Lecture 8: Missing Data
1 Slides
2 Today’s Learning Goals
By the end of this lecture, you should be able to:
- Identify and explain the three common types of missing data mechanisms.
- Identify a potential consequence of removing missing data on downstream analyses.
- Identify a potential consequence of a mean imputation method on downstream analyses.
- Identify the four steps involved with a multiple imputation method for handling missing data.
- Use the mice package in
Rto fit multiple imputed models.
3 Types of Missing Data
In Statistics, there are three types of missing data:
- Missing completely at random (MCAR).
- Missing at random (MAR).
- Missing not at random (MNAR).
It is in our best interest to identify the type of missing data we have. Proper identification will determine the class of approach we will take to deal with missingness in any statistical analysis.
3.1 Missing Completely At Random (MCAR)
In this type, missing data appear totally by chance. Hence, missingness is independent of the data. Roughly speaking, all our observations (rows in the dataset) have the same chance of containing missing data (i.e., an NA in one of the columns).
Important
It is the ideal class of missing data since there is no missingness pattern.
Example
We are trying to count the number of car accidents in Vancouver. To do that, we are monitoring the traffic in 100 strategic points of the city with cameras. Say that we count how many vehicles passed by each one of those cameras for every minute of the day. We have 101 variables: time, Camera_1, …, Camera_100.
Suppose that any camera has a \(1\%\) chance of failing for any given minute. If a camera fails, you get MCAR data for that minute.
3.2 Missing At Random (MAR)
In this type, missingness depends on the observed data we have. Therefore, we could use some imputation techniques for this missingness, such as multiple imputation (to be covered later on today), based on the rest of our available data (a hot deck imputation technique).
Important
Missing data imputation techniques are divided into two classes:
- Hot deck: Those incomplete rows in our current dataset are imputed using the information provided by the complete rows within the same dataset.
- Cold deck: Those incomplete rows in our current dataset are imputed using the information provided by the complete rows of another dataset with the same column structure.
The scope of this lecture pertains to hot deck techniques.
Example
Following up with the previous example, an external device is attached to the cameras to increase the image quality at low light situations (night time) and we have the recording time in our dataset. The external device is activated from 6 p.m. to 5 a.m. However, the device has a \(10\%\) chance of not working in a given minute. The chances are not the same for all the observations but depend on the data we observed, more specifically, night time.
3.3 Missing Not At Random (MNAR)
This is the most serious type of missingness since the MNAR data depends on unobservable quantities.
Example
With the previous example, if we did not record time, we would have MNAR data since we do not have any other information rather than just the car count. Another missingness cause of this type would be that, as the cameras get older, their probability of failure increases, but we cannot check this from our observed data.
4 Handling Missing Data
We will explore different techniques to impute missing data based on the type of missingness.
4.1 Listwise Deletion
It is the simplest way to deal with missing data.
Is there any missing data in your row?
If yes, we just remove the row!
If the data is MCAR, we are not introducing bias by removing the rows. We can still get unbiased estimators for whichever our analysis is, such as regression coefficients.
We can also estimate the standard errors correctly, but they will be higher than they could be since we discard incomplete observations.
Exercise 27
Are these higher standard errors related to the MCAR nature of the deleted rows?
A. Yes.
B. No.
Let us start with our lecture’s toy dataset: the flights dataset from the package nycflights13. It contains the on-time data of 336,776 flights that departed New York City in 2013.
We will use the following columns:
-
dep_delay: departure delays in minutes. -
arr_delay: arrival delays in minutes. -
carrier: two-letter carrier abbreviation.
We will try getting the mean dep_delay per carrier, but we have missing data in dep_delay, which will return a summary with NAs.
Assuming data is MCAR, if we want to make a listwise deletion to get the means by carrier, we just use na.rm = TRUE in mean().
Nonetheless, we have to be careful. If the missing data in flights is not MCAR, we can introduce serious bias in our estimates (means in this case) for some given statistical approach.
Important
But, why a bias?
Let us set another example to explain the bias issue when data missingness is present. Suppose that people with low income have a higher chance of omitting their income (as a numeric variable) in a given survey used for Regression Analysis. Then, if we just drop those rows, we are skewing our analysis towards people with higher income without knowing. So, there will be a bias in our regression estimates.
Exercise 28
Let us retake the previous survey example regarding low-income respondents. Suppose this survey collects additional information, such as the respondent’s specific neighbourhood, which is a complete column. Then, you could match this extra information with some other neighbourhood databases identifying low, middle, and high-income areas.
What class of missing data are these missing numeric incomes in the survey?
A. MCAR.
B. MAR.
C. MNAR.
4.2 Mean Imputation
The title is very suggestive. Let us just use the mean of our variable of interest to impute the missing data.
Important
This imputation technique can only be used with continuous and count-type variables!
Re-taking the flights dataset, for the exercise’s sake (not to be generalized to other data cases), we will filter those observations with NAs in arr_delay OR dep_delay values larger than 100 minutes. Then, we will only sample 1000 flights.
Attention
Note the condition dep_delay > 100 is also depicted in the plot.
The blue line is just the estimated Ordinary Least-squares (OLS) linear regression of dep_delay versus arr_delay with 593 complete observations. Nonetheless, since the conditional is is.na(arr_delay) | dep_delay > 100 (i.e., OR), we would eventually have an imputed subset of observations with negative dep_delay, i.e., flights on time but missing arr_delay. We can see some rows under this situation in the below data frame.
This missigness pattern will provide a particular behaviour in our subsequent mean imputations.
Moving along, it is necessary to perform an exploratory data analysis (EDA) on our data missingness. We can use the function md.pattern() from the package mice to display missing data patterns.
We can interpret the table (and diagram) above in the following way:
Important
- For the table, in the columns
dep_delayandarr_delay(rows 1 to 3):-
0indicates that neither of the variables is missing (right-hand side). -
1indicates that one variable is present (right-hand side). -
2indicates that two variables are missing (right-hand side). - Row numbers indicate those observations with the variables present/missing:
-
593indicates the number of rows wheredep_delayandarr_delayare jointly present (left-hand side). -
53indicates the number of rows wheredep_delayis present andarr_delayis missing (left-hand side). -
354indicates the number of rows wheredep_delayandarr_delayare jointly missing (left-hand side). - Then, we have \(593 + 53 + 354 = 1000\) rows in total (our sample size!).
-
- Column numbers indicate those observations with the standalone missing variables:
-
354indicates the number of rows wheredep_delayis missing, regardless of whetherarr_delayis missing or not. -
407indicates the number of rows wherearr_delayis missing, regardless of whetherdep_delayis missing or not.
-
-
- For the columns in the diagram
dep_delayandarr_delay, the coloured cells indicate:- Blue indicates that the variable is present.
- Red indicates that the variable is missing.
Therefore, we have 593 observations with non-missing data in both dep_delay and arr_delay, 53 with arr_delay missing, and 354 with both dep_delay and arr_delay missing.
The md.pattern() summary shows that our sample does NOT contain observations where dep_delay is missing and arr_delay is present.
Now, we will impute the overall means of dep_delay and arr_delay.
We will now plot the imputed values as purple points, and another estimated OLS linear regression in red with the \(n = 1000\) sampled observations (non-imputed AND imputed).
Note the horizontal pattern in the imputed purple points, which is the subset of observations with the particular behaviour we previously mentioned.
Also, notice that by imputing the mean, we are artificially reducing the standard deviation of our data which is a drawback of mean imputation.
Important
This behaviour on the sample standard deviation is explained given its mathematical computation:
\[s = \sqrt{\sum_{i = 1}^n \frac{(x_i - \bar{x})^2}{n - 1}}.\]
Note that this \(s\) will be quite sensitive when imputing values with the corresponding mean \(\bar{x}\).
Having said all this, let us proceed to a more “robust” imputation method.
4.3 Regression Imputation
From the black points (complete observations) in the previous plot, we can notice a clear positive relation between arr_delay changes with dep_delay. Hence, why not using the estimated OLS linear regression in blue (fitted with those complete 593 observations) to estimate those missing values?
We can do it automatically via mice() using method = "norm.predict".
Then, we plot our dataset (including those imputted data points using OLS).
Now, all the purple points (imputed values) are on the imputed fit (red) line, which is now just an extension of the observed fit (blue) line.
Since the method imputes all the points perfectly in the regression line, we will reinforce the data’s relationships. For example, let us calculate the correlation of the imputed data versus the observed data.
Important
Regression imputation seems to have a more “inline” behaviour for imputed data than just using the mean since we are basically using regression-fitted values for this missing data. Moreover, we can extend this framework to more than two variables simultaneously.
Nevertheless, we still fix our imputation on a single set of estimated regression parameters. In fact, we could have a more clever strategy that would rely on different simulated datasets given what prior COMPLETE information we have in our dataset. Section 4.5 will explore this strategy in further detail.
4.4 Last Observation Carried Over
Another method that we might see out there is imputing data by repeating the previous observation. This is more frequent when dealing with temporal data, and will be out of the scope of this course.
4.5 Multiple Imputation
Having explored mean and regression imputations, let us proceed to a simulation-based method called multiple imputation.
We have seen that using a single value for the imputation causes problems, such as reducing our dataset variance. Then, a handy approach is the multiple imputation method.
The idea here is, instead of imputing one value for missing data, we impute multiple values. But how can we do it?
We can do it via the mice() function, which offers this multiple imputation method. MICE stands for Multiple Imputation by Chained Equations.
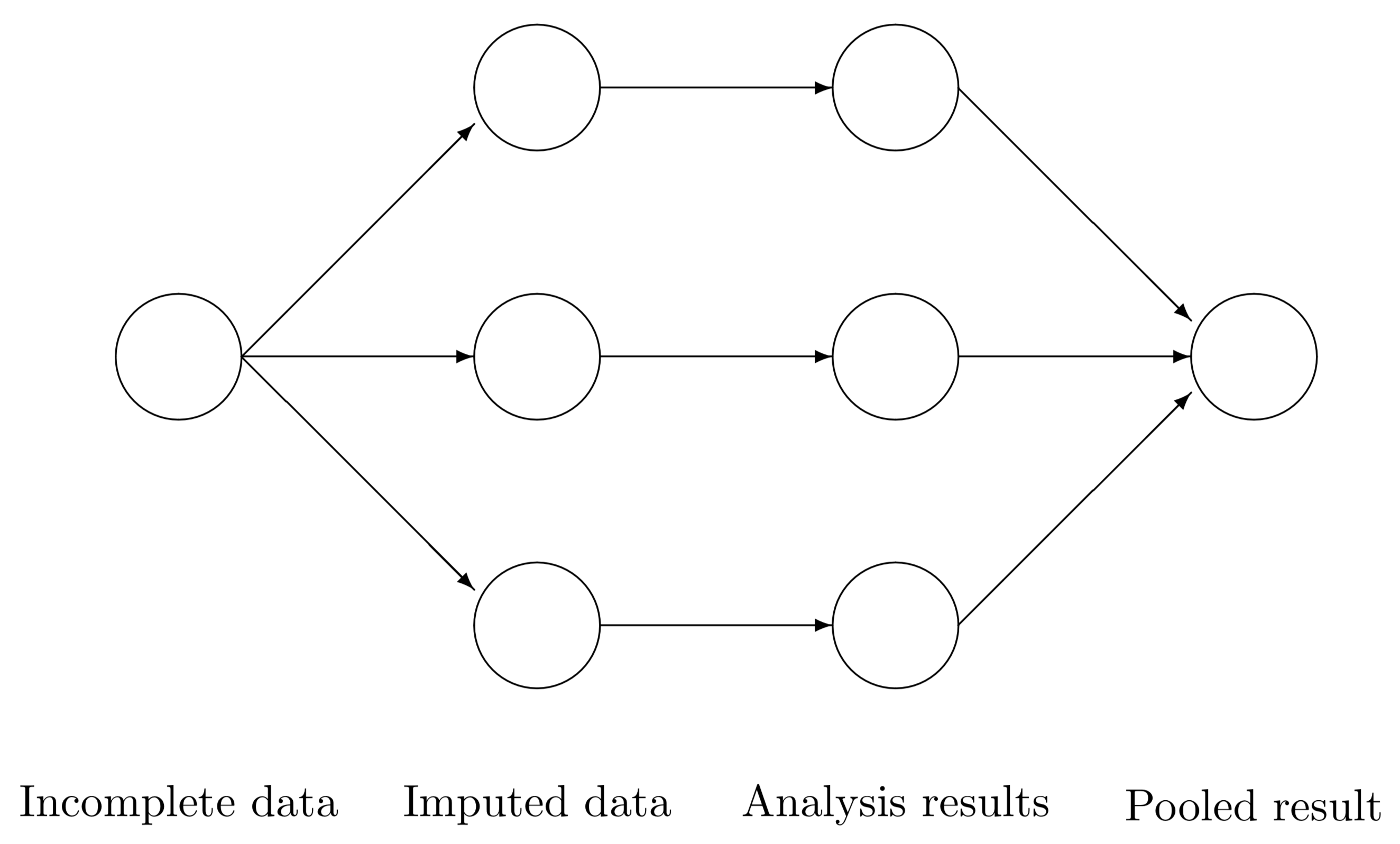
Roughly speaking, for a data frame data, the four automatic steps in this R function are the following:
- Create
mcopies of this dataset:data_1,data_2,…,data_m. - In each copy, impute the missing data with different values (the observed values will remain the same).
- Carry out the analysis for each dataset separately. For example, fit an OLS linear regression model for each one of the datasets
data_1,data_2,…,data_mwhen you have a continuous variable to impute. - Combine the separate models into one final pooled model.
We would use our pooled model, fitted with our response of interest subject to our regressor set, to answer our inferential or predictive inquiries. The diagram in Figure 1 provides a clearer perspective
Important
Note that the suitable regression model will be chosen accordingly depending on the nature of our variable of interest to impute. Therefore, mice() will use the following regression models:
- Binary Logistic regression for binary variables.
- Multinomial Logistic regression for categorical and nominal variables.
- Ordinal Logistic regression for categorical and ordinal variables.
We have to make sure to set up the correct variable type before imputing!
Now, how do we impute the missing data in step 2?
By default, mice() implements the predictive mean matching (PMM) found in Rubin (1987) on page 166. With two columns \(X\) and \(Y\) (where \(X\) is complete and \(Y\) has some rows with NAs), we follow this univariate Bayesian method:
- Estimate the OLS linear regression parameters \(\hat{\beta}_0\), \(\hat{\beta}_1\), and \(\hat{\sigma^2}\) of the column where the missing values to impute are located (as the response, i.e., \(Y\)) versus the other complete column (as the regressor, \(X\)), using the observed complete rows only (i.e., where \(X\) and \(Y\) are both present).
- Draw \(\beta_0^*\), \(\beta_1^*\), and \(\sigma^{2^*}\) using proper posterior distributions where the inputs are \(\hat{\beta}_0\), \(\hat{\beta}_1\), and \(\hat{\sigma^2}\).
- Compute the fitted values \(\hat{y}_i^*\) for the column \(Y\) in step (1): we use \(\beta_0^*\) and \(\beta_1^*\) for both non-missing and missing rows.
- For each fitted value \(\hat{y}_i^*\) corresponding to those missing rows in \(Y\), we find a given number of donors (5 by default in
mice()) from all the \(\hat{y}_i^*\) (corresponding to those non-missing rows in \(Y\)) which are the closest ones to each missing case. - We randomly select one of these donors (using its real observed value in \(Y\)!) to impute the corresponding missing value.
- The process is repeated
mtimes.
Important
Note that this algorithm also has a multivariate version where NAs can be present in more than one column.
Let us implement this univariate process with sampled_flights with m = 20.
We can check the imputed values for a specific column (e.g., arr_delay) in these 20 datasets as follows:
Each row corresponds to a missing observation in your original dataset. The columns are the m imputed datasets that were created.
We can get each one of the m imputed datasets with complete().
We can plot the imputed dataset number 3 a follows:
Important
Note this imputation method allows incomplete observations to be imputed with more realistic values, rather than just an overall mean or a fitted value coming from simple OLS regression (check purple points on top of the cloud of black points on the right-hand side). Nevertheless, it is not entirely perfect if it does not have enough complete information to impute (check purple points on the left-hand side where we do not have any complete data points in black).
Now, let us estimate an OLS linear regression for each one of the 20 imputed datasets in sampled_flights_imputed_PMM. Our response will be arr_delay subject dep_delay.
We can access to each model separately as follows:
Finally, let us combine the models altogether in a single pooled model.
The estimate column is just the averages of all m models. Full details about the computation on these columns are provided by Rubin (1987) on pages 76 and 77. The columns are explained as follows:
-
estimate: the average of the regression coefficients acrossmmodels. -
ubar: the average variance (i.e., averageSE^2) acrossmmodels. -
b: the sample variance of themregression coefficients. -
t: a final estimate of theSE^2 of each regression coefficient.- =
ubar + (1 + 1/m) * b
- =
-
dfcom: the degrees of freedom associated with the final regression coefficient estimates.- An
alpha-level confidence interval:estimate +/- qt(alpha/2, df) * sqrt(t).
- An
-
riv: the relative increase in variance due to randomness.- =
t/ubar - 1
- =
-
lambda: the proportion of total variance due to missingness. -
fmi: the fraction of missing information.
Where are the usual outputs (std.error, p.value,…)?
We can call summary() on the pooled model to obtain them. The usual coefficient interpretations and inferential rules also apply in this pooled OLS model.
5 Wrapping Up
- Data imputation involves some wrangling effort and proper missingness visualizations.
- We have to be careful when defining our class of data missingness since this will determine the type of data imputation we need to make (or maybe data deletion!).
- In general, multiple imputation will work OK for MAR and MNAR data.
- We only saw continuous imputation in this example. Nonetheless, the
mice()approach can be extended to other data types such as binary or categorical. In those cases, we have to switch to generalized linear models (GLMs), even with a Bayesian approach such as multiple imputation.