Probability Cheatsheet#
Complement of an Event#
In general, for a given event \(A\), the complement is the subset of other outcomes that do not belong to event \(A\):
where \(^c\) means the complement (we read it as “not”).
Conditional Independence#
Random variables \(X\) and \(Y\) are conditionally independent given random variable \(Z\) if and only if
Conditional Probability#
In general, let \(A\) and \(B\) be two events of interest within the sample \(S\), and \(P(B) > 0\), then the *conditional probability of \(A\) given \(B\) is defined as:
Note event \(B\) is becoming the new sample space (i.e., \(P(B \mid B) = 1\)). The tweak here is that our original sample space \(S\) has been updated to \(B\).
Covariance#
Let \(X\) and \(Y\) be two numeric random variables; their covariance is defined as follows:
where \(\mu_X = \mathbb{E}(X)\) and \(\mu_Y = \mathbb{E}(Y)\) are the respective means (or expected values) of \(X\) and \(Y\). After some algebraic and expected value manipulations, the above equation reduces to a more practical form to work with:
where \(\mathbb{E}(XY)\) is the mean (or expected value) of the multiplication of the random variables \(X\) and \(Y\).
Cumulative Distribution Function#
Let \(X\) be a continuous random variable with probability density function (PDF) \(f_X(x)\). The cumulative distribution function (CDF) is usually denoted by \(F(\cdot)\) and is defined as
We can calculate the CDF by
In order for \(F_X(x)\) to be a valid CDF, the function needs to satisfy the following requirements:
Must never decrease.
It must never evalute to be \(< 0\) or \(> 1\).
\(F_X(x) \rightarrow 0\) as \(x \rightarrow -\infty\)
\(F_X(x) \rightarrow 1\) as \(x \rightarrow \infty\).
Entropy#
Let \(X\) be a random variable:
If \(X\) is discrete, with \(P(X = x)\) as a probability mass function (PMF), then the entropy is defined as:
If \(X\) is continuous, with \(f_X(x)\) as a probability density function (PDF), then the entropy is defined as:
Note that, in Statistics, the \(\log(\cdot)\) notation implicates base \(e\).
Expected Value#
Let \(X\) be a numeric random variable. The mean \(\mathbb{E}(X)\) (also known as expected value or expectation) is defined as:
If \(X\) is discrete, with \(P(X = x)\) as a probability mass function (PMF), then
If \(X\) is continuous, with \(f_X(x)\) as a probability density function (PDF), then
In general for a function of \(X\) such as \(g(X)\), the expected value is defined as:
If \(X\) is discrete, with \(P(X = x)\) as a PMF, then
If \(X\) is continuous, with \(f_X(x)\) as a PDF, then
Inclusion-Exclusion Principle#
Two Events#
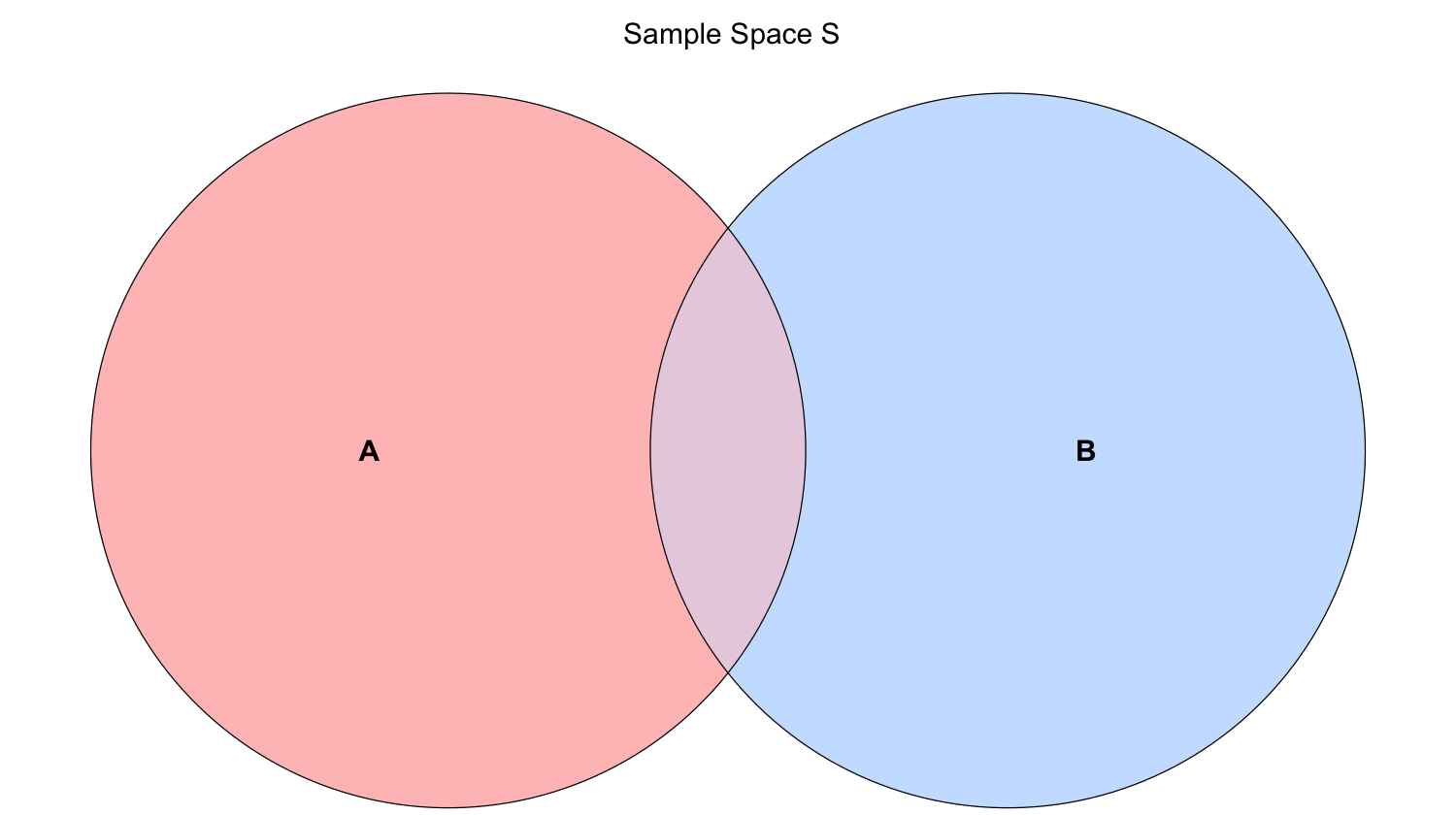
Let \(A\) and \(B\) be two events of interest in the sample space \(S\). The probability of \(A\) or \(B\) occuring is denoted as \(P(A \cup B)\), where \(\cup\) means “OR.” The Inclusion-Exclusion Principle allows us to compute this probability as:
where \(P(A \cap B)\) denotes the probability of \(A\) and \(B\) occuring simultaneously (\(\cap\) means “AND”).
\(P(A \cup B)\) can be represented with the overall shaded area in the below Venn diagram.
Three Events#
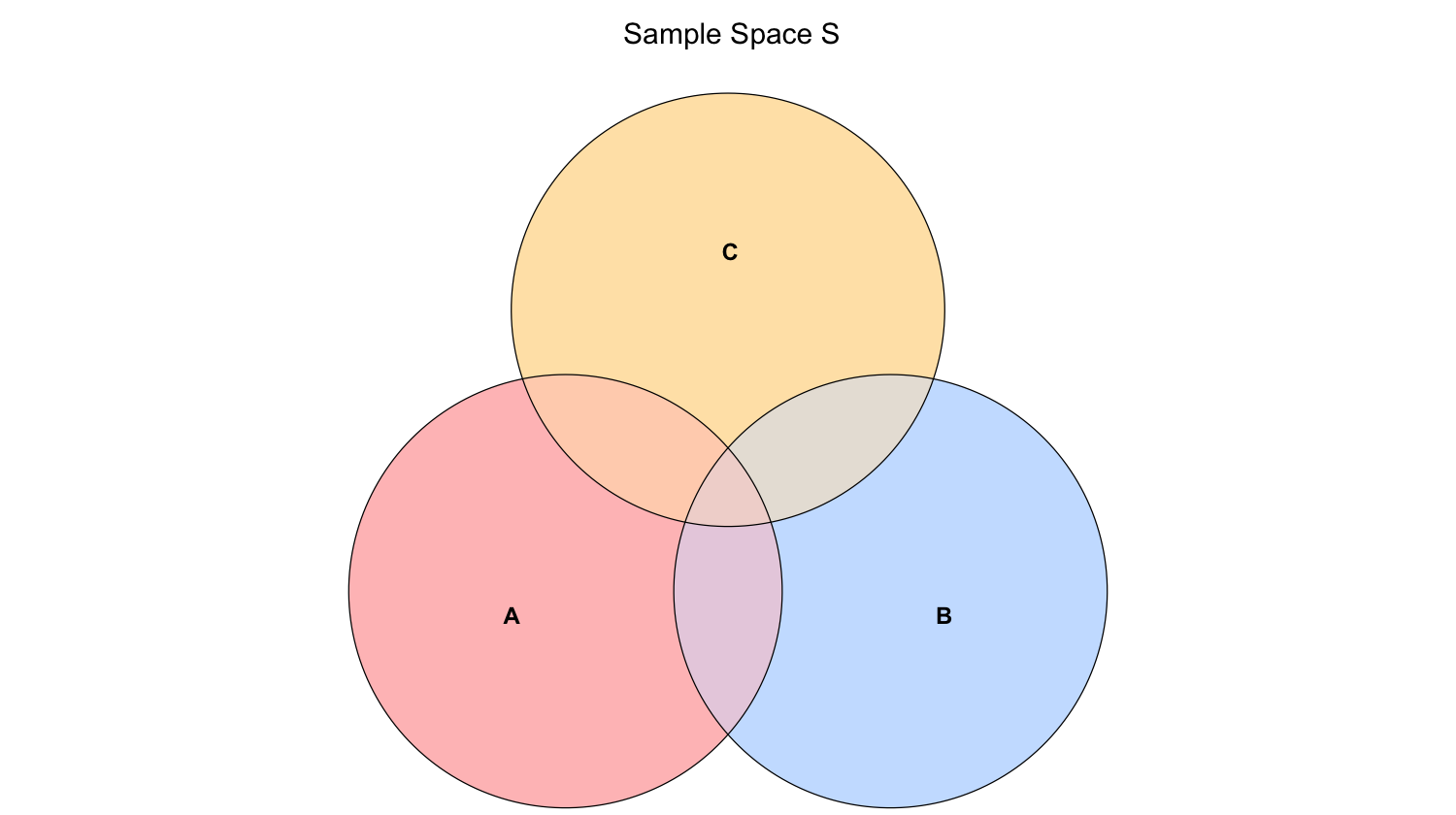
We can also extend this principle to three events (\(A,\) \(B\), and \(C\) in the sample space \(S\)):
where \(P(A \cap B \cap C)\) denotes the probability of \(A\), \(B\), and \(C\) occuring simultaneously.
\(P(A \cup B \cup C)\) can be represented with the overall shaded area in the below Venn diagram.
Independent Events#
Let \(A\) and \(B\) be two events of interest in the sample space \(S\). These two events are independent if the occurrence of one of them does not affect the probability of the other. In probability notation, their intersection is defined as:
Independence in Probability Distributions between Two Random Variables#
Let \(X\) and \(Y\) be two independent random variables. Using their corresponding marginals, we can obtain their corresponding joint distributions as follows:
\(X\) and \(Y\) are discrete. Let \(P(X = x, Y = y)\) be the joint probability mass function (PMF) with \(P(X = x)\) and \(P(Y = y)\) as their marginals. Then, we define the joint PMF as:
The term denoting a discrete joint PMF \(P(X = x, Y = y)\) is equivalent to the intersection of events \(P(X = x \cap Y = y)\).
\(X\) and \(Y\) are continuous. Let \(f_{X,Y}(x,y)\) be the joint probability density function (PDF) with \(f_X(x)\) and \(f_Y(y)\) as their marginals. Then, we define the joint PDF as:
Independent Random Variables#
Let \(X\) and \(Y\) be two random variables. We say \(X\) and \(Y\) are independent if knowing something about one of them tells us nothing about the other. A definition of \(X\) and \(Y\) being independent is the following:
Kendall’s \(\tau_K\)#
Let \(X\) and \(Y\) be two numeric random variables. Kendall’s \(\tau_K\) measures concordance between each pair of observations \((x_i, y_i)\) and \((x_j, y_j)\) with \(i \neq j\):
Concordant, which gets a positive sign, means
Discordant, which gets a negative sign, means
Mathematically, we can set it up as:
with the “true” Kendall’s \(\tau_K\) value obtained by sending \(n \rightarrow \infty\). Here, \(n\) is the sample size (i.e., the number of data points). Note that:
Law of Total Expectation#
Let \(X\) and \(Y\) be two numeric random variables. Generally, a marginal mean \(\mathbb{E}_Y(Y)\) can be computed from the conditional means \(\mathbb{E}_Y(Y \mid X = x)\) and the probabilities of the conditioning variables \(P(X = x)\):
Or, it can also be written as:
Also, the previous result in Equation (7) extends to probabilities:
Linearity of Expectations#
If \(a\) and \(b\) are constants, with \(X\) and \(Y\) as numeric random variables, then we can obtain the expected value of the following expressions as:
Linearity of Variances with Two Independent Random Variables#
If \(a\) and \(b\) are constants, with \(X\) and \(Y\) as independent numeric random variables, then we can obtain the variance of the following expressions as:
Marginal (Unconditional) Probability#
In general, the probability of an event \(A\) occurring is denoted as \(P(A)\) and is defined as
Median#
Let \(X\) be a numeric random variable. The median \(\text{M}(X)\) is the outcome for which there is a 50-50 chance of seeing a greater or lesser value. So, its distribution-based definition satisfies
Mode#
Let \(X\) be a random variable:
If \(X\) is discrete, with \(P(X = x)\) as a probability mass function (PMF), then the mode is the outcome having the highest probability.
If \(X\) is continuous, with \(f_X(x)\) as a probability density function (PDF), then the mode is the outcome having the highest density. That is:
Mutual Information#
The mutual information between two random variables \(X\) and \(Y\) is defined as
Mutually Exclusive (or Disjoint) Events#
Let \(A\) and \(B\) be two events of interest in the sample space \(S\). These events are mutually exclusive (or disjoint) if they cannot happen at the same time in the sample space \(S\). Thus, in probability notation, their intersection will be:
Therefore, by the Inclusion-Exclusion Principle, the union of these two events can be obtained as follows:
These two events are shown in the below Venn diagram.

Odds#
Let \(p\) be the probability of an event of interest \(A\). The odds \(o\) is the ratio of the probability of the event \(A\) to the probability of the non-event \(A\):
In plain words, the odds will tell how many times event \(A\) is more likely compared to how unlikely it is.
Pearson’s Correlation#
Let \(X\) and \(Y\) be two numeric random variables, whose respective variances are defined by Equation (9), with a covariance defined as in Equation (1). Pearson’s correlation standardizes the distances according to the standard deviations \(\sigma_X\) and \(\sigma_Y\) of \(X\) and \(Y\), respectively. It is defined as:
As a result of the above equation, it turns out that
Probability of a Continuous Random Varible \(X\) Being between \(a\) and \(b\)#
For a continuous random variable \(X\) with probability density function (PDF) \(f_X(x)\), the probability of \(X\) being between \(a\) and \(b\) is
We can connect the dots with our new definition of a cumulative distribution function (CDF) from Equation (2). First,
because if \(X \leq b \) but not \(\leq a\) then it must be that \(a \leq X \leq b\). But now we can write these two terms using the CDF:
Now, plugging in the definition of the CDF as the integral of the PDF,
Properties of the Bivariate Gaussian or Normal Distribution#
Let \(X\) and \(Y\) be part of a bivariate Gaussian or Normal distribution with means \(-\infty < \mu_X < \infty\) and \(-\infty < \mu_Y < \infty\), variances \(\sigma^2_X > 0\) and \(\sigma^2_Y > 0\), and correlation coefficient \(-1 \leq \rho_{XY} \leq 1\).
This bivariate Gaussian or Normal distribution has the following properties:
Marginal distributions are Gaussian. The marginal distribution of a subset of variables can be obtained by just taking the relevant subset of means, and the relevant subset of the covariance matrix.
Linear combinations are Gaussian. This is actually by definition. If \((X, Y)\) have a bivariate Gaussian or Normal distribution with marginal means \(\mu_X\) and \(\mu_Y\) along with marginal variances \(\sigma^2_X\) and \(\sigma^2_Y\) and covariance \(\sigma_{XY}\); then \(Z = aX + bY + c\) with constants \(a, b, c\) is Gaussian. If we want to find the mean and variance of \(Z\), we apply the linearity of expectations and variance rules:
Conditional distributions are Gaussian. If \((X, Y)\) have a bivariate Gaussian or Normal distribution with marginal means \(\mu_X\) and \(\mu_Y\) along with marginal variances \(\sigma^2_X\) and \(\sigma^2_Y\) and covariance \(\sigma_{XY}\); then the distribution of \(Y\) given that \(X = x\) is also Gaussian. Its distribution is
Quantile#
Let \(X\) be a numeric random variable. A \(p\)-quantile \(Q(p)\) is the outcome with a probability \(p\) of getting a smaller outcome. So, its distribution-based definition satisfies
Quantile Function#
Let \(X\) be a continuous random variable. The quantile function \(Q(\cdot)\) takes a probability \(p\) and maps it to the \(p\)-quantile. It turns out that this is the inverse of the cumulative distribution function (CDF) (2):
Note that this function does not exist outside of \(0 \leq p \leq 1\). This is unlike the other functions (density, CDF, and survival function) which exist on all real numbers.
Skewness#
Let \(X\) be a numeric random variable:
If \(X\) is discrete, with \(P(X = x)\) as a probability mass function (PMF), then skewness can be defined as
If \(X\) is continuous, with \(f_X(x)\) as a probability density function (PDF), then
where \(\mu_X = \mathbb{E}(X)\) as in Equations (3) if \(X\) is discrete and (4) if \(X\) is continuous. On the other hand, \(\sigma_X = \text{SD}(X)\) as in Equation (10).
Survival Function#
Let \(X\) be a continuous random variable. The survival function \(S(\cdot)\) is the cumulative distribution function (CDF) (2) “flipped upside down”. For this random variable \(X\), the survival function is defined as
Variance#
Let \(X\) be a numeric random variable. The variance, either for a discrete or continuous random variable, is defined as
For the continuous case with \(f_X(x)\) as a probability density function (PDF), an alternative definition of the variance is
The term \(\mu_X\) is equal to \(\mathbb{E}(X)\) from Equation (4).
Finally, either for a discrete or continuous random variable, the standard deviation is the square root of the variance:
The above measure is more practical because it is on the same scale as the outcome, unlike the variance.
Variance of a Sum Involving Two Non-Independent Random Variables#
Suppose \(X\) and \(Y\) are not independent numeric random variables. Therefore, the variance of their sum is:
Furthermore, if \(X\) and \(Y\) are independent, then
Therefore, using Equation (12), the sum (11) becomes: