockey hockey team sport play ice skate ice skating rink line marking specific sport belong family sport call hockey ice hockey oppose team use ice hockey stick control advance shoot closed vu... |
| 6 | Google company | Google LLC ( , GOO-ghəl) is an American multinational corporation and technology company focusing on online advertising, search engine technology, cloud computing, computer software, quantum compu... | google llc goo ghəl american multinational corporation technology company focus online advertising search engine technology cloud computing computer software quantum computing commerce consumer el... |
| 7 | Google litigation | Google has been involved in multiple lawsuits over issues such as privacy, advertising, intellectual property and various Google services such as Google Books and YouTube. The company's legal depa... | google involve multiple lawsuit issue privacy advertising intellectual property google service google books youtube company legal department expand 100 lawyer year business 2014 grow 400 lawyer go... |
Training LDA with sklearn
docs = wiki_df["text_pp"]
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer()
dtm = vectorizer.fit_transform(wiki_df["text_pp"])
from sklearn.decomposition import LatentDirichletAllocation
n_topics = 3
lda = LatentDirichletAllocation(
n_components=n_topics, learning_method="batch", max_iter=10, random_state=0
)
document_topics = lda.fit_transform(dtm)
print("lda.components_.shape: {}".format(lda.components_.shape))
lda.components_.shape: (3, 4858)
sorting = np.argsort(lda.components_, axis=1)[:, ::-1]
feature_names = np.array(vectorizer.get_feature_names_out())
print_topics(
topics=range(3),
feature_names=feature_names,
sorting=sorting,
topics_per_chunk=5,
n_words=10,
)
topic 0 topic 1 topic 2
-------- -------- --------
court learning google
law intelligence hockey
provincial algorithm player
federal machine team
government learn ice
power problem play
canada displaystyle league
justice datum game
case human company
supreme artificial puck
Training LDA with gensim
I’ll also show you how to do topic modeling with gensim, which we used for
Word2Vec, because it’s more flexible.
To train an LDA model with gensim, you need
Document-term matrix
Dictionary (vocabulary)
The number of topics (\(K\)):
num_topicsThe number of passes:
passes
Let’s first create a dictionary using
corpora.Dictionary.It has two useful methods
token2idgives token to index mappingdoc2bowcreates bag-of-words representation of a given document
import gensim
from gensim.corpora import Dictionary
corpus = [doc.split() for doc in wiki_df["text_pp"].tolist()]
dictionary = Dictionary(corpus) # Create a vocabulary for the lda model
list(dictionary.token2id.items())[:4]
[('"criticism', 0),
('"generative', 1),
('0070087705.these', 2),
('0134610993', 3)]
pd.DataFrame(
dictionary.token2id.keys(), index=dictionary.token2id.values(), columns=["Word"]
)
| Word | |
|---|---|
| 0 | "criticism |
| 1 | "generative |
| 2 | 0070087705.these |
| 3 | 0134610993 |
| 4 | 127 |
| ... | ... |
| 4988 | window |
| 4989 | windows |
| 4990 | wiretap |
| 4991 | writer |
| 4992 | yuan |
4993 rows × 1 columns
Now let’s convert our corpus into document-term matrix for LDA using
dictionary.doc2bow.For each document, it stores the frequency of each token in the document in the format (token_id, frequency).
doc_term_matrix = [dictionary.doc2bow(doc) for doc in corpus]
doc_term_matrix[1][:20]
[(59, 4),
(73, 1),
(77, 3),
(78, 1),
(84, 1),
(85, 1),
(88, 3),
(121, 51),
(128, 1),
(141, 4),
(143, 1),
(157, 1),
(158, 1),
(159, 4),
(160, 3),
(173, 1),
(177, 1),
(184, 2),
(193, 2),
(207, 3)]
Now we are ready to train an LDA model with Gensim!
from gensim.models import LdaModel
num_topics = 3
lda = LdaModel(
corpus=doc_term_matrix,
id2word=dictionary,
num_topics=num_topics,
random_state=42,
passes=10,
)
We can examine the topics and topic distribution for a document in our LDA model
lda.print_topics(num_words=5) # Topics
[(0,
'0.011*"algorithm" + 0.009*"function" + 0.009*"learn" + 0.008*"learning" + 0.008*"training"'),
(1,
'0.031*"google" + 0.013*"hockey" + 0.011*"court" + 0.008*"player" + 0.008*"team"'),
(2,
'0.009*"intelligence" + 0.007*"machine" + 0.007*"problem" + 0.006*"artificial" + 0.006*"human"')]
print("Document label: ", wiki_df.iloc[1,0])
print("Topic assignment for document: ", lda[doc_term_matrix[7]]) # Topic distribution
Document label: Supervised Machine Learning
Topic assignment for document: [(1, 0.99961084)]
topic_assignment = sorted(lda[doc_term_matrix[1]], key=lambda x: x[1], reverse=True)
df = pd.DataFrame(topic_assignment, columns=["topic id", "probability"])
df
| topic id | probability | |
|---|---|---|
| 0 | 0 | 0.999517 |
new_doc = "After the court yesterday lawyers working on Google lawsuits went to a ice hockey game."
pp_new_doc = preprocess_spacy(nlp(new_doc))
pp_new_doc
'court yesterday lawyer work google lawsuit go ice hockey game'
bow_vector = dictionary.doc2bow(pp_new_doc.split())
topic_assignment = sorted(lda[bow_vector], key=lambda x: x[1], reverse=True)
df = pd.DataFrame(topic_assignment, columns=["topic id", "probability"])
df
| topic id | probability | |
|---|---|---|
| 0 | 1 | 0.931061 |
| 1 | 2 | 0.034830 |
| 2 | 0 | 0.034109 |
Main hyperparameters:
num_topicsorK: The number of requested latent topics to be extracted from the training corpus.alpha: A-priori belief on document-topic distribution. When you setalphaas a scalar, it applies symmetrically across all topics, meaning each topic has the same prior importance in documents before observing the actual words. In such cases:A lower
alphaencourages the model to assign fewer topics to each document, leading to a more sparse representation.A higher
alphasuggests that documents are likely to contain a mixture of more topics.
eta(often referred to asbetain the literature): A-priori belief on topic-word distribution. When you setalphaas a scalar, it applies symmetrically across all topics, meaning each topic has the same prior importance in documents before observing the actual words. In such cases:A lower
etaindicates that each topic is formed by a smaller set of wordsA higher
etaallows topics to be more broadly defined by a large set of words
There is also an auto option for both hyperparameters alpha and eta which learns an asymmetric prior from the data. Check the documentation
3.2 A few comments on evaluation#
In topic modeling we would like each topic to have some semantic theme which is interpretable by humans.
The idea of a topic model is to tell a story to humans and that’s what we should care about and evaluate.
(Credit: Health topics in social media)
A few ways to evaluate a topic model
Eye balling top \(n\) words or documents with high probability for each topic.
Human judgments
Ask humans to evaluate a topic model and whether they are able to tell a coherent story about the collection of documents using the topic model.
Word intrusion
Extrinsic evaluation
If you are using topic modeling as features in tasks such as sentiment analysis or machine translation, evaluate whether topic model with the current hyperparameters improves the results of that task or not.
Quantifying topic interpretability
Coherence scores
Human judgments: Word intrusion
Word intrusion: Take high probability words from a topic. Now add a high probability word from another topic to this topic.
Likely words from old topic
dentist, appointment, doctors, tooth
Likely words from old topic + word intrusion
dentist, mom, appointment, doctors, tooth
Are we able to distinguish this odd word out from the original topic?
Coherence models provide a framework to evaluate the coherence of the topic by measuring the degree of semantic similarity between most likely words in the topic.
You can calculate coherence scores using
Gensim’sCoherenceModel.Ranges from -1 to 1
Roughly, high coherence score means the topics are semantically interpretable and low coherence scores means they are not semantically similar.
Let’s try it out on our toy data.
# Compute Coherence Score
from gensim.models import CoherenceModel
K = [1, 2, 3, 4, 5, 6]
coherence_scores = []
for num_topics in K:
lda = LdaModel(
corpus=doc_term_matrix,
id2word=dictionary,
num_topics=num_topics,
random_state=42,
passes=10,
)
coherence_model_lda = CoherenceModel(
model=lda, texts=corpus, dictionary=dictionary, coherence="c_v"
)
coherence_scores.append(coherence_model_lda.get_coherence())
df = pd.DataFrame(coherence_scores, index=K, columns=["Coherence score"])
df
| Coherence score | |
|---|---|
| 1 | 0.228784 |
| 2 | 0.361770 |
| 3 | 0.329059 |
| 4 | 0.497291 |
| 5 | 0.665912 |
| 6 | 0.557379 |
df.plot(title="Coherence scores", xlabel="num_topics", ylabel="Coherence score");
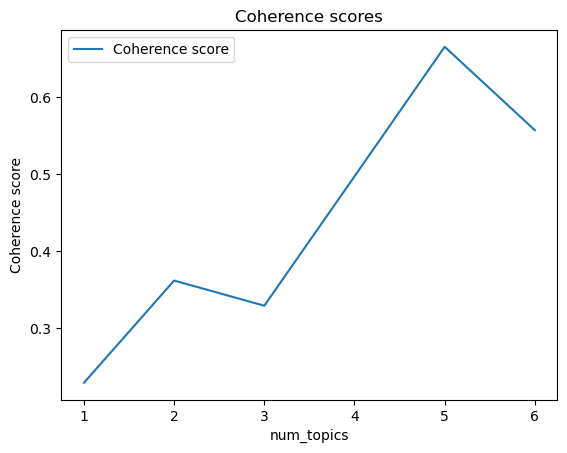
We are getting the best coherence score with num_topics = 4. That said, similar to other methods introduced as a guiding tool to choose the optimal hyperparameters, take this with a grain of salt. The model with highest coherence score is not necessarily going to be the best topic model. It’s always a good idea to manually examine the topics resulted by the chosen number of topics and examine whether you are able to make sense of these topics or or not before finalizing the number of topics. In the end our goal is to get human interpretable topics, and that’s what we should try to focus on.
If you want to jointly optimize num_topics, alpha, and eta, you can do grid search or random search with coherence score as the evaluation metric.
(Optional) Visualize topics
You can also visualize the topics using pyLDAvis.
pip install pyLDAvis
Do not install it using
conda. They have made some changes in the recent version andcondabuild is not available for this version yet.
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
# import gensim
# import pyLDAvis.gensim_models as gensimvis
# import pyLDAvis
# vis = gensimvis.prepare(lda, doc_term_matrix, dictionary, sort_topics=False)
# pyLDAvis.display(vis)
4. (Optional) Some recent topic modeling tools#
4.1 Topic2Vec#
What are some limitations of LDA and LSA?
Need to know the number of topics in advance, which is hard for large and unfamiliar datasets
Quality of topics is very much dependent upon the quality of preprocessing
They use bag-of-words (BOW) representations of documents as input which ignore word semantics.
The words study and studying would be treated as different words despite their semantic similarity
Stemming or lemmatization can address this but lemmatization doesn’t help to recognize height and tall are similar
How does it work?
STEP 1: Create jointly embedded document and word vectors using Doc2Vec or Universal Sentence Encoder or BERT Sentence Transformer.
STEP 2: Create lower dimensional embedding of document vectors using UMAP.
STEP 3: Find dense areas of documents using HDBSCAN.
STEP 4: For each dense area calculate the centroid of document vectors in original dimension, this is the topic vector.
STEP 5: Find n-closest word vectors to the resulting topic vector.
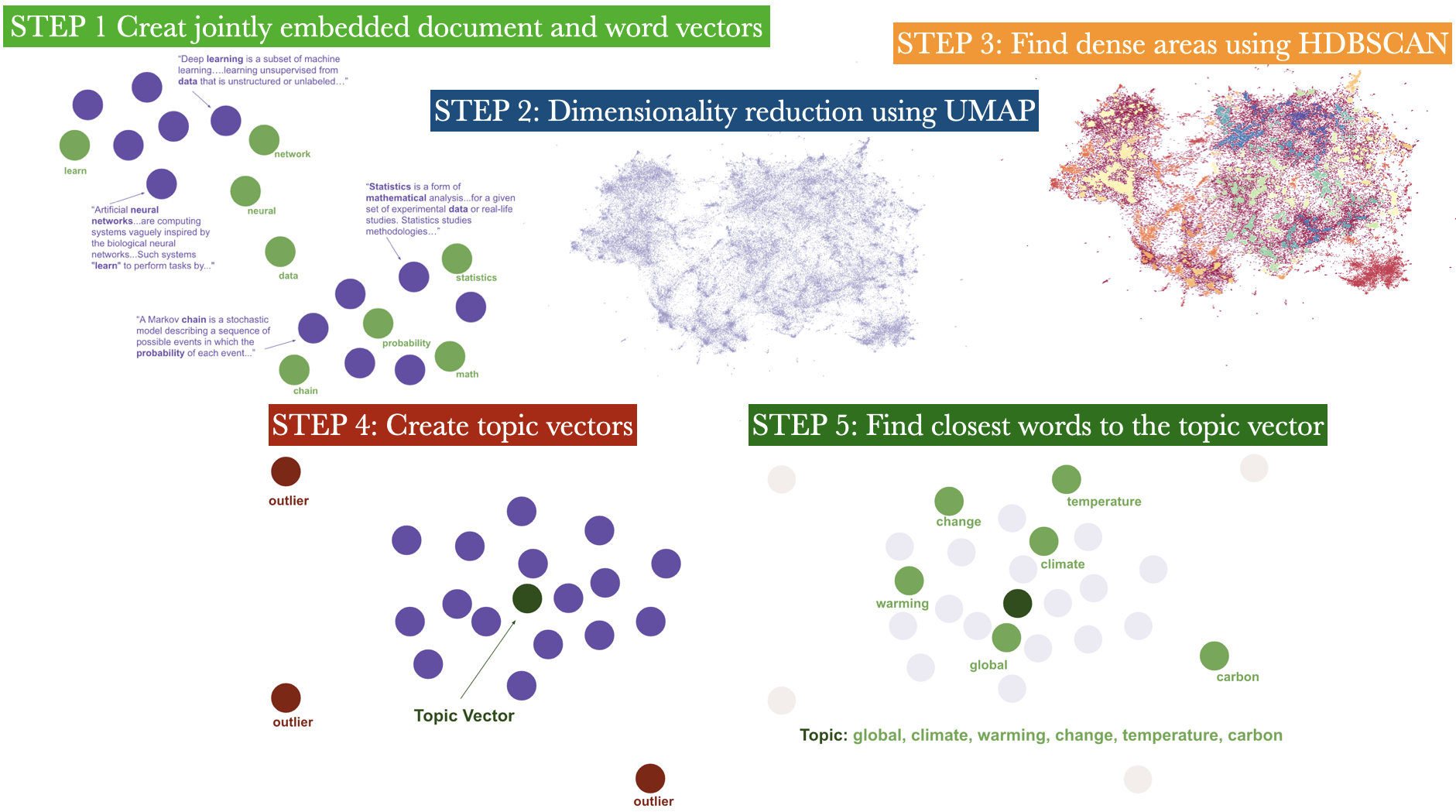
Let’s try it out to identify topics from Ted talk titles.
talks_df = pd.read_csv('data/20221013_ted_talks.csv')
talks_df['title']
0 Averting the climate crisis
1 Simplicity sells
2 Greening the ghetto
3 The best stats you've ever seen
4 Do schools kill creativity?
...
5696 Is inequality inevitable?
5697 4 ways to design a disability-friendly future
5698 Can exercise actually "boost" your metabolism?
5699 How did they build the Great Pyramid of Giza?
5700 How to squeeze all the juice out of retirement
Name: title, Length: 5701, dtype: object
documents = talks_df['title'].to_list()
from top2vec import Top2Vec
model = Top2Vec(documents,embedding_model='distiluse-base-multilingual-cased', min_count=5)
2024-04-08 18:25:27,172 - top2vec - INFO - Pre-processing documents for training
/Users/kvarada/miniconda3/envs/575/lib/python3.12/site-packages/sklearn/feature_extraction/text.py:525: UserWarning:
The parameter 'token_pattern' will not be used since 'tokenizer' is not None'
2024-04-08 18:25:27,373 - top2vec - INFO - Downloading distiluse-base-multilingual-cased model
2024-04-08 18:25:30,472 - top2vec - INFO - Creating joint document/word embedding
2024-04-08 18:25:40,379 - top2vec - INFO - Creating lower dimension embedding of documents
Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.
2024-04-08 18:25:52,296 - top2vec - INFO - Finding dense areas of documents
2024-04-08 18:25:52,497 - top2vec - INFO - Finding topics
Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.
# How many topics has it learned?
model.get_num_topics()
64
# What are the topic sizes?
topic_sizes, topic_nums = model.get_topic_sizes()
topic_sizes
array([311, 278, 222, 204, 179, 146, 139, 133, 131, 130, 128, 122, 121,
120, 119, 118, 106, 106, 103, 101, 99, 99, 99, 96, 96, 94,
90, 88, 84, 83, 79, 76, 74, 70, 70, 69, 68, 67, 67,
64, 57, 56, 55, 55, 53, 53, 52, 51, 51, 49, 47, 47,
46, 44, 44, 39, 39, 38, 33, 32, 31, 30, 27, 23])
# What are the topic words?
topic_words, word_scores, topic_nums = model.get_topics(1)
topic_words
array([['why', 'reasons', 'reason', 'causes', 'how', 'como', 'autism',
'anxiety', 'co', 'diseases', 'habits', 'depression', 'for',
'disease', 'fear', 'what', 'hate', 'addiction', 'never',
'genetic', 'poverty', 'sick', 'instead', 'myths', 'hunger',
'fallacy', 'vaccines', 'grief', 'when', 'cancer', 'que',
'always', 'about', 'pain', 'empathy', 'tips', 'suicide', 'drugs',
'crisis', 'avoid', 'mysteries', 'para', 'vaccine', 'pandemics',
'as', 'riddle', 'ourselves', 'don', 'matters', 'strangers']],
dtype='<U14')
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
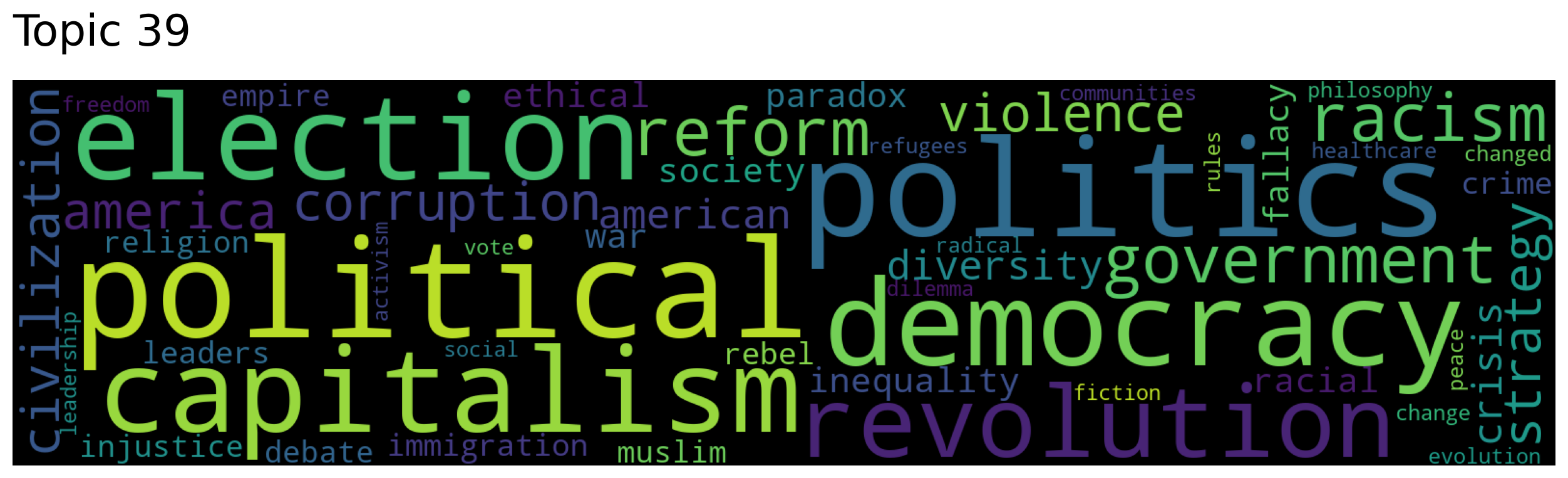
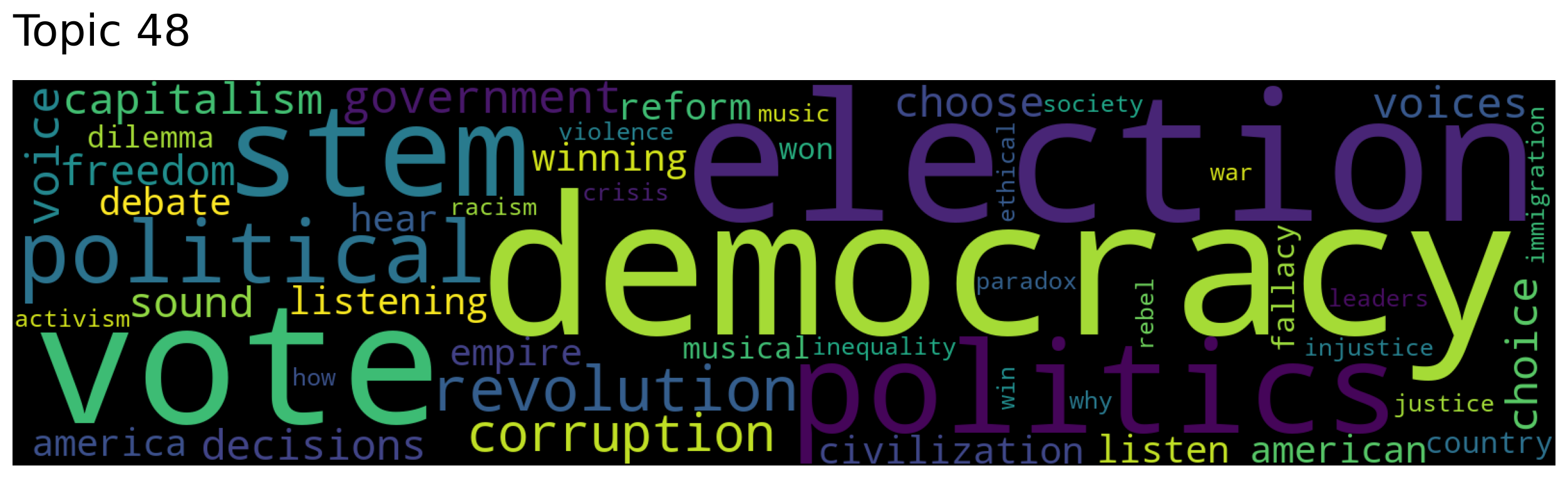
topic_words, word_scores, topic_scores, topic_nums = model.search_topics(keywords=["politics"],
num_topics=5)
for topic in topic_nums:
model.generate_topic_wordcloud(topic)



documents, document_scores, document_ids = model.search_documents_by_topic(topic_num=26, num_docs=5)
for doc, score, doc_id in zip(documents, document_scores, document_ids):
print(f"Document: {doc_id}, Score: {score}")
print("-----------")
print(doc)
print("-----------")
print()
Document: 1583, Score: 0.7956469655036926
-----------
Life that doesn't end with death
-----------
Document: 865, Score: 0.7733122110366821
-----------
Inspiring a life of immersion
-----------
Document: 2891, Score: 0.7583013772964478
-----------
A rite of passage for late life
-----------
Document: 477, Score: 0.7572578191757202
-----------
Life lessons through tinkering
-----------
Document: 7, Score: 0.7478621006011963
-----------
A life of purpose
-----------
documents, document_scores, document_ids = model.search_documents_by_keywords(keywords=["human", "love"], num_docs=5)
for doc, score, doc_id in zip(documents, document_scores, document_ids):
print(f"Document: {doc_id}, Score: {score}")
print("-----------")
print(doc)
print("-----------")
print()
Document: 264, Score: 0.6784869056838551
-----------
On humanity
-----------
Document: 5309, Score: 0.588455842303502
-----------
"Being Human"
-----------
Document: 258, Score: 0.5522820827921512
-----------
The brain in love
-----------
Document: 584, Score: 0.5464831966261261
-----------
The uniqueness of humans
-----------
Document: 4532, Score: 0.5446537580036017
-----------
The language of being human
-----------
topic_words, topic_vectors, topic_labels = model.get_topics()
topic_words
array([['why', 'reasons', 'reason', ..., 'don', 'matters', 'strangers'],
['how', 'ways', 'como', ..., 'ethical', 'paradox', 'emotional'],
['compassion', 'empathy', 'consciousness', ..., 'psychology',
'perspective', 'minds'],
...,
['why', 'read', 'reading', ..., 'tale', 'pandemics', 'quantum'],
['smartphone', 'phone', 'mobile', ..., 'watch', 'magic', 'your'],
['cars', 'driving', 'car', ..., 'surveillance', 'walk',
'themselves']], dtype='<U14')
Another recent tool to know is BERTopic, which leverages transformers.
Final comments and summary#
Important ideas to know#
Topic modeling is a tool to uncover important themes in a large collection of documents.
The overall goal is to tell a high-level story about a large collection of documents to humans.
(Credit: Health topics in social media)
Latent dirichlet allocation (LDA) is a commonly used model for topic modeling, which is a Bayesian, probabilistic, and generative model.
Topic is something that influences the choice of vocabulary of a document. For each document, we assume that several topics are active with varying importance.
The primary idea of the model is
A document is a mixture of topics
A topic is a mixture of words in the vocabulary
You can carry out topic modeling with LDA in Python using the
Gensimlibrary.Preprocessing is extremely important in topic modeling.
Some of the most common steps in preprocessing for topic modeling include
Sentence segmentation, tokenization, lemmatization, stopword and punctuation removal
You can visualize topic model using
pyLDAvis.There are more advanced and practical tools for topic modeling out there. Some examples include
Top2VecandBERTopic
Some useful resources and links#
If you want to learn more about practical aspects of LDA