Lecture 2: Model Selection and Multinomial Logistic Regression
1 Slides
2 Today’s Learning Goals
By the end of this lecture, you should be able to:
- Perform likelihood-based model selection through analysis of deviance, Akaike Information Criterion, and Bayesian Information Criterion.
- Extend the link function concept of the generalized linear models (GLMs) to other discrete categorical responses.
- Outline the modelling framework of the Multinomial Logistic regression.
- Fit and interpret the Multinomial Logistic regression.
- Use the Multinomial Logistic regression for prediction.
3 Likelihood-based Model Selection
In DSCI 561, you learned about model selection in Ordinary Least-squares (OLS) via specific metrics such as the Mallow’s \(C_p\), Akaike information criterion (AIC), and Bayesian information criterion (BIC). These metrics are also helpful tools to perform model selection in GLMs. Additionally, it is essential to highlight that many GLMs are estimated via maximum likelihood.
Having said all this, you will learn today that metrics such as AIC and BIC are likelihood-based. Hence, the concept of maximum likelihood estimation (MLE) will come into play again for model selection in many GLMs. Firstly, let us explore model selection for Poisson regression via the dataset from lecture1.
3.1 The Crabs Dataset

The data frame crabs (Brockmann, 1996) is a dataset detailing the counts of satellite male crabs residing around a female crab nest. The code below renames the original response’s name, satell, to n_males.
The Crabs Dataset
This dataset contains \(n = 173\) observations on horseshoe crabs (Limulus polyphemus). The response is the count of male crabs (n_males) around a female breeding nest. It is subject to four explanatory variables related to the female crab: color of the prosoma with four levels (categorical factor-type), the condition of the posterior spine with three levels (categorical factor-type), the continuous variables carapace width (cm), and weight (g).
3.2 Estimation
To perform model selection, let us estimate two Poisson regression models with n_males as a response. Model 1 will only have the continuous carapace width (\(X_{\texttt{width}_i}\)) as a regressor, whereas Model 2 will have carapace width (\(X_{\texttt{width}_i}\)) and color of the prosoma (with dummy variables \(X_{\texttt{color\_darker}_i}\), \(X_{\texttt{color\_light}_i}\), and \(X_{\texttt{color\_medium}_i}\)).
\[ \begin{align*} \textbf{Model 1:} \quad & \log(\lambda_i) = \beta_0 + \beta_1 X_{\texttt{width}_i}. \\[0.5em] \textbf{Model 2:} \quad & \log(\lambda_i) = \beta_0 + \beta_1 X_{\texttt{width}_i} + \beta_2 X_{\texttt{color\_darker}_i} \\ & \qquad\qquad\;\; + \beta_3 X_{\texttt{color\_light}_i} + \beta_4 X_{\texttt{color\_medium}_i}. \end{align*} \]
Then, via glm() and crabs, we obtain our regression estimates.
Since we are digging into model selection, let us keep in mind the below main statistical inquiry.
Main Statistical Inquiry
We want to determine which Poisson regression model fits the data better: Model 1 or Model 2.
3.3 Goodness of Fit Test
The deviance (\(D_k\)) criterion can be used to compare a given model with \(k\) regressors with that of a baseline model.
Definition of a saturated or full model in Poisson regression
The usual baseline model is the saturated or full model, which perfectly fits the data because it allows a distinct Poisson mean \(\lambda_i\) for the \(i\)th observation in the training dataset (\(i = 1, \dots, n\)), unrelated to the \(k\) regressors.
The maximized likelihood of this full model is denoted as \(\hat{\mathscr{l}}_f\). Now, let \(\hat{\mathscr{l}}_k\) be the value of the maximized likelihood computed from our dataset of \(n\) observations with \(k\) regressors.
We can compare the fits provided by these two models by the deviance \(D_k\) given by
\[ D_k = -2 \log \left( \frac{\hat{\mathscr{l}}_k}{\hat{\mathscr{l}}_f} \right) = -2 \left[ \log \left( \hat{\mathscr{l}}_k \right) - \log \left( \hat{\mathscr{l}}_f \right) \right]. \tag{1}\]
Note that \(D_k\) expresses how much our given model deviates from the full model on log-likelihood scale. This metric is interpreted as follows:
- Large values of \(D_k\) arise when \(\hat{\mathscr{l}}_k\) is small relative to \(\hat{\mathscr{l}}_f\), indicating that our given model fits the data poorly compared to the baseline model.
- Small values of \(D_k\) arise when \(\hat{\mathscr{l}}_k\) is similar to \(\hat{\mathscr{l}}_f\), indicating that our given model provides a good fit to the data compared to the baseline model.
Specifically for Poisson regression with \(k\) regressors, it can be shown that \(D_k\) from Equation 1 is defined as follows:
\[ \begin{gather} \hat{\lambda}_i = \exp{\left( \hat{\beta_0} + \hat{\beta}_1 x_{i,1} + \dots + \hat{\beta}_k x_{i,k} \right)} \\ D_k = 2 \sum_{i = 1}^n \left[ y_i \log \left( \frac{y_i}{\hat{\lambda}_i} \right) - \left( y_i - \hat{\lambda}_i \right) \right] \end{gather} \tag{2}\]
where \(y_i\) is the \(i\)th observed response in the training set of size \(n\). Note that when \(y_i = 0\) counts, then \(\log \left( \frac{y_i}{\hat{\lambda}_i} \right)\) is assumed as \(0\).
Definition of goodness of fit
Equation 2 depicts the agreement of our model with \(k\) regressors to the observed data. Hence, we can use Equation 2 to test the goodness of fit; i.e., whether our fitted model fits the data better than the saturated model, which makes it correctly specified (with a level of significance \(\alpha\)!).
The hypotheses are the following:
\[ \begin{gather*} H_0: \text{Our}\textbf{ Model with $k$ regressors} \text{ fits the data better than the } \textbf{Saturated Model} \\ H_a: \text{otherwise.} \end{gather*} \]
Let us test our poisson_model_2:
\[ \begin{align*} h(\lambda_i) &= \log(\lambda_i) \\ & = \beta_0 + \beta_1 X_{\texttt{width}_i} + \beta_2 X_{\texttt{color\_darker}_i} \\ & \qquad + \beta_3 X_{\texttt{color\_light}_i} + \beta_4 X_{\texttt{color\_medium}_i}. \end{align*} \]
We cannot use anova() to perform this hypothesis testing. We will have to do it manually via glance().
Column deviance provides \(D_k\) and is formally called residual deviance, which is the test statistic. Asymptotically, we have the following null distribution:
\[ D_k \sim \chi^2_{n - (k + 1)}. \]
The degrees of freedom (column df.residual in our glance() output) are the difference between the training set size \(n\) and the number of regression parameters in our model (including the intercept \(\beta_0\)).
Let us obtain the corresponding \(p\text{-value}\) for this test. We can do it using pchisq():
We obtain a \(p\text{-value} < .001\), which gives statistical evidence to state that our poisson_model_2 is not correctly specified when compared to the saturated model.
A Note on the Null Deviance
The above glance() output contains a metric call null.deviance. This metric comes from a Poisson regression model which is only estimated with an intercept, i.e., \(\hat{\beta}_{0}\); let us call it \(D_0\):
\[ \begin{gather} \hat{\lambda}_i = \exp{\left( \hat{\beta_0} \right)} \\ D_0 = 2 \sum_{i = 1}^n \left[ y_i \log \left( \frac{y_i}{\hat{\lambda}_i} \right) - \left( y_i - \hat{\lambda}_i \right) \right] \end{gather} \]
where \(y_i\) is the \(i\)th observed response in the training set of size \(n\). Note that when \(y_i = 0\) counts, then \(\log \left( \frac{y_i}{\hat{\lambda}_i} \right)\) is assumed as \(0\).
Moreover, df.null indicates the degrees of freedom of this model, which are \(n - 1 = 173 - 1 = 172\) (the difference between the training set size \(n\) and the number of regression parameters in the null model; which is \(1\) in this case, i.e., \(\beta_0\)).
Important
A null model is different from a saturated/baseline/full model. It is importat to recall that the saturated/baseline/full model is a model that perfectly fits the training data, which could be viewed as basically interpolating all the training data points without caring about any regressor at all. Mathematically, the saturated model implicates having an exact prediction \(\hat{\lambda}_i\) for each \(y_i\):
\[ \hat{\lambda}_i = y_i \quad \quad \text{for } i = 1, \dots, n. \]
3.4 Analysis of Deviance for Nested Models
We can use analysis of deviance for model selection when two models are nested. Hence, we will test our two Poisson models:
\[ \begin{align*} \textbf{Model 1:} \quad & \log(\lambda_i) = \beta_0 + \beta_1 X_{\texttt{width}_i}. \\[0.5em] \textbf{Model 2:} \quad & \log(\lambda_i) = \beta_0 + \beta_1 X_{\texttt{width}_i} + \beta_2 X_{\texttt{color\_darker}_i} \\ & \qquad\qquad\;\; + \beta_3 X_{\texttt{color\_light}_i} + \beta_4 X_{\texttt{color\_medium}_i}. \end{align*} \]
This specific model selection will involve a hypothesis testing. The hypotheses are:
\[ \begin{gather*} H_0: \textbf{Model 1} \text{ fits the data better than } \textbf{Model 2} \\ H_a: \textbf{Model 2} \text{ fits the data better than } \textbf{Model 1}. \end{gather*} \]
We have to use the multipurpose function anova() in the following way:
Let \(D_2\) be the deviance (column Resid. Dev) for Model 2 (poisson_model_2) in row 2 and \(D_1\) (column Resid. Dev) the deviance for Model 1 (poisson_model) in row 1. The test statistic \(\Delta_D\) (column Deviance) for the analysis of deviance is given by:
\[ \Delta_D = D_1 - D_2 \sim \chi^2_{3}, \]
which asymptotically (i.e., \(n \rightarrow \infty\)) is Chi-squared distributed with \(3\) degrees of freedom (column Df) under \(H_0\) for this specific case.
We obtain a \(p\text{-value} < .05\), column Pr(>Chi), which gives us evidence to reject \(H_0\) with \(\alpha = 0.05\). Hence, we do have evidence to conclude that poisson_model_2 fits the data better than poisson_model. Therefore, in the context of model selection, we would choose poisson_model_2, that also includes the color of the prosoma.
Important
In general, the degrees of freedom are the regression parameters of difference between both models (this has an impact on the factor-type explanatory variables with more than one dummy variable). In this example, Model 2 has three additional parameters: \(\beta_2\), \(\beta_3\), and \(\beta_4\).
Formally, this nested hypothesis testing is called the likelihood-ratio test.
3.5 Akaike Information Criterion
One of the drawbacks of the analysis of deviance is that it only allows to test nested regression models. Fortunately, we have alternatives for model selection. The AIC makes possible to compare models that are either nested or not. For a model with \(k\) model terms and a deviance \(D_k\) is defined as:
\[ \begin{equation} \mbox{AIC}_k = D_k + 2k. \end{equation} \]
Models with smaller values of \(\mbox{AIC}_k\) are preferred. That said, \(\mbox{AIC}_k\) favours models with small values of \(D_k\).
Important
However, \(\mbox{AIC}_k\) penalizes for including more regressors in the model. Hence, it discourages overfitting. This is why we select that model with the smallest \(\mbox{AIC}_k\).
The function glance() shows us the \(\mbox{AIC}_k\) by model.
Following the results of the
AICcolumn, we choosepoisson_model_2overpoisson_model.
3.6 Bayesian Information Criterion
An alternative to AIC is the Bayesian Information Criterion (BIC). The BIC also makes possible to compare models that are either nested or not. For a model with \(k\) regressors, \(n\) observations used for training, and a deviance \(D_k\); it is defined as:
\[ \mbox{BIC}_k = D_k + k \log (n). \]
Models with smaller values of \(\mbox{BIC}_k\) are preferred. That said, \(\mbox{BIC}_k\) also favours models with small values of \(D_k\).
Following the results of the
AICcolumn, we already chosepoisson_model_2overpoisson_model. Nonetheless, theBICis penalizing thepoisson_model_2for having more model parameters, sopoisson_modelwould be chosen under this criterion.
Important
The differences between AIC and BIC will be more pronounced in datasets with large sample sizes \(n\). As the BIC penalty of \(k \log (n)\) will always be larger than the AIC penalty of \(2k\) when \(n > 7\), BIC tends to select models with fewer regressors than AIC.
Having said all this, in general, each metric’s purpose can be summarized as follows:
- AIC: From a given set of models (either nested or non-nested) fitted via a common training dataset, this metric aims to select the model with the best predictive performance even though this model chosen might not be the true one that generates the training data. In essence, this metric is frequentist.
- BIC: From a given set of models (either nested or non-nested) fitted via a common training dataset, this metric will tend to select the true model that is generating the training data as the sample size \(n\) approaches infinity and as long as the true model is within this given set of models. This metric is Bayesian, in essence, since it relies on a prior true model probability distribution in conjunction with our observed evidence (i.e., the likelihoods yielded by each model of this set), which results in a posterior true model probability distribution indicating that true model (i.e., the one with the highest posterior probability).
Note
The math behind the rationale of these two metrics is out of the scope of this course. That said, if you would like to get further insights, you can check Chapter 7 (Model Assessment and Selection) in The Elements of Statistical Learning: Data Mining, Inference, and Prediction.
4 Categorical Type Responses
So far, we have dealt with continuous, binary, and count responses using OLS, Binary Logistic, Poisson (or Negative Binomial) regressions, respectively.
Nonetheless, we have not covered those discrete responses with more than two categories. Recall that the nature of these responses could be:
- Nominal. We have categories that do not follow any specific order—for example, the type of dwelling according to the Canadian census: single-detached house, semi-detached house, row house, apartment, and mobile home.
- Ordinal. The categories, in this case, follow a specific order—for example, a Likert scale of survey items: strongly disagree, disagree, neutral, agree, and strongly agree.
Moreover, you have seen that using OLS to fit a model with a binary response variable has important problems. Frequently, the restricted range is not respected in terms of the fitted values from our training set or if we use the fitted model to make predictions on a different testing set. So then, we use Binary Logistic regression.
Important
Recall that Binary Logistic regression’s link function (the logarithm of the odds or logit function) restricts the corresponding probability of success to a range between \(0\) and \(1\) while relating it to the systematic component (i.e., the regressors and its corresponding parameters!).
Nevertheless, this GLM has an important limitation: it is restricted to a Bernoulli trial with only two classes (success or failure).
Then, we might wonder:
What if we have more than two classes in the categorical response?
Let us pave the way to two new GLMs to address this matter: Multinomial and Ordinal Logistic regressions.
5 Multinomial Logistic Regression
Moving along with GLMs, let us expand the regression mind map as in Figure 2 to include a new model: Multinomial Logistic regression.
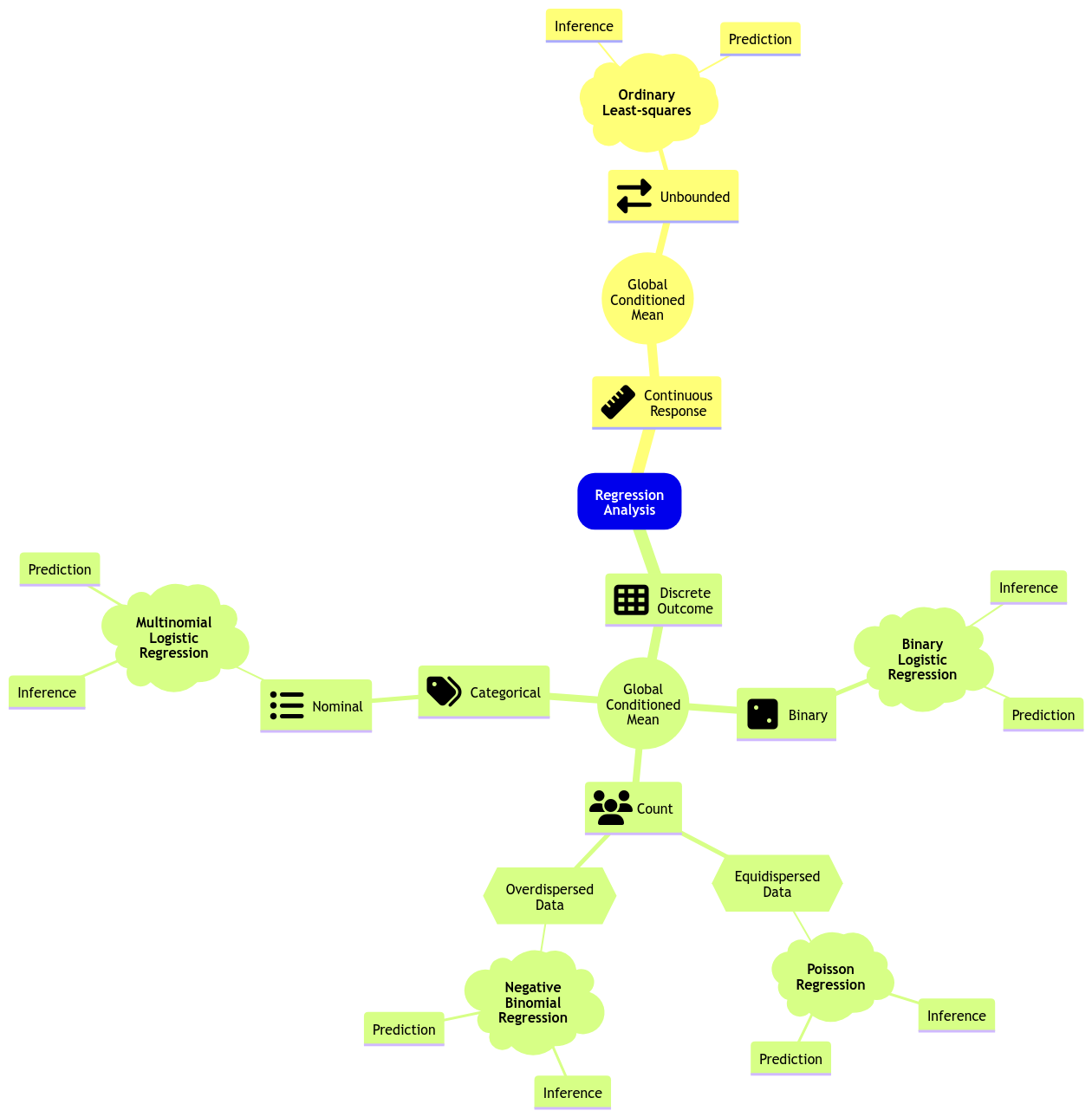
Multinomial Logistic regression is a maximum likelihood-based GLM that addresses inferential (and predictive!) inquiries where the response is categorical and nominal. To illustrate the use of this GLM, let us introduce an adequate dataset.
5.1 The Spotify Dataset
The spotify dataset is a sample of \(n = 350\) songs with different variables by column.
The Spotify Dataset
This data is sourced from the bayesrules package as a .rda file. Its description is the following:
A sub-sample of the Spotify song data originally collected by Kaylin Pavlik (kaylinquest) and distributed through the
Rfor Data Science TidyTuesday project.
Copyright © 2026 Spotify AB.
Spotify is a registered trademark of the Spotify Group.
This dataset has 23 variables in total. The \(n = 350\) songs belong to 44 different artists.
We will start with an in-class question via iClicker.
Exercise 4
Having checked the description of the spotify dataset, suppose we want to conduct an inferential study. What would be the primary nature of our conclusions?
A. We could draw causation conclusions across all music platforms.
B. We could draw association conclusions on the Spotify platform.
C. We could draw association conclusions across all music platforms.
D. We could draw causation conclusions on the Spotify platform.
Main Statistical Inquiries
I am big fan of the electronic dance music (edm) catalogue on Spotify. Nevertheless, I do not have access to their whole song database. Still, I would like to:
- Statistically quantify how danceable
edmis compared to other genres on the platform, and by how much. - Statistically quantify how euphoric
edmis compared to other genres on the platform, and by how much.
5.2 Data Wrangling and Summary
In terms of our main statistical inquiries, we will extract these key variables by song from the spotify dataset:
-
genre: genre of the playlist where the song belongs (a categorical and nominal variable). -
danceability: a numerical score from 0 (not danceable) to 100 (danceable) based on features such as tempo, rhythm, etc. -
valence: a numerical score from 0 (the song is more negative, sad, angry) to 100 (the song is more positive, happy, euphoric).
We will also extract these secondary variables (not to be used in our analysis, just for having a more informative training data):
-
title: song name. -
artist: song artist. -
album_name: name of the album on which the song appears.
Important
Note that factor-type genre has six levels (edm refers to electronic dance music and r&b to rhythm and blues). Moreover, from a coding perspective, edm is the baseline level (it is located on the left-hand side in the levels() output).
Finally, let us summarize the data by genre.
Important
Note that edm accounts for 17.1% of the whole training data. On the other hand, latin and rock account for less than 10% each. Finally, r&b has the largest share with 29.7%.
Still, having checked this genre composition, we have an acceptable number of songs to draw inference from. Moreover, an imbalanced classification will be dealt with the distributional assumption of the Multinomial Logistic regression.
5.3 Exploratory Data Analysis
As done in our previous lecture, let us take a look at the data first. Note that genre is a discrete nominal response, so we must be careful about the class of plots we use for exploratory data analysis (EDA). Hence, we could use the following side-by-side plots for both danceability and valence:
- Boxplots.
- Violin plots.
The code below creates side-by-side boxplots and violin plots, where danceability or valence are on the \(y\)-axis, and all categories of genre are on the \(x\)-axis. Moreover, the side-by-side violin plots show the mean of danceability or valence by genre as orange points.
Exercise 5
What can we see descriptively from the above plots?
5.4 Data Modelling Framework
A Multinomial Logistic Regression model is a suitable approach to our statistical inquiries given that genre is categorical and nominal (our response of interest) subject to the numerical regressors danceability and valence. Moreover, its corresponding regression estimates will allow us to measure variable association.
5.4.1 Primary Intuition of the Multinomial Logistic Regression Model
Digging into the Multinomial Logistic regression model will require checking Binary Logistic regression first. Hence, let us do it quickly. Thus, suppose we are initially interested in two genres: edm and latin.
Note edm is the baseline level (i.e., it appears on the left-hand side in the levels() output).
Assuming we have a training set of \(n\) elements, recall that the \(i\)th response (for \(i = 1, \dots, n\)) in a Binary Logistic regression is
\[Y_i = \begin{cases} 1 \; \; \; \; \mbox{if the genre is } \texttt{latin},\\ 0 \; \; \; \; \mbox{if the baseline genre is } \texttt{edm}. \end{cases} \]
Therefore
\[Y_i \sim \text{Bernoulli}(p_i),\]
whose probability of success is \(p_i\).
In this model, we will use the following link function (where \(X_{i,\texttt{dance}}\) anf \(X_{i,\texttt{val}}\) are the danceability and valence scores for the \(i\)th song, respectively):
\[ \begin{align*} \mbox{logit}(p_i) &= \log\left(\frac{p_i}{1 - p_i}\right) \nonumber \\ &= \log \left[ \frac{P(Y_i = \texttt{latin}\mid X_{i,\texttt{dance}}, X_{i,\texttt{val}})}{P(Y_i = \texttt{edm} \mid X_{i,\texttt{dance}}, X_{i,\texttt{val}})}) \right] \nonumber \\ &= \beta_0 + \beta_1 X_{i,\texttt{dance}} + \beta_2 X_{i,\texttt{val}}. \end{align*} \]
In plain words, the natural logarithm of the odds is equal to a systematic component containing the regressors \(X_{i,\texttt{dance}}\) and \(X_{i,\texttt{val}}\).
Recall that this model can be fitted as follows:
Note that only valence is statistically significant for the response genre (\(p\text{-value} < .001\)).
Then, we make the corresponding coefficient interpretations (the previous output already provides the estimate on the odds scale via exponentiate = TRUE):
For each unit increase in the
valencescore in the Spotify catalogue, the song is 1.05 times more probable to belatinthanedm.
5.4.2 More than One Logit Function
What if our response is nominal and has more than two categories? In that case, let us suppose that a given discrete nominal response \(Y_i\) has categories \(1, 2, \dots, m\).
Important
Categories \(1, 2, \dots, m\) are merely labels here. Thus, they do not implicate an ordinal scale.
This regression approach assumes a Multinomial distribution where \(p_{i,1}, p_{i,2}, \dots, p_{i,m}\) are the probabilities that \(Y_i\) will belong to categories \(1, 2, \dots, m\) respectively; i.e.,
\[ P(Y_i = 1) = p_{i,1} \;\;\;\; P(Y_i = 2) = p_{i,2} \;\; \dots \;\; P(Y_i = m) = p_{i,m}, \]
where
\[ \sum_{j = 1}^m p_{i,j} = p_{i,1} + p_{i,2} + \dots + p_{i,m} = 1. \]
Important
A particular highlight is that the Binomial distribution is the special Multinomial case when \(m = 2\).
The Multinomial Logistic regression also models the logarithm of the odds. However, only one logarithm of the odds (or logit) will not be enough anymore. Recall we can capture the odds between two categories with a single logit function. What about adding some other ones?
Here is what we can do:
- Pick one of the categories to be the baseline. For example, the category “\(1\)”.
- For each of the other categories, we model the logarithm of the odds to the baseline category.
Now, what is the math for the general case with \(m\) response categories and \(k\) regressors? For the \(i\)th observation, we end up with a system of \(m - 1\) link functions in the Multinomial Logistic regression model as follows:
\[ \begin{align*} \eta_i^{(2,1)} &= \log\left[\frac{P(Y_i = 2\mid X_{i,1}, \ldots, X_{i,k})}{P(Y_i = 1 \mid X_{i,1}, \ldots, X_{i,k})}\right] \\ &= \beta_0^{(2,1)} + \beta_1^{(2,1)} X_{i, 1} + \beta_2^{(2,1)} X_{i, 2} + \ldots + \beta_k^{(2,1)} X_{i, k} \\ \eta_i^{(3,1)} &= \log\left[\frac{P(Y_i = 3\mid X_{i,1}, \ldots, X_{i,k})}{P(Y_i = 1 \mid X_{i,1}, \ldots, X_{i,k})}\right] \\ &= \beta_0^{(3,1)} + \beta_1^{(3,1)} X_{i, 1} + \beta_2^{(3,1)} X_{i, 2} + \ldots + \beta_k^{(3,1)} X_{i, k} \\ & \qquad \qquad \qquad \qquad \vdots \\ \eta_i^{(m,1)} &= \log\left[\frac{P(Y_i = m\mid X_{i,1}, \ldots, X_{i,k})}{P(Y_i = 1 \mid X_{i,1}, \ldots, X_{i,k})}\right] \\ &= \beta_0^{(m,1)} + \beta_1^{(m,1)} X_{i, 1} + \beta_2^{(m,1)} X_{i, 2} + \ldots + \beta_k^{(m,1)} X_{i, k}. \end{align*} \tag{3}\]
Important
Note that the superscript \((j, 1)\) in Equation 3 indicates that the equation is on level \(j\) (for \(j = 2, \dots, m\)) with respect to level \(1\). Furthermore, the regression intercept and coefficients are different for each link function.
With some algebraic manipulation, we can show that the probabilities \(p_{i,1}, p_{i,2}, \dots, p_{i,m}\) of \(Y_i\) belonging to categories \(1, 2, \dots, m\) are:
\[ \begin{gather*} p_{i,1} = P(Y_i = 1 \mid X_{i,1}, \ldots, X_{i,k}) = \frac{1}{1 + \sum_{j = 2}^m \exp \big( \eta_i^{(j,1)} \big)} \\ p_{i,2} = P(Y_i = 2 \mid X_{i,1}, \ldots, X_{i,k}) = \frac{\exp \big( \eta_i^{(2,1)} \big)}{1 + \sum_{j = 2}^m \exp \big( \eta_i^{(j,1)} \big)} \\ \vdots \\ p_{i,m} = P(Y_i = m \mid X_{i,1}, \ldots, X_{i,k}) = \frac{\exp \big( \eta_i^{(m,1)} \big)}{1 + \sum_{j = 2}^m \exp \big( \eta_i^{(j,1)} \big)}. \end{gather*} \tag{4}\]
Important
If we sum all \(m\) probabilities in Equation 4, the sum will be equal to \(1\) for the \(i\)th observation. This is particularly important when we want to use this model for making predictions in classification matters.
Going back to our example, let us set the Multinomial Logistic regression model with genre as a response subject to danceability and valence as a continuous regressor. Level edm will be the baseline:
Specifically, this case will implicate a system of \(m - 1 = 6 - 1= 5\) regression equations (where \(X_{i,\texttt{dance}}\) and \(X_{i,\texttt{val}}\) are the danceability and valence scores for the \(i\)th song, respectively):
\[ \begin{align*} \eta_i^{(\texttt{latin},\texttt{edm})} &= \log\left[\frac{P(Y_i = \texttt{latin} \mid X_{i, \texttt{dance}}, X_{i, \texttt{val}})}{P(Y_i = \texttt{edm} \mid X_{i, \texttt{dance}}, X_{i, \texttt{val}})}\right] \\ &= \beta_0^{(\texttt{latin},\texttt{edm})} + \beta_1^{(\texttt{latin},\texttt{edm})} X_{i, \texttt{dance}} + \beta_2^{(\texttt{latin},\texttt{edm})} X_{i, \texttt{val}} \\ \eta_i^{(\texttt{pop},\texttt{edm})} &= \log\left[\frac{P(Y_i = \texttt{pop} \mid X_{i, \texttt{dance}}, X_{i, \texttt{val}})}{P(Y_i = \texttt{edm} \mid X_{i, \texttt{dance}}, X_{i, \texttt{val}})}\right] \\ &= \beta_0^{(\texttt{pop},\texttt{edm})} + \beta_1^{(\texttt{pop},\texttt{edm})} X_{i, \texttt{dance}} + \beta_2^{(\texttt{pop},\texttt{edm})} X_{i, \texttt{val}} \\ \eta_i^{(\texttt{r\&b},\texttt{edm})} &= \log\left[\frac{P(Y_i = \texttt{r\&b} \mid X_{i, \texttt{dance}}, X_{i, \texttt{val}})}{P(Y_i = \texttt{edm} \mid X_{i, \texttt{dance}}, X_{i, \texttt{val}})}\right] \\ &= \beta_0^{(\texttt{r\&b},\texttt{edm})} + \beta_1^{(\texttt{r\&b},\texttt{edm})} X_{i, \texttt{dance}} + \beta_2^{(\texttt{r\&b},\texttt{edm})} X_{i, \texttt{val}} \\ \eta_i^{(\texttt{rap},\texttt{edm})} &= \log\left[\frac{P(Y_i = \texttt{rap} \mid X_{i, \texttt{dance}}, X_{i, \texttt{val}})}{P(Y_i = \texttt{edm} \mid X_{i, \texttt{dance}}, X_{i, \texttt{val}})}\right] \\ &= \beta_0^{(\texttt{rap},\texttt{edm})} + \beta_1^{(\texttt{rap},\texttt{edm})} X_{i, \texttt{dance}} + \beta_2^{(\texttt{rap},\texttt{edm})} X_{i, \texttt{val}} \\ \eta_i^{(\texttt{rock},\texttt{edm})} &= \log\left[\frac{P(Y_i = \texttt{rock} \mid X_{i, \texttt{dance}}, X_{i, \texttt{val}})}{P(Y_i = \texttt{edm} \mid X_{i, \texttt{dance}}, X_{i, \texttt{val}})}\right] \\ &= \beta_0^{(\texttt{rock},\texttt{edm})} + \beta_1^{(\texttt{rock},\texttt{edm})} X_{i, \texttt{dance}} + \beta_2^{(\texttt{rock},\texttt{edm})} X_{i, \texttt{val}}. \end{align*} \tag{5}\]
Important
In a Multinomial Logistic regression model, each link function has its own intercept and regression coefficients.
The modelling system of 5 logit functions found in 5 can also be mathematically represented as follows (which might be helpful for our subsequent coefficient interpretation:
\[ \begin{align*} \frac{P(Y_i = \texttt{latin}\mid X_{i,\texttt{dance}}, X_{i,\texttt{val}})}{P(Y_i = \texttt{edm} \mid X_{i,\texttt{dance}}, X_{i,\texttt{val}})} &= \exp\left[\beta_0^{(\texttt{latin},\texttt{edm})}\right] \times \exp\left[\beta_1^{(\texttt{latin},\texttt{edm})} X_{i,\texttt{dance}}\right] \times \\ & \qquad \exp\left[\beta_2^{(\texttt{latin},\texttt{edm})} X_{i,\texttt{val}}\right] \\ \frac{P(Y_i = \texttt{pop}\mid X_{i,\texttt{dance}}, X_{i,\texttt{val}})}{P(Y_i = \texttt{edm} \mid X_{i,\texttt{dance}}, X_{i,\texttt{val}})} &= \exp\left[\beta_0^{(\texttt{pop},\texttt{edm})}\right] \times \exp\left[\beta_1^{(\texttt{pop},\texttt{edm})} X_{i,\texttt{dance}}\right] \times \\ & \qquad \exp\left[\beta_2^{(\texttt{pop},\texttt{edm})} X_{i,\texttt{val}}\right] \\ \frac{P(Y_i = \texttt{r\&b}\mid X_{i,\texttt{dance}}, X_{i,\texttt{val}})}{P(Y_i = \texttt{edm} \mid X_{i,\texttt{dance}}, X_{i,\texttt{val}})} &= \exp\left[\beta_0^{(\texttt{r\&b},\texttt{edm})}\right] \times \exp\left[\beta_1^{(\texttt{r\&b},\texttt{edm})} X_{i,\texttt{dance}}\right] \times \\ & \qquad \exp\left[\beta_2^{(\texttt{r\&b},\texttt{edm})} X_{i,\texttt{val}}\right]\\ \frac{P(Y_i = \texttt{rap}\mid X_{i,\texttt{dance}}, X_{i,\texttt{val}})}{P(Y_i = \texttt{edm} \mid X_{i,\texttt{dance}}, X_{i,\texttt{val}})} &= \exp\left[\beta_0^{(\texttt{rap},\texttt{edm})}\right] \times \exp\left[\beta_1^{(\texttt{rap},\texttt{edm})} X_{i,\texttt{dance}}\right] \times \\ & \qquad \exp\left[\beta_2^{(\texttt{rap},\texttt{edm})} X_{i,\texttt{val}}\right]\\ \frac{P(Y_i = \texttt{rock}\mid X_{i,\texttt{dance}}, X_{i,\texttt{val}})}{P(Y_i = \texttt{edm} \mid X_{i,\texttt{dance}}, X_{i,\texttt{val}})} &= \exp\left[\beta_0^{(\texttt{rock},\texttt{edm})}\right] \times \exp\left[\beta_1^{(\texttt{rock},\texttt{edm})} X_{i,\texttt{dance}}\right] \times \\ & \qquad \exp\left[\beta_2^{(\texttt{rock},\texttt{edm})} X_{i,\texttt{val}}\right]. \end{align*} \tag{6}\]
Finally, the probabilities of \(Y_i\) belonging to categories edm, latin, pop, r&b, rap, and rock are:
\[ \begin{gather*} p_{i,\texttt{edm}} = P(Y_i = \texttt{edm} \mid X_{i,\texttt{dance}}, X_{i,\texttt{val}}) \\ = \frac{1}{1 + \exp\big(\eta_i^{(\texttt{latin},\texttt{edm})}\big) + \exp\big(\eta_i^{(\texttt{pop},\texttt{edm})}\big) + \exp\big(\eta_i^{(\texttt{r\&b},\texttt{edm})}\big) + \exp\big(\eta_i^{(\texttt{rap},\texttt{edm})}\big) + \exp\big(\eta_i^{(\texttt{rock},\texttt{edm})}\big)} \\ p_{i,\texttt{latin}} = P(Y_i = \texttt{latin} \mid X_{i,\texttt{dance}}, X_{i,\texttt{val}}) \\ = \frac{\exp\big(\eta_i^{(\texttt{latin},\texttt{edm})}\big)}{1 + \exp\big(\eta_i^{(\texttt{latin},\texttt{edm})}\big) + \exp\big(\eta_i^{(\texttt{pop},\texttt{edm})}\big) + \exp\big(\eta_i^{(\texttt{r\&b},\texttt{edm})}\big) + \exp\big(\eta_i^{(\texttt{rap},\texttt{edm})}\big) + \exp\big(\eta_i^{(\texttt{rock},\texttt{edm})}\big)}\\ p_{i,\texttt{pop}} = P(Y_i = \texttt{pop} \mid X_{i,\texttt{dance}}, X_{i,\texttt{val}}) \\ = \frac{\exp\big(\eta_i^{(\texttt{pop},\texttt{edm})}\big)}{1 + \exp\big(\eta_i^{(\texttt{latin},\texttt{edm})}\big) + \exp\big(\eta_i^{(\texttt{pop},\texttt{edm})}\big) + \exp\big(\eta_i^{(\texttt{r\&b},\texttt{edm})}\big) + \exp\big(\eta_i^{(\texttt{rap},\texttt{edm})}\big) + \exp\big(\eta_i^{(\texttt{rock},\texttt{edm})}\big)} \\ p_{i,\texttt{r\&b}} = P(Y_i = \texttt{r\&b} \mid X_{i,\texttt{dance}}, X_{i,\texttt{val}}) \\ = \frac{\exp\big(\eta_i^{(\texttt{r\&b},\texttt{edm})}\big)}{1 + \exp\big(\eta_i^{(\texttt{latin},\texttt{edm})}\big) + \exp\big(\eta_i^{(\texttt{pop},\texttt{edm})}\big) + \exp\big(\eta_i^{(\texttt{r\&b},\texttt{edm})}\big) + \exp\big(\eta_i^{(\texttt{rap},\texttt{edm})}\big) + \exp\big(\eta_i^{(\texttt{rock},\texttt{edm})}\big)} \\ p_{i,\texttt{rap}} = P(Y_i = \texttt{rap} \mid X_{i,\texttt{dance}}, X_{i,\texttt{val}}) \\ = \frac{\exp\big(\eta_i^{(\texttt{rap},\texttt{edm})}\big)}{1 + \exp\big(\eta_i^{(\texttt{latin},\texttt{edm})}\big) + \exp\big(\eta_i^{(\texttt{pop},\texttt{edm})}\big) + \exp\big(\eta_i^{(\texttt{r\&b},\texttt{edm})}\big) + \exp\big(\eta_i^{(\texttt{rap},\texttt{edm})}\big) + \exp\big(\eta_i^{(\texttt{rock},\texttt{edm})}\big)} \\ p_{i,\texttt{rock}} = P(Y_i = \texttt{rock} \mid X_{i,\texttt{dance}}, X_{i,\texttt{val}}) \\ = \frac{\exp\big(\eta_i^{(\texttt{rock},\texttt{edm})}\big)}{1 + \exp\big(\eta_i^{(\texttt{latin},\texttt{edm})}\big) + \exp\big(\eta_i^{(\texttt{pop},\texttt{edm})}\big) + \exp\big(\eta_i^{(\texttt{r\&b},\texttt{edm})}\big) + \exp\big(\eta_i^{(\texttt{rap},\texttt{edm})}\big) + \exp\big(\eta_i^{(\texttt{rock},\texttt{edm})}\big)}. \end{gather*} \tag{7}\]
Now, let us discuss some in-class questions:
Exercise 6
Answer TRUE or FALSE:
Now that we removed the restriction of only one link function, we also removed the distributional assumption for \(Y_i\). Hence, our model has no distributional assumption.
A. TRUE
B. FALSE
Exercise 7
Answer TRUE or FALSE:
From the statistical point of view, the model is now non-parametric.
A. TRUE
B. FALSE
Exercise 8
Suppose that, given our inquiries, a peer suggests we fit two separate OLS with genre as a regressor and danceability OR valence as the responses. Can you think of some drawbacks of this suggested approach?
5.5 Estimation
All parameters in the Multinomial Logistic regression model are also unknown. To fit the model with the package nnet, we use the function multinom(), which obtains the corresponding estimates. The estimates are obtained through maximum likelihood, where we assume a Multinomial joint probability mass function of the \(n\) responses \(Y_i\).
Important
You might wonder:
Why are we using an
Rpackage related to neural networks, such as nnet, to fit a Mutinomial Logistic regression model?
It turns out that a one-layer neural network for multiclass response classification is basically a Multinomial Logistic regression with a different vocabulary.
- Using Machine Learning jargon, in Multinomial Logistic regression, we compute one linear score per class (i.e., the systematic component represented by an intercept plus the corresponding coefficients multiplied by the regressors).
- In a single-layer neural network, we do the exact same thing: one weighted sum plus bias per class (i.e., the \(m-1\) logit functions found in 3).
- Both modelling approaches (Multinomial Logistic regression and a single-layer neural network for multiclass response classification) convert those scores into class probabilities using softmax functions (as in 4 in general for \(m\) response categories), and we typically estimate the regression parameters (intercept and coefficients) by maximizing the likelihood of our observed training data (equivalently, in Machine Learning, minimizing cross-entropy loss).
- In general, with \(m\) categories in our response, note that a softmax function is just the way we go back from those \(m-1\) log-odds relationships to actual probabilities for all \(m\) categories. In other words, the model is linear in the \(m-1\) logit functions found in 3, and a softmax function is the inverse mapping that produces probabilities.
Note
We will not dig into mathematical derivations regarding maximum likelihood estimation (MLE) for this model since it would require digging into matrix notation, which is out of this course’s scope. That said, you can find more information on this matter here.
5.6 Inference
We can determine whether a regressor is statistically associated with the logarithm of the odds through hypothesis testing for the parameters \(\beta_j^{(u, v)}\) by link function. We also use the Wald statistic \(z_j^{(u, v)}\):
\[ \begin{equation*} z_j^{(u, v)} = \frac{\hat{\beta}_j^{(u, v)}}{\mbox{se}\left(\hat{\beta}_j^{(u, v)}\right)} \end{equation*} \]
to test the hypotheses
\[ \begin{gather*} H_0: \beta_j^{(u, v)} = 0\\ H_a: \beta_j^{(u, v)} \neq 0. \end{gather*} \]
Provided the sample size \(n\) is large enough, \(z_j\) has an approximately Standard Normal distribution under \(H_0\).
R provides the corresponding \(p\)-values for each \(\beta_j^{(u, v)}\). The smaller the \(p\)-value, the stronger the evidence against the null hypothesis \(H_0\). As in the previous regression models, we would set a predetermined significance level \(\alpha\) (usually taken to be 0.05) to infer if the \(p\)-value is small enough. If the \(p\)-value is smaller than the predetermined level \(\alpha\), then you could claim that there is evidence to reject the null hypothesis. Hence, \(p\)-values that are small enough indicate that the data provides evidence in favour of association (or causation in the case of an experimental study!) between the response variable and the \(j\)th regressor.
Furthermore, given a specified level of confidence where \(\alpha\) is the significance level, we can construct approximate \((1 - \alpha) \times 100\%\) confidence intervals for the corresponding true value of \(\beta_j^{(u, v)}\):
\[ \begin{equation*} \hat{\beta}_j^{(u, v)} \pm z_{\alpha/2}\mbox{se} \left( \hat{\beta}_j^{(u, v)} \right), \end{equation*} \]
where \(z_{\alpha/2}\) is the upper \(\alpha/2\) quantile of the Standard Normal distribution.
We can also use the function tidy() from the broom package along with argument conf.int = TRUE to get the 95% confidence intervals by default.
The 15 exponentiated estimated regression parameters (via exponentiate = TRUE in tidy()) from the right-hand side of the equation system in 6 appear in the column estimate. Note that column y.level is related to the non-baseline level per function. Finally, to draw our inferential conclusions, let us filter those \(p\)-values less than \(0.05\) from mult_output:
Since our baseline response is edm, we can conclude the following with \(\alpha = 0.05\) on the Spotify platform:
- There is a statistical difference in
danceabilityinedmversusr&bandrock. - There is a statistical difference in
valenceinedmversuslatin.
5.7 Coefficient Interpretation
Interpretation of the Multinomial Logistic regression coefficients is quite similar to the Binary Logistic regression. Let us interpret those significant regression coefficientes from column estimate:
\(\beta_2^{(\texttt{latin},\texttt{edm})}\): for each unit increase in the
valencescore in the Spotify catalogue, the song is \(1.05\) times more probable to belatinthanedm.
\(\beta_1^{(\texttt{r\&b},\texttt{edm})}\): for each unit increase in the
danceabilityscore in the Spotify catalogue, the odds for a song for beingr&bdecrease by \((1 - 0.963) \times 100\% = 3.7\%\) compared toedm.
\(\beta_1^{(\texttt{Rock},\texttt{edm})}\): for each unit increase in the
danceabilityscore in the Spotify catalogue, the odds for a song for beingrockdecrease by \((1 - 0.918) \times 100\% = 8.2\%\) compared toedm.
Important
If we want to use another genre as a baseline under this modelling approach, we would need to relevel our factor-type response and rerun the whole process.
Also, this example does not include categorical regressors. Nevertheless, interpreting their corresponding estimated regression coefficients is analogous to Binary Logistic regression using the baseline response level.
5.8 Predictions
Suppose we want to predict the genre probabilities for a given song with a danceability score of 27.5 and valence of 30 (i.e., applying the equations found in 7). We could use the model spotify_mult_log_model for making such prediction as follows:
Note we have to use type = "probs" in the function predict() to obtain these predictions. Therefore, this given song has more chances of being classified as r&b.
5.9 Model Selection
To perform model selection, we can use the same techniques from the Binary Logistic regression model. That said, some R coding functions might not be entirely available for the multinom() models. Still, these statistical techniques and metrics can be manually coded.
6 Wrapping Up on Model Selection and Multinomial Logistic Regression
- MLE can be used as a tool in model selection to assess the goodness of fit of our estimated models (via some training data).
- Deviance is a suitable model selection method for nested models.
- Conversely, AIC and BIC are adequate metrics for model selection when comparing non-nested models.
- An important advantage of deviance, AIC, and BIC is that they can be used across different regression models (as long as they are estimated via MLE).
- Multinomial Logistic regression is a key approach for categorical and nominal responses when we have more than two categories.
- The above regression is an extension of Binary Logistic regression. Hence, we establish a modelling system of logit functions before performing the corresponding parameter estimation. Note that inference and coefficient interpretation are conducted in a similar fashion compared to Binary Logistic regression.