Distribution Cheatsheet#
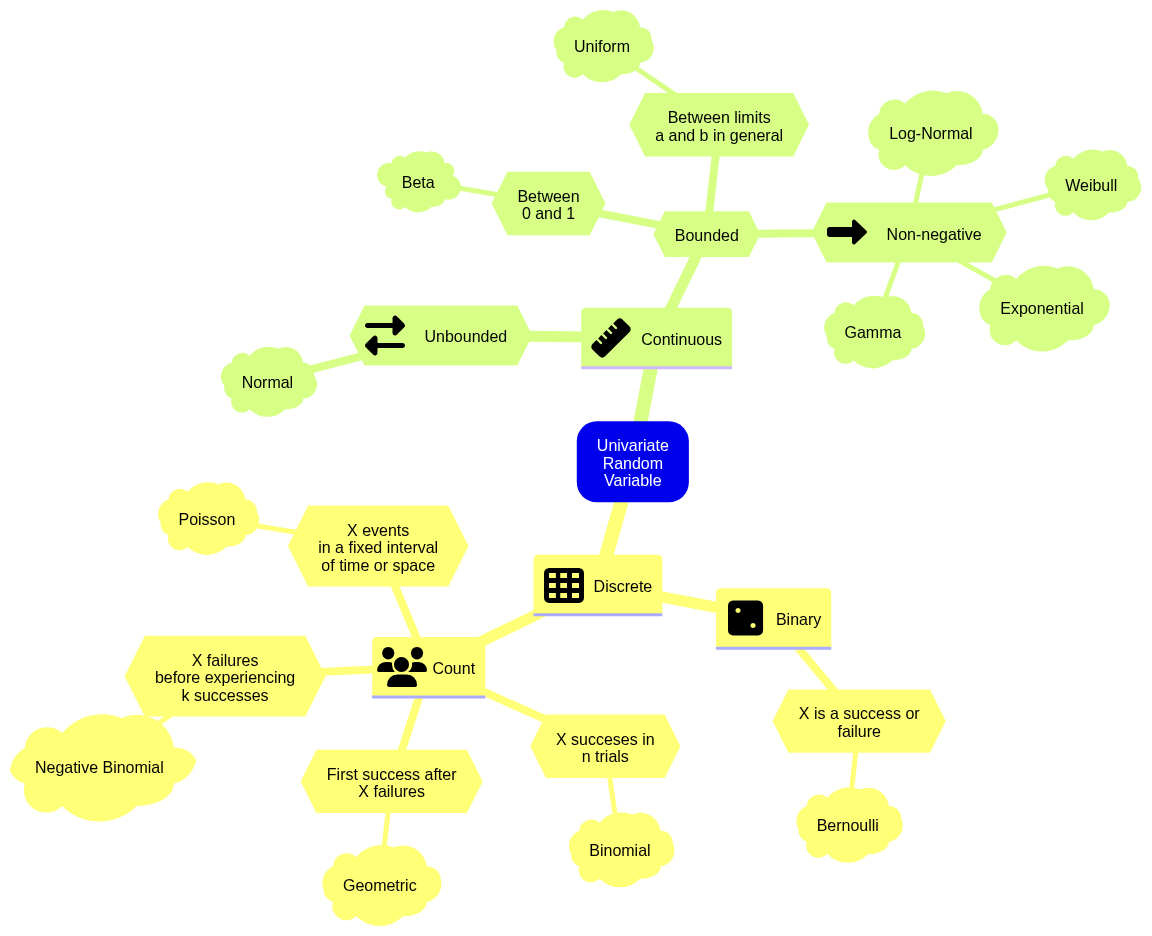
Discrete Distributions#
Bernoulli#
Process#
It is a random variable \(X\) that is binary as follows
The value \(1\) has a probability of \(0 \leq p \leq 1\), whereas the value \(0\) has a probability of \(1 - p\).
Then, \(X\) is said to have a Bernoulli distribution:
PMF#
A Bernoulli distribution is characterized by the PMF
Mean#
The mean of a Bernoulli random variable is defined as:
Variance#
The variance of a Bernoulli random variable is defined as:
Binomial Distribution#
Process#
Let \(X\) be the number of succcesses after \(n\) independent Bernoulli trials with probability of success \(0 \leq p \leq 1\).
Then, \(X\) is said to have a Binomial distribution:
Probability Mass Function (PMF)#
A Binomial distribution is characterized by the PMF
Term \({n \choose x}\) indicates the total number of combinations for \(x\) successes out of \(n\) trials:
Mean#
The mean of a Binomial random variable is defined as:
Variance#
The variance of a Binomial random variable is defined as:
Geometric Distribution#
Process#
Let \(X\) be the number of failed independent Bernoulli trials before experiencing the first success.
Then, \(X\) is said to have a Geometric distribution:
PMF#
A Geometric distribution is characterized by the PMF
Mean#
The mean of a Geometric random variable is defined as:
Variance#
The variance of a Geometric random variable is defined as:
Negative Binomial Distribution (a.k.a. Pascal)#
Process#
Let \(X\) be the number of failed independent Bernoulli trials before experiencing \(k\) independent successes.
Then, \(X\) is said to have a Negative Binomial distribution:
PMF#
A Negative Binomial distribution is characterized by the PMF
Mean#
The mean of a Negative Binomial random variable is defined as:
Variance#
The variance of a Negative Binomial random variable is defined as:
Poisson#
Process#
Let \(X\) be the number of events happening in a fixed interval of time or space at some average rate \(\lambda\).
Then, \(X\) is said to have a Poisson distribution:
PMF#
A Poisson distribution is characterized by the PMF
Mean#
The mean of a Poisson random variable is defined as:
Variance#
The variance of a Poisson random variable is defined as:
R Functions#
The Poisson distribution has some handy R functions to perform different probabilistic computations. Let us check them via some quick example.
Suppose that we have the following random variable:
Note we have a count-type random variable denoting the number of events (i.e., orders) happening in a fixed interval of time (i.e., the weekend). Let us assume that, in average during the weekend, we receive 15 orders. We can model \(X\) as a Poisson random variable:
ppois()#
Given the above random variable modelling, let us answer the following:
What is the probability of getting more than 10 orders during the weekend, i.e., \(P(X > 10)\)?
What is the probability of getting between 12 and 16 orders during the weekend, i.e., \(P(12 \leq X \leq 16)\)?
We can manually compute these probabilities via Equation (38). Nevertheless, let us try a quicker way via ppois(). This function allows us to compute probabilities as follows:
We must indicate an argument
qfor the quantile corresponding to \(P(X \leq \texttt{q})\).Argument
lambdacorresponds to \(\lambda\).
answer_ppois_1 <- 1 - ppois(q = 10, lambda = 15, lower.tail = TRUE) # lower.tail = TRUE indicates P(X <= q)
answer_ppois_1 <- round(answer_ppois_1, 3) # Rounding to three decimal places
answer_ppois_1
The above code corresponds to:
Now, for the second question:
answer_ppois_2 <- ppois(q = 16, lambda = 15, lower.tail = TRUE) -
ppois(q = 12, lambda = 15, lower.tail = TRUE)
answer_ppois_2 <- round(answer_ppois_2, 3)
answer_ppois_2
The above code corresponds to:
qpois()#
It is also possible to obtain the \(p\)-quantile \(Q(p)\) associated with the probability \(P\left[X \leq Q(p) \right]\). Suppose we want to obtain the \(0.6\)-quantile, i.e. \(Q(0.6)\), for this specific example. Function qpois() allows us to compute this quantile as follows:
We must indicate an argument
pfor the corresponding probability \(p\).Argument
lambdacorresponds to \(\lambda\).
answer_qpois <- qpois(p = 0.6, lambda = 15)
answer_qpois <- answer_qpois
answer_qpois
The above code corresponds to:
Uniform (Discrete)#
Process#
Let \(X\) be the random discrete outcome of a finite set of \(N\) outcomes. Suppose each outcome has a numeric label whose lower and upper bounds are \(a\) and \(b\), respectively. Then, \(X\) is said to have a discrete Uniform distribution:
PMF#
A discrete Uniform distribution is characterized by the PMF
Mean#
The mean of a discrete Uniform random variable is defined as:
Variance#
The variance of a discrete Uniform random variable is defined as:
Continuous Distributions#
Beta#
Process#
The Beta family of distributions is defined for random variables taking values between \(0\) and \(1\), so is useful for modelling the distribution of proportions. This family is quite flexible, and has the Uniform distribution as a special case. It is characterized by two positive shape parameters, \(\alpha > 0\) and \(\beta > 0\).
The Beta family is denoted as
PDF#
The density is parameterized as
where \(\Gamma(\cdot)\) is the Gamma function.
Here are some examples of densities:
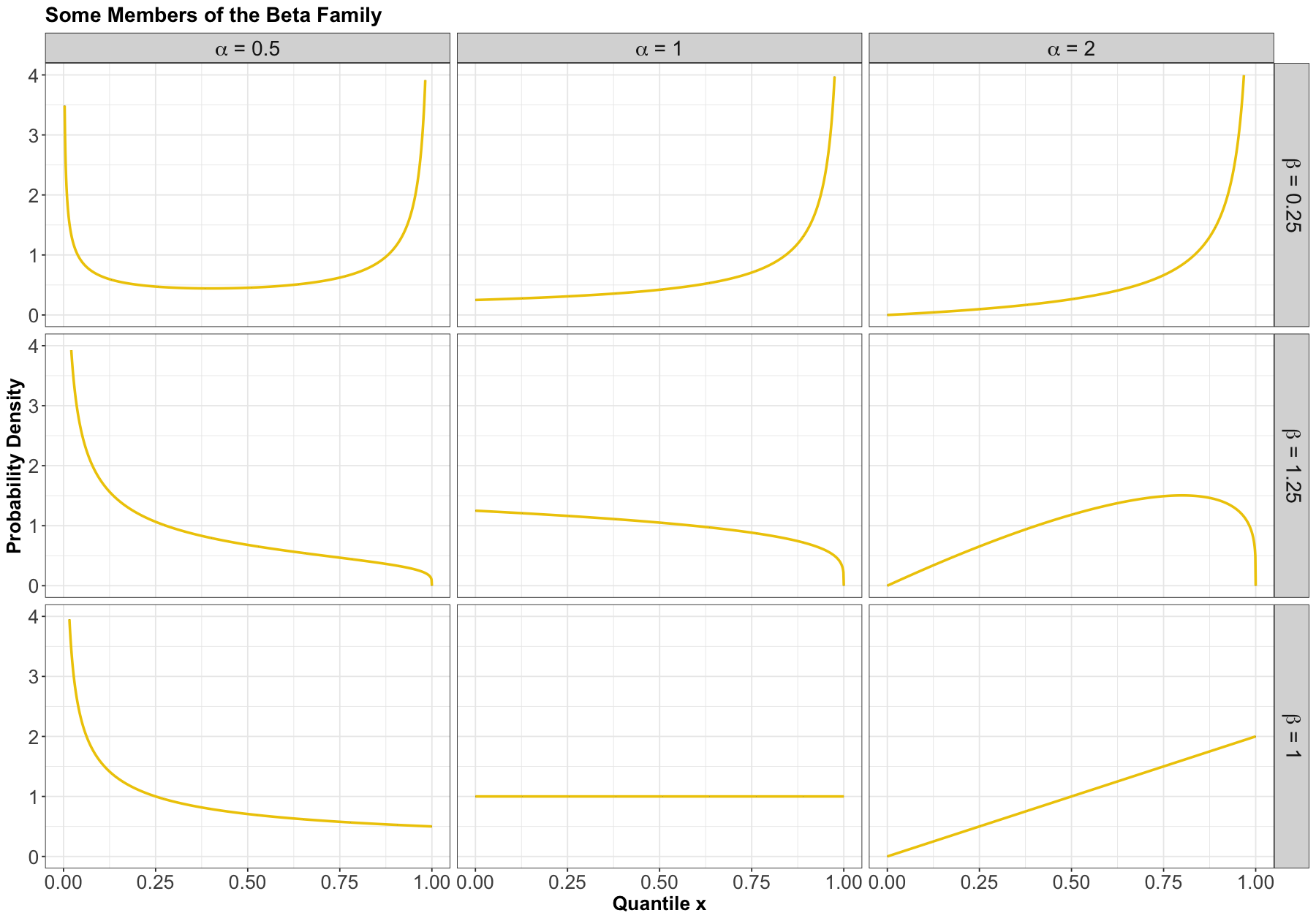
Mean#
The mean of a Beta random variable is defined as:
Variance#
The variance of a Beta random variable is defined as:
Bivariate Gaussian or Normal#
Process#
Members of this family need to have all Gaussian marginals, and their dependence has to be Gaussian dependence. Gaussian dependence is obtained as a consequence of requiring that any linear combination of Gaussian random variables is also Gaussian.
Parameters#
To characterize the bivariate Gaussian family (i.e., \(d = 2\) involved random variables), we need the following parameters:
Mean for both \(X\) and \(Y\) denoted as \(-\infty < \mu_X < \infty\) and \(-\infty < \mu_Y < \infty\), respectively.
Variance for both \(X\) and \(Y\) denoted as \(\sigma^2_X > 0\) and \(\sigma^2_Y > 0\), respectively.
The covariance between \(X\) and \(Y\), sometimes denoted \(\sigma_{XY}\) or, equivalently, the Pearson correlation denoted \(-1 \leq \rho_{XY} \leq 1\).
That is five parameters altogether; and only one of them, Pearson correlation or covariance, is needed to specify the dependence part in a bivariate Gaussian family.
Then, we can construct two objects that are useful for computations: a mean vector \(\boldsymbol{\mu}\) and a covariance matrix \(\boldsymbol{\Sigma}\), where
and
Note that the covariance matrix (39) is always defined as above. Even if we are given the correlation \(\rho_{XY}\) instead of the covariance \(\sigma_{XY}\), we would then need to calculate the covariance as
before constructing the covariance matrix. However, there is another matrix that is sometimes useful, called the correlation matrix \(\mathbf{P}\). Firstly, let us recall the formula of the Pearson correlation between \(X\) and \(Y\):
It turns out that:
Thus, correlation matrix \(\mathbf{P}\) is defined as:
PDF#
The density can be parameterized as
Exponential#
Process#
The Exponential family is for positive random variables, often interpreted as wait time for some event to happen. Characterized by a memoryless property, where after waiting for a certain period of time, the remaining wait time has the same distribution.
The family is characterized by a single parameter, usually either the mean wait time \(\beta > 0\), or its reciprocal, the average rate \(\lambda > 0\) at which events happen.
The Exponential family is denoted as
or
PDF#
The density can be parameterized as
or
The densities from this family all decay starting at \(x = 0\) for rate \(\lambda\):
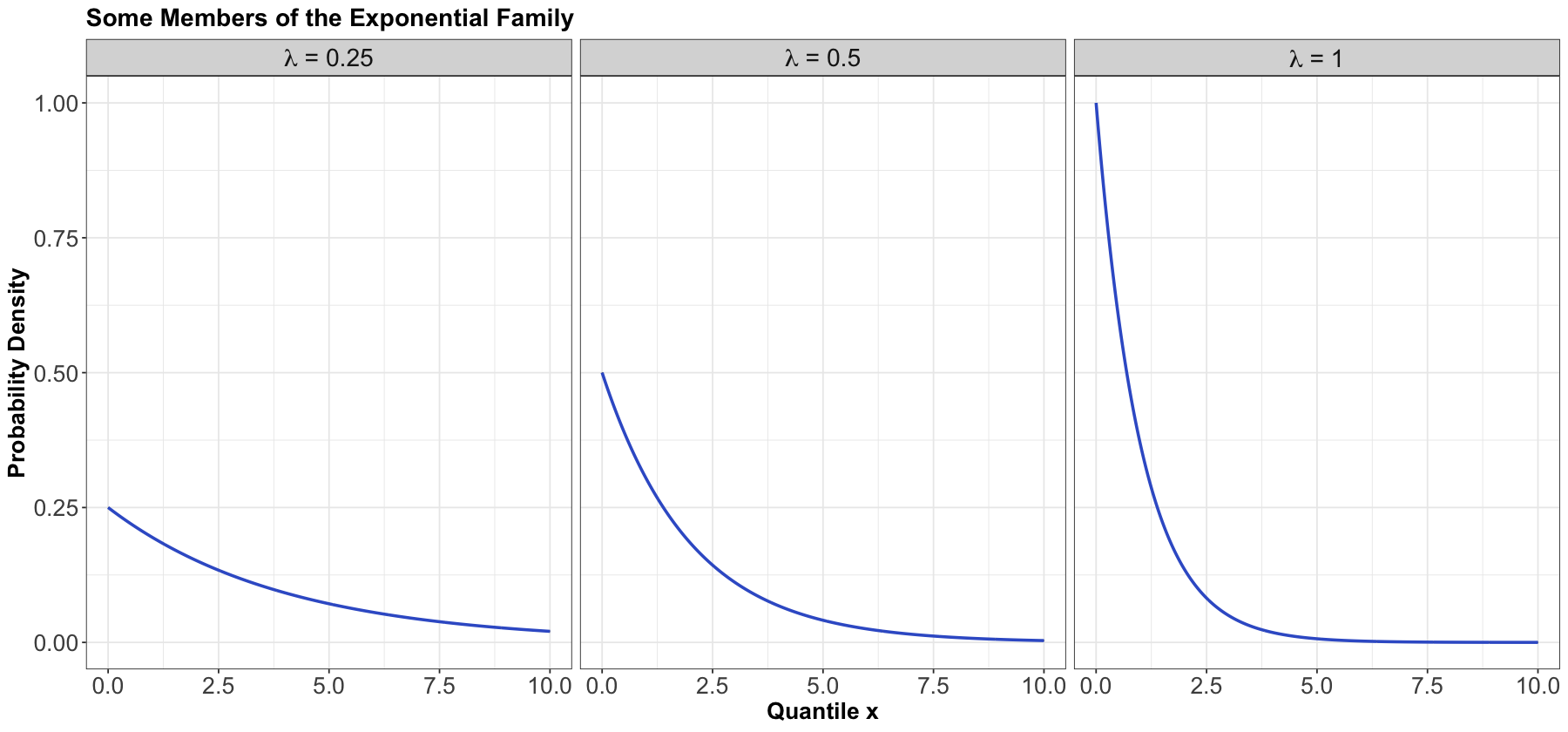
Mean#
Using a \(\beta\) parameterization, the mean of an Exponential random variable is defined as:
On the other hand, using a \(\lambda\) parameterization, the mean of an Exponential random variable is defined as:
Variance#
Using a \(\beta\) parameterization, the variance of an Exponential random variable is defined as:
On the other hand, using a \(\lambda\) parameterization, the variance of an Exponential random variable is defined as:
Gamma#
Process#
Another useful two-parameter family with support on non-negative numbers. One common parameterization is with a shape parameter \(k > 0\) and a scale parameter \(\theta > 0\).
The Gamma family can be denoted as
PDF#
The density is parameterized as
where \(\Gamma(\cdot)\) is the Gamma function.
Here are some densities:
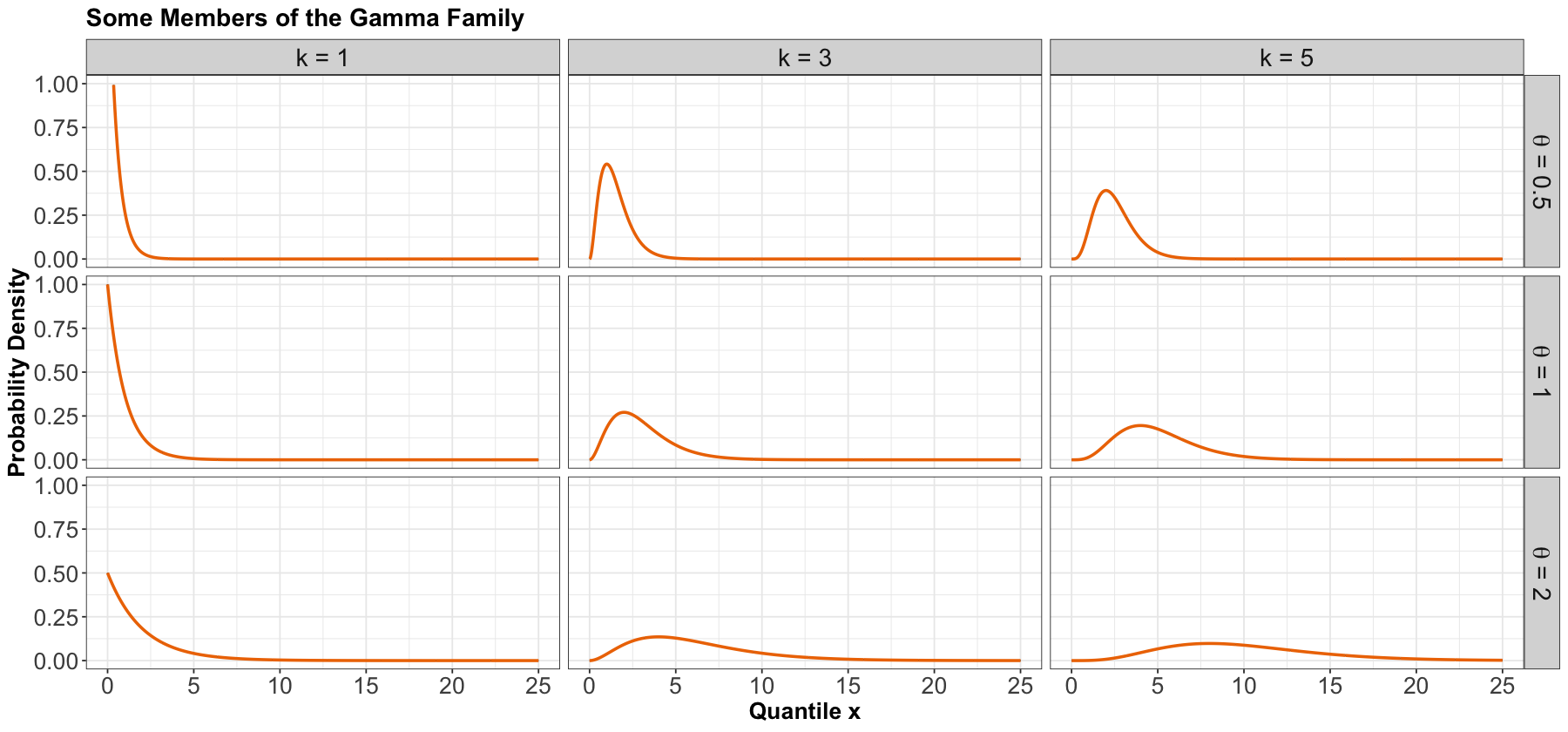
Mean#
The mean of a Gamma random variable is defined as:
Variance#
The variance of a Gamma random variable is defined as:
Gaussian or Normal#
Process#
Probably the most famous family of distributions. It has a density that follows a “bell-shaped” curve. It is parameterized by its mean \(-\infty < \mu < \infty\) and variance \(\sigma^2 > 0\). A Normal distribution is usually denoted as
PDF#
The density is
Here are some densities from members of this family:
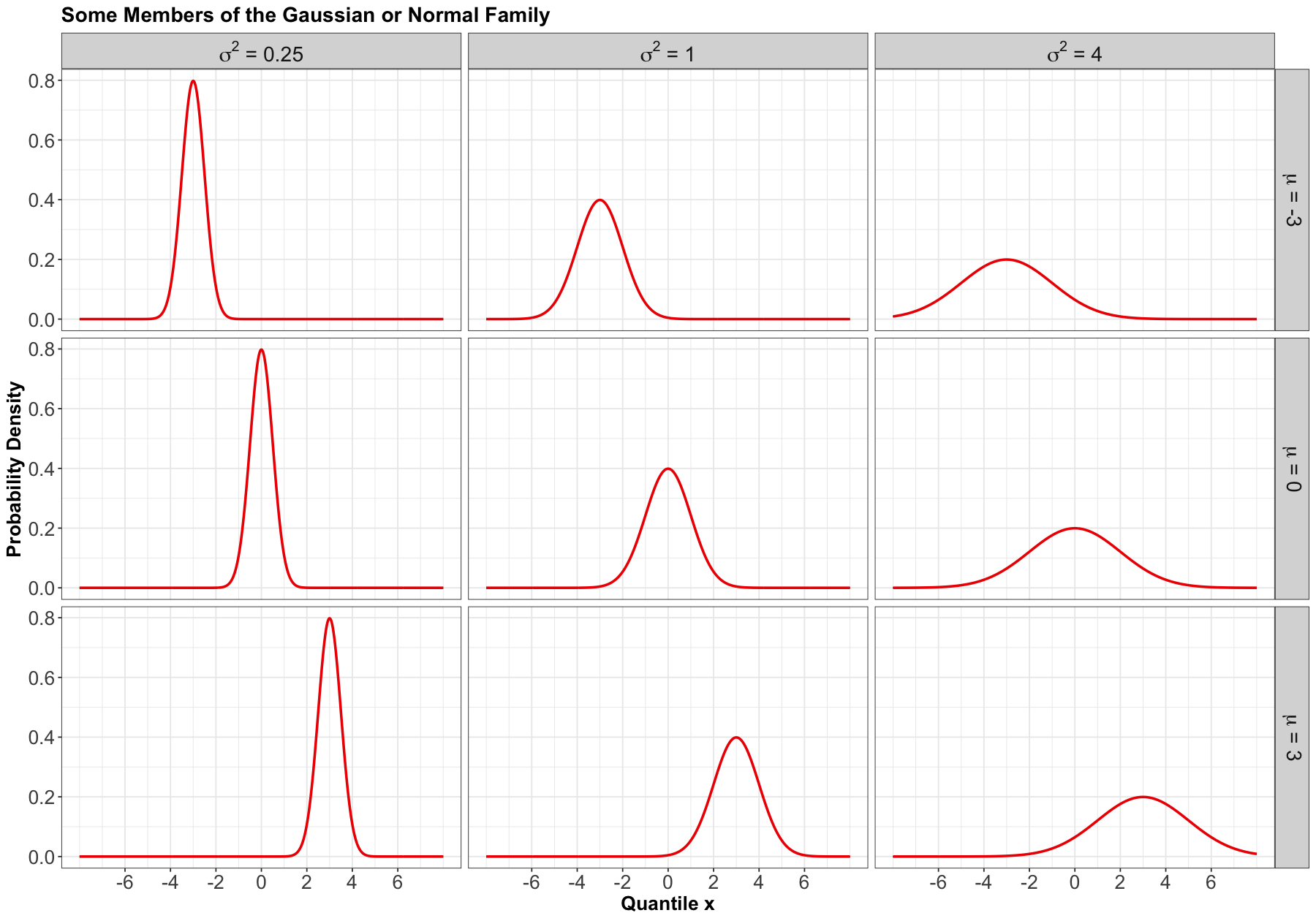
Mean#
The mean of a Normal random variable is defined as:
Variance#
The variance of a Normal random variable is defined as:
Log-Normal#
Process#
A random variable \(X\) is a Log-Normal distribution if the transformation \(\log(X)\) is Normal. This family is often parameterized by the mean \(-\infty < \mu < \infty\) and variance \(\sigma^2 > 0\) of \(\log X\). The Log-Normal family is denoted as
PDF#
The density is
Here are some densities from members of this family:
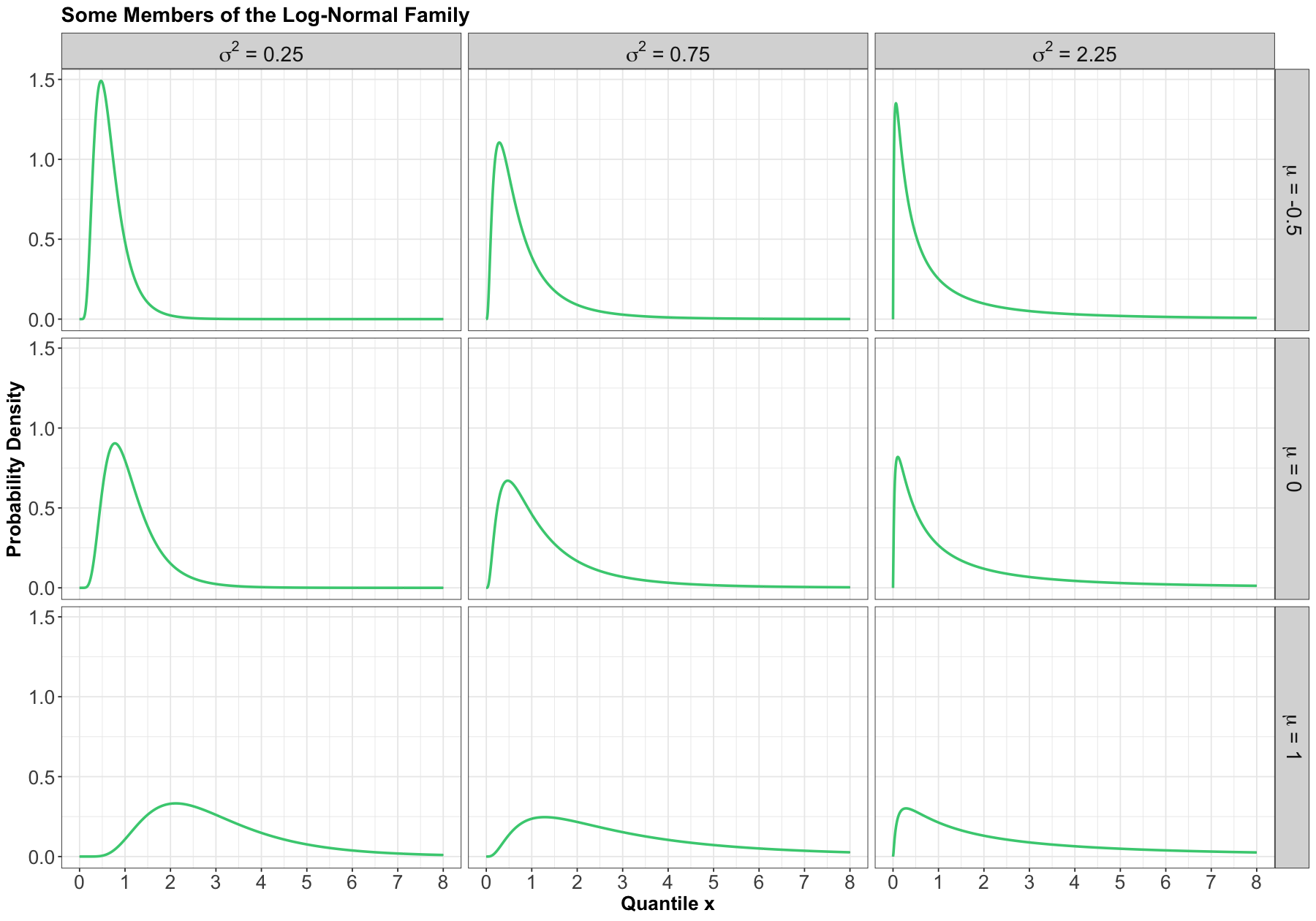
Mean#
The mean of a Log-Normal random variable is defined as:
Variance#
The variance of a Log-Normal random variable is defined as:
Uniform (Continuous)#
Process#
A continuous Uniform distribution has an equal density in between two points \(a\) and \(b\) (for \(a < b\)), and is usually denoted by
That means that there are two parameters: one for each end-point. A reference to a “Uniform distribution” usually implies continuous uniform, as opposed to discrete uniform.
PDF#
The density is
Here are some densities from members of this family:
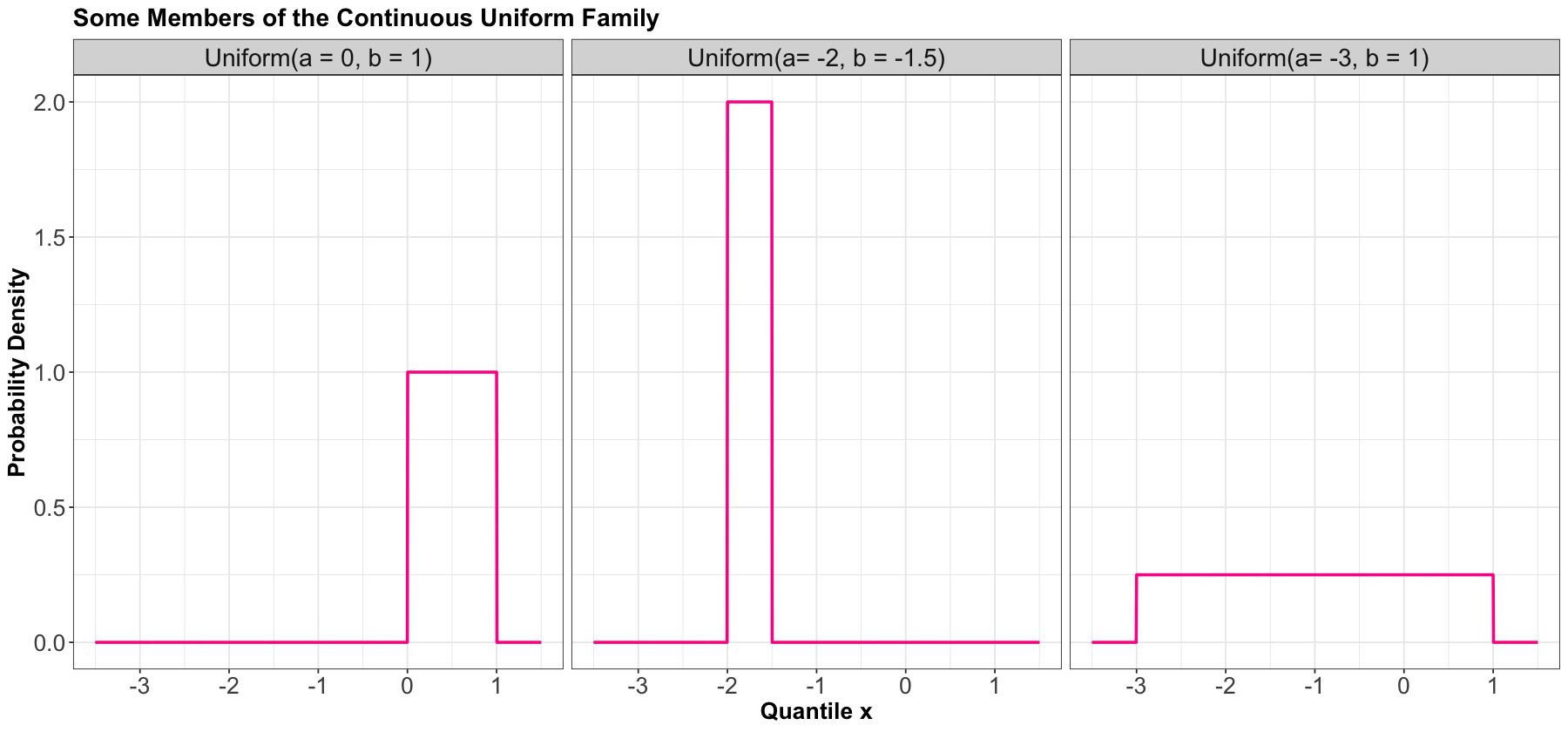
Mean#
The mean of a continuous Uniform random variable is defined as:
Variance#
The variance of a continuous Uniform random variable is defined as:
Weibull#
Process#
A generalization of the Exponential family, which allows for an event to be more likely the longer you wait. Because of this flexibility and interpretation, this family is used heavily in survival analysis when modelling time until an event.
This family is characterized by two parameters, a scale parameter \(\lambda > 0\) and a shape parameter \(k > 0\) (where \(k = 1\) results in the Exponential family).
The Weibull family is denoted as
PDF#
The density is parameterized as
Here are some examples of densities:
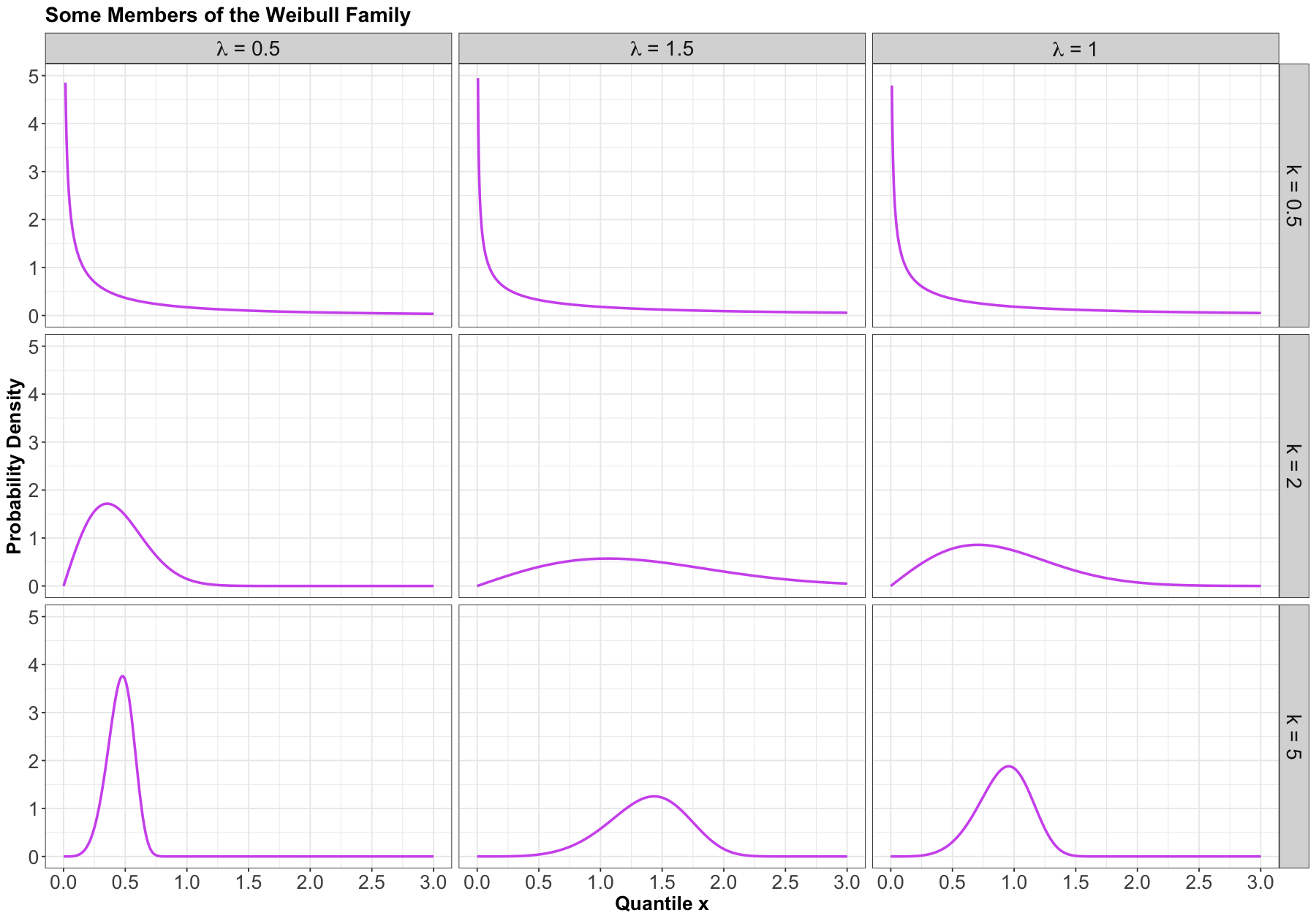
Mean#
The mean of a Weibull random variable is defined as:
Variance#
The variance of a Weibull random variable is defined as: